 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs via Scalable Interactive Oversight
Feb 04, 2026As Large Language Models increasingly automate complex, long-horizon tasks such as \emph{vibe coding}, a supervision gap has emerged. While models excel at execution, users often struggle to guide them effectively due to insufficient domain expertise, the difficulty of articulating precise intent, and the inability to reliably validate complex outputs. It presents a critical challenge in scalable oversight: enabling humans to responsibly steer AI systems on tasks that surpass their own ability to specify or verify. To tackle this, we propose Scalable Interactive Oversight, a framework that decomposes complex intent into a recursive tree of manageable decisions to amplify human supervision. Rather than relying on open-ended prompting, our system elicits low-burden feedback at each node and recursively aggregates these signals into precise global guidance. Validated in web development task, our framework enables non-experts to produce expert-level Product Requirement Documents, achieving a 54\% improvement in alignment. Crucially, we demonstrate that this framework can be optimized via Reinforcement Learning using only online user feedback, offering a practical pathway for maintaining human control as AI scales.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences
Mar 17, 2025
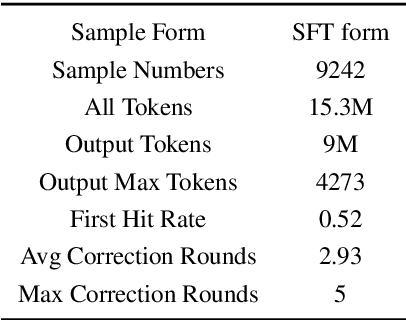
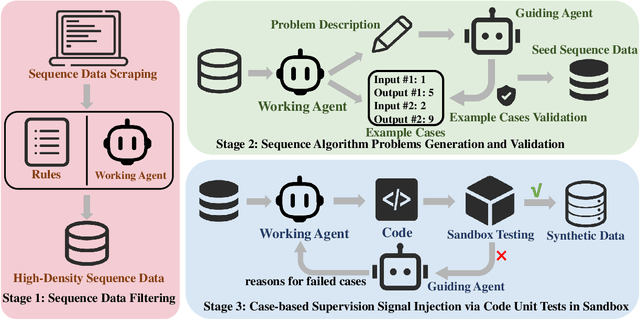

Large language models make remarkable progress in reasoning capabilities. Existing works focus mainly on deductive reasoning tasks (e.g., code and math), while another type of reasoning mode that better aligns with human learning, inductive reasoning, is not well studied. We attribute the reason to the fact that obtaining high-quality process supervision data is challenging for inductive reasoning. Towards this end, we novelly employ number sequences as the source of inductive reasoning data. We package sequences into algorithmic problems to find the general term of each sequence through a code solution. In this way, we can verify whether the code solution holds for any term in the current sequence, and inject case-based supervision signals by using code unit tests. We build a sequence synthetic data pipeline and form a training dataset CodeSeq. Experimental results show that the models tuned with CodeSeq improve on both code and comprehensive reasoning benchmarks.
GAOKAO-Eval: Does high scores truly reflect strong capabilities in LLMs?
Dec 13, 2024Large Language Models (LLMs) are commonly evaluated using human-crafted benchmarks, under the premise that higher scores implicitly reflect stronger human-like performance. However, there is growing concern that LLMs may ``game" these benchmarks due to data leakage, achieving high scores while struggling with tasks simple for humans. To substantively address the problem, we create GAOKAO-Eval, a comprehensive benchmark based on China's National College Entrance Examination (Gaokao), and conduct ``closed-book" evaluations for representative models released prior to Gaokao. Contrary to prevailing consensus, even after addressing data leakage and comprehensiveness, GAOKAO-Eval reveals that high scores still fail to truly reflect human-aligned capabilities. To better understand this mismatch, We introduce the Rasch model from cognitive psychology to analyze LLM scoring patterns and identify two key discrepancies: 1) anomalous consistent performance across various question difficulties, and 2) high variance in performance on questions of similar difficulty. In addition, We identified inconsistent grading of LLM-generated answers among teachers and recurring mistake patterns. we find that the phenomenons are well-grounded in the motivations behind OpenAI o1, and o1's reasoning-as-difficulties can mitigate the mismatch. These results show that GAOKAO-Eval can reveal limitations in LLM capabilities not captured by current benchmarks and highlight the need for more LLM-aligned difficulty analysis.
LongSafetyBench: Long-Context LLMs Struggle with Safety Issues
Nov 11, 2024



