 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlur-Robust Detection via Feature Restoration: An End-to-End Framework for Prior-Guided Infrared UAV Target Detection
Nov 18, 2025Infrared unmanned aerial vehicle (UAV) target images often suffer from motion blur degradation caused by rapid sensor movement, significantly reducing contrast between target and background. Generally, detection performance heavily depends on the discriminative feature representation between target and background. Existing methods typically treat deblurring as a preprocessing step focused on visual quality, while neglecting the enhancement of task-relevant features crucial for detection. Improving feature representation for detection under blur conditions remains challenging. In this paper, we propose a novel Joint Feature-Domain Deblurring and Detection end-to-end framework, dubbed JFD3. We design a dual-branch architecture with shared weights, where the clear branch guides the blurred branch to enhance discriminative feature representation. Specifically, we first introduce a lightweight feature restoration network, where features from the clear branch serve as feature-level supervision to guide the blurred branch, thereby enhancing its distinctive capability for detection. We then propose a frequency structure guidance module that refines the structure prior from the restoration network and integrates it into shallow detection layers to enrich target structural information. Finally, a feature consistency self-supervised loss is imposed between the dual-branch detection backbones, driving the blurred branch to approximate the feature representations of the clear one. Wealso construct a benchmark, named IRBlurUAV, containing 30,000 simulated and 4,118 real infrared UAV target images with diverse motion blur. Extensive experiments on IRBlurUAV demonstrate that JFD3 achieves superior detection performance while maintaining real-time efficiency.
Detection-Friendly Nonuniformity Correction: A Union Framework for Infrared UAVTarget Detection
Apr 05, 2025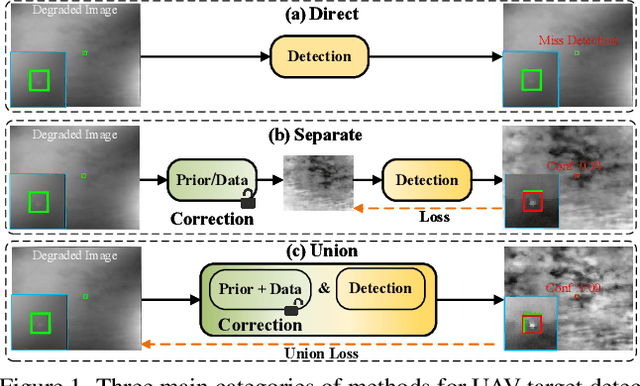



Infrared unmanned aerial vehicle (UAV) images captured using thermal detectors are often affected by temperature dependent low-frequency nonuniformity, which significantly reduces the contrast of the images. Detecting UAV targets under nonuniform conditions is crucial in UAV surveillance applications. Existing methods typically treat infrared nonuniformity correction (NUC) as a preprocessing step for detection, which leads to suboptimal performance. Balancing the two tasks while enhancing detection beneficial information remains challenging. In this paper, we present a detection-friendly union framework, termed UniCD, that simultaneously addresses both infrared NUC and UAV target detection tasks in an end-to-end manner. We first model NUC as a small number of parameter estimation problem jointly driven by priors and data to generate detection-conducive images. Then, we incorporate a new auxiliary loss with target mask supervision into the backbone of the infrared UAV target detection network to strengthen target features while suppressing the background. To better balance correction and detection, we introduce a detection-guided self-supervised loss to reduce feature discrepancies between the two tasks, thereby enhancing detection robustness to varying nonuniformity levels. Additionally, we construct a new benchmark composed of 50,000 infrared images in various nonuniformity types, multi-scale UAV targets and rich backgrounds with target annotations, called IRBFD. Extensive experiments on IRBFD demonstrate that our UniCD is a robust union framework for NUC and UAV target detection while achieving real-time processing capabilities. Dataset can be available at https://github.com/IVPLaboratory/UniCD.
