 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs via Scalable Interactive Oversight
Feb 04, 2026As Large Language Models increasingly automate complex, long-horizon tasks such as \emph{vibe coding}, a supervision gap has emerged. While models excel at execution, users often struggle to guide them effectively due to insufficient domain expertise, the difficulty of articulating precise intent, and the inability to reliably validate complex outputs. It presents a critical challenge in scalable oversight: enabling humans to responsibly steer AI systems on tasks that surpass their own ability to specify or verify. To tackle this, we propose Scalable Interactive Oversight, a framework that decomposes complex intent into a recursive tree of manageable decisions to amplify human supervision. Rather than relying on open-ended prompting, our system elicits low-burden feedback at each node and recursively aggregates these signals into precise global guidance. Validated in web development task, our framework enables non-experts to produce expert-level Product Requirement Documents, achieving a 54\% improvement in alignment. Crucially, we demonstrate that this framework can be optimized via Reinforcement Learning using only online user feedback, offering a practical pathway for maintaining human control as AI scales.
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025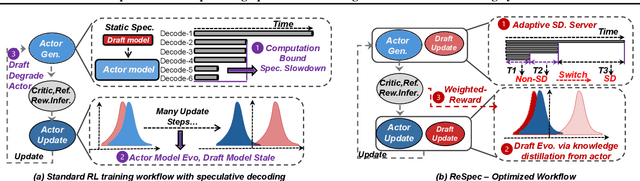

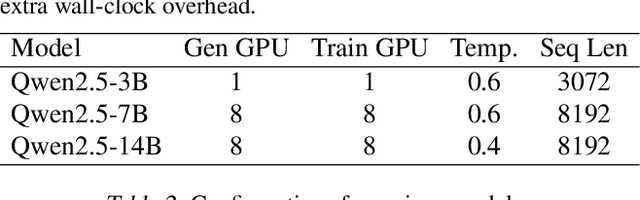

Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Characterization of Large Language Model Development in the Datacenter
Mar 12, 2024Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.