With the development of large language models (LLMs), the sequence length of these models continues to increase, drawing significant attention to long-context language models. However, the evaluation of these models has been primarily limited to their capabilities, with a lack of research focusing on their safety. Existing work, such as ManyShotJailbreak, has to some extent demonstrated that long-context language models can exhibit safety concerns. However, the methods used are limited and lack comprehensiveness. In response, we introduce \textbf{LongSafetyBench}, the first benchmark designed to objectively and comprehensively evaluate the safety of long-context models. LongSafetyBench consists of 10 task categories, with an average length of 41,889 words. After testing eight long-context language models on LongSafetyBench, we found that existing models generally exhibit insufficient safety capabilities. The proportion of safe responses from most mainstream long-context LLMs is below 50\%. Moreover, models' safety performance in long-context scenarios does not always align with that in short-context scenarios. Further investigation revealed that long-context models tend to overlook harmful content within lengthy texts. We also proposed a simple yet effective solution, allowing open-source models to achieve performance comparable to that of top-tier closed-source models. We believe that LongSafetyBench can serve as a valuable benchmark for evaluating the safety capabilities of long-context language models. We hope that our work will encourage the broader community to pay attention to the safety of long-context models and contribute to the development of solutions to improve the safety of long-context LLMs.
Boosting Conversational Question Answering with Fine-Grained Retrieval-Augmentation and Self-Check
Mar 27, 2024Retrieval-Augmented Generation (RAG) aims to generate more reliable and accurate responses, by augmenting large language models (LLMs) with the external vast and dynamic knowledge. Most previous work focuses on using RAG for single-round question answering, while how to adapt RAG to the complex conversational setting wherein the question is interdependent on the preceding context is not well studied. In this paper, we propose a conversation-level RAG approach, which incorporates fine-grained retrieval augmentation and self-check for conversational question answering (CQA). In particular, our approach consists of three components, namely conversational question refiner, fine-grained retriever and self-check based response generator, which work collaboratively for question understanding and relevant information acquisition in conversational settings. Extensive experiments demonstrate the great advantages of our approach over the state-of-the-art baselines. Moreover, we also release a Chinese CQA dataset with new features including reformulated question, extracted keyword, retrieved paragraphs and their helpfulness, which facilitates further researches in RAG enhanced CQA.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024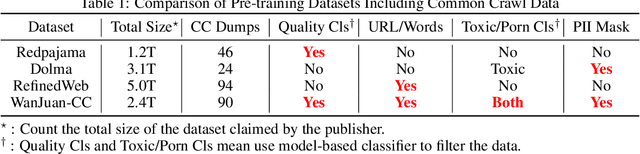
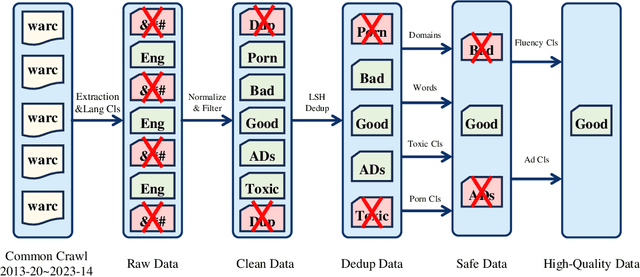
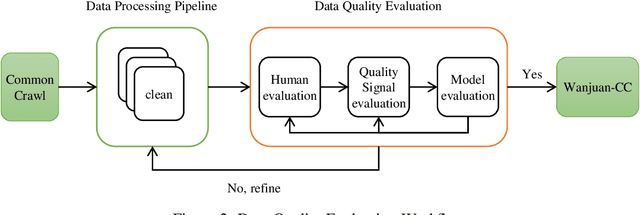

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
AI-Generated Content Enhanced Computer-Aided Diagnosis Model for Thyroid Nodules: A ChatGPT-Style Assistant
Feb 04, 2024An artificial intelligence-generated content-enhanced computer-aided diagnosis (AIGC-CAD) model, designated as ThyGPT, has been developed. This model, inspired by the architecture of ChatGPT, could assist radiologists in assessing the risk of thyroid nodules through semantic-level human-machine interaction. A dataset comprising 19,165 thyroid nodule ultrasound cases from Zhejiang Cancer Hospital was assembled to facilitate the training and validation of the model. After training, ThyGPT could automatically evaluate thyroid nodule and engage in effective communication with physicians through human-computer interaction. The performance of ThyGPT was rigorously quantified using established metrics such as the receiver operating characteristic (ROC) curve, area under the curve (AUC), sensitivity, and specificity. The empirical findings revealed that radiologists, when supplemented with ThyGPT, markedly surpassed the diagnostic acumen of their peers utilizing traditional methods as well as the performance of the model in isolation. These findings suggest that AIGC-CAD systems, exemplified by ThyGPT, hold the promise to fundamentally transform the diagnostic workflows of radiologists in forthcoming years.