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference
Sep 08, 2024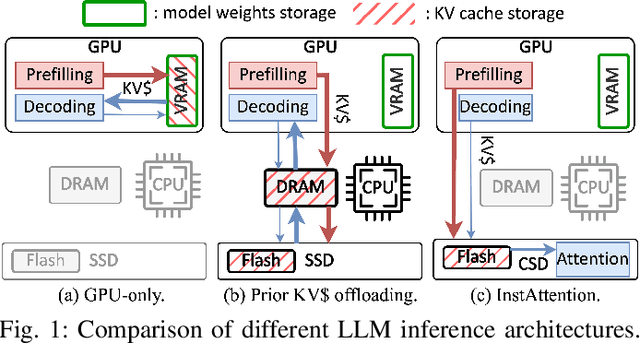

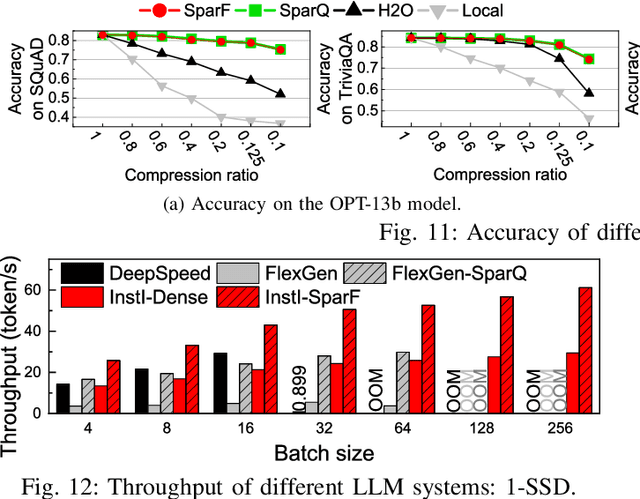
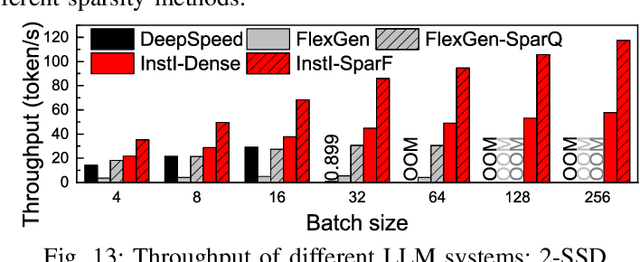
The widespread of Large Language Models (LLMs) marks a significant milestone in generative AI. Nevertheless, the increasing context length and batch size in offline LLM inference escalate the memory requirement of the key-value (KV) cache, which imposes a huge burden on the GPU VRAM, especially for resource-constraint scenarios (e.g., edge computing and personal devices). Several cost-effective solutions leverage host memory or SSDs to reduce storage costs for offline inference scenarios and improve the throughput. Nevertheless, they suffer from significant performance penalties imposed by intensive KV cache accesses due to limited PCIe bandwidth. To address these issues, we propose InstInfer, a novel LLM inference system that offloads the most performance-critical computation (i.e., attention in decoding phase) and data (i.e., KV cache) parts to Computational Storage Drives (CSDs), which minimize the enormous KV transfer overheads. InstInfer designs a dedicated flash-aware in-storage attention engine with KV cache management mechanisms to exploit the high internal bandwidths of CSDs instead of being limited by the PCIe bandwidth. The optimized P2P transmission between GPU and CSDs further reduces data migration overheads. Experimental results demonstrate that for a 13B model using an NVIDIA A6000 GPU, InstInfer improves throughput for long-sequence inference by up to 11.1$\times$, compared to existing SSD-based solutions such as FlexGen.
Characterization of Large Language Model Development in the Datacenter
Mar 12, 2024Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.
Deep Learning Workload Scheduling in GPU Datacenters: Taxonomy, Challenges and Vision
Jun 01, 2022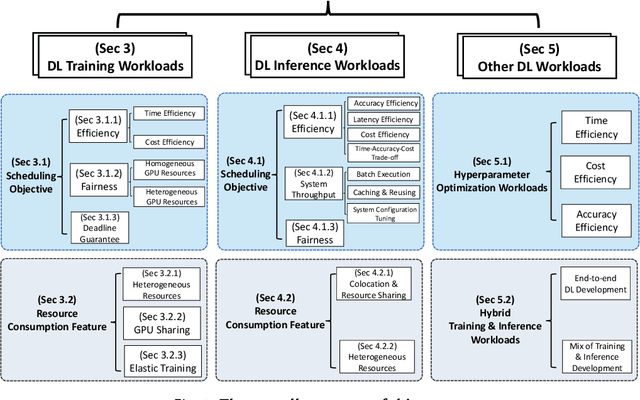
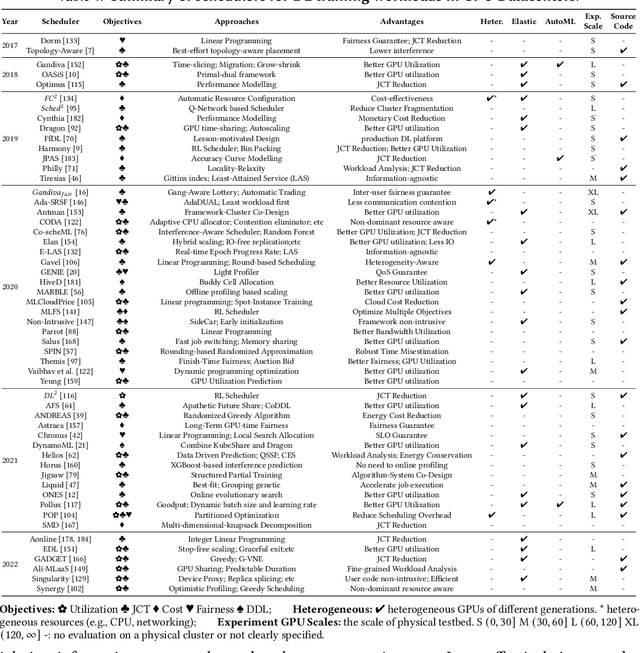
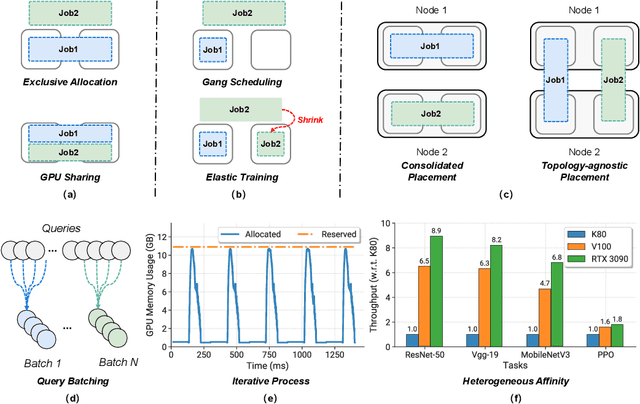

Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions. More detailed summary with the surveyed paper and code links can be found at our project website: https://github.com/S-Lab-System-Group/Awesome-DL-Scheduling-Papers
GRAPHSPY: Fused Program Semantic-Level Embedding via Graph Neural Networks for Dead Store Detection
Nov 18, 2020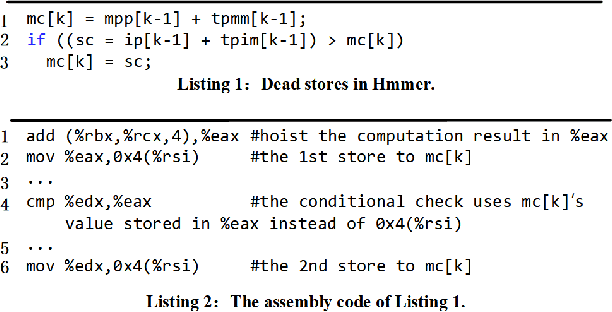
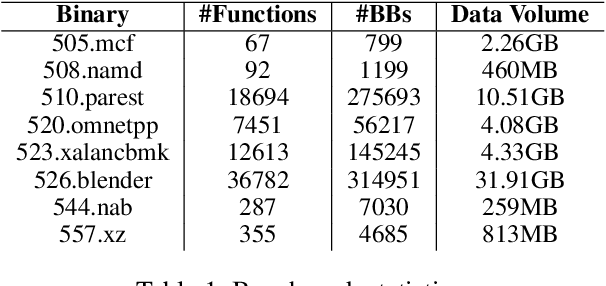
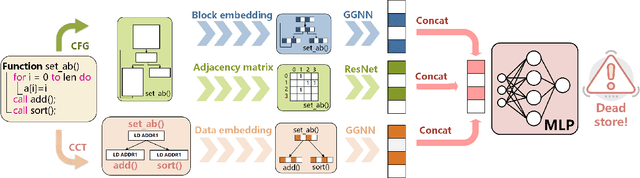
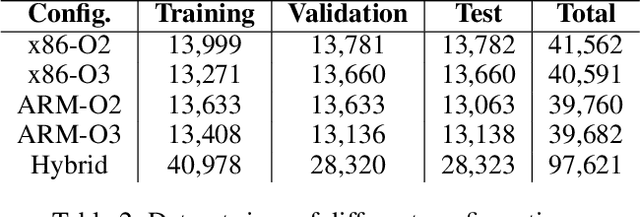
Production software oftentimes suffers from the issue of performance inefficiencies caused by inappropriate use of data structures, programming abstractions, and conservative compiler optimizations. It is desirable to avoid unnecessary memory operations. However, existing works often use a whole-program fine-grained monitoring method with incredibly high overhead. To this end, we propose a learning-aided approach to identify unnecessary memory operations intelligently with low overhead. By applying several prevalent graph neural network models to extract program semantics with respect to program structure, execution order and dynamic states, we present a novel, hybrid program embedding approach so that to derive unnecessary memory operations through the embedding. We train our model with tens of thousands of samples acquired from a set of real-world benchmarks. Results show that our model achieves 90% of accuracy and incurs only around a half of time overhead of the state-of-art tool.
CytonMT: an Efficient Neural Machine Translation Open-source Toolkit Implemented in C++
Jun 02, 2018
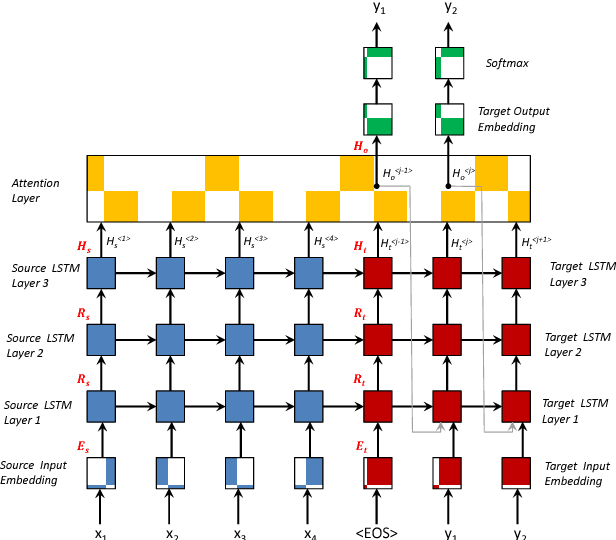


This paper presents an open-source neural machine translation toolkit named CytonMT (https://github.com/arthurxlw/cytonMt). The toolkit is built from scratch only using C++ and NVIDIA's GPU-accelerated libraries. The toolkit features training efficiency, code simplicity and translation quality. Benchmarks show that CytonMT accelerates the training speed by 64.5% to 110.8% on neural networks of various sizes, and achieves competitive translation quality.
CytonRL: an Efficient Reinforcement Learning Open-source Toolkit Implemented in C++
Apr 14, 2018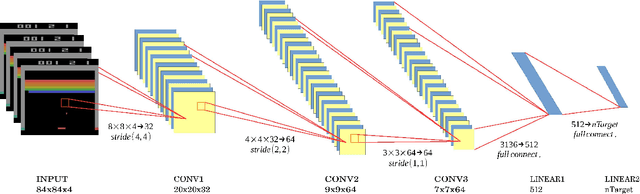
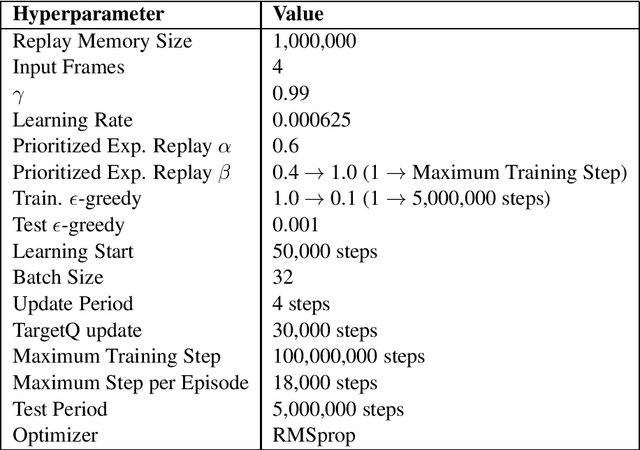


This paper presents an open-source enforcement learning toolkit named CytonRL (https://github.com/arthurxlw/cytonRL). The toolkit implements four recent advanced deep Q-learning algorithms from scratch using C++ and NVIDIA's GPU-accelerated libraries. The code is simple and elegant, owing to an open-source general-purpose neural network library named CytonLib. Benchmark shows that the toolkit achieves competitive performances on the popular Atari game of Breakout.