 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Depth Anything to Adverse Imaging Conditions with Events
Jan 05, 2026Robust depth estimation under dynamic and adverse lighting conditions is essential for robotic systems. Currently, depth foundation models, such as Depth Anything, achieve great success in ideal scenes but remain challenging under adverse imaging conditions such as extreme illumination and motion blur. These degradations corrupt the visual signals of frame cameras, weakening the discriminative features of frame-based depths across the spatial and temporal dimensions. Typically, existing approaches incorporate event cameras to leverage their high dynamic range and temporal resolution, aiming to compensate for corrupted frame features. However, such specialized fusion models are predominantly trained from scratch on domain-specific datasets, thereby failing to inherit the open-world knowledge and robust generalization inherent to foundation models. In this work, we propose ADAE, an event-guided spatiotemporal fusion framework for Depth Anything in degraded scenes. Our design is guided by two key insights: 1) Entropy-Aware Spatial Fusion. We adaptively merge frame-based and event-based features using an information entropy strategy to indicate illumination-induced degradation. 2) Motion-Guided Temporal Correction. We resort to the event-based motion cue to recalibrate ambiguous features in blurred regions. Under our unified framework, the two components are complementary to each other and jointly enhance Depth Anything under adverse imaging conditions. Extensive experiments have been performed to verify the superiority of the proposed method. Our code will be released upon acceptance.
Blur-Robust Detection via Feature Restoration: An End-to-End Framework for Prior-Guided Infrared UAV Target Detection
Nov 18, 2025Infrared unmanned aerial vehicle (UAV) target images often suffer from motion blur degradation caused by rapid sensor movement, significantly reducing contrast between target and background. Generally, detection performance heavily depends on the discriminative feature representation between target and background. Existing methods typically treat deblurring as a preprocessing step focused on visual quality, while neglecting the enhancement of task-relevant features crucial for detection. Improving feature representation for detection under blur conditions remains challenging. In this paper, we propose a novel Joint Feature-Domain Deblurring and Detection end-to-end framework, dubbed JFD3. We design a dual-branch architecture with shared weights, where the clear branch guides the blurred branch to enhance discriminative feature representation. Specifically, we first introduce a lightweight feature restoration network, where features from the clear branch serve as feature-level supervision to guide the blurred branch, thereby enhancing its distinctive capability for detection. We then propose a frequency structure guidance module that refines the structure prior from the restoration network and integrates it into shallow detection layers to enrich target structural information. Finally, a feature consistency self-supervised loss is imposed between the dual-branch detection backbones, driving the blurred branch to approximate the feature representations of the clear one. Wealso construct a benchmark, named IRBlurUAV, containing 30,000 simulated and 4,118 real infrared UAV target images with diverse motion blur. Extensive experiments on IRBlurUAV demonstrate that JFD3 achieves superior detection performance while maintaining real-time efficiency.
Spatio-Temporal Context Learning with Temporal Difference Convolution for Moving Infrared Small Target Detection
Nov 16, 2025



Moving infrared small target detection (IRSTD) plays a critical role in practical applications, such as surveillance of unmanned aerial vehicles (UAVs) and UAV-based search system. Moving IRSTD still remains highly challenging due to weak target features and complex background interference. Accurate spatio-temporal feature modeling is crucial for moving target detection, typically achieved through either temporal differences or spatio-temporal (3D) convolutions. Temporal difference can explicitly leverage motion cues but exhibits limited capability in extracting spatial features, whereas 3D convolution effectively represents spatio-temporal features yet lacks explicit awareness of motion dynamics along the temporal dimension. In this paper, we propose a novel moving IRSTD network (TDCNet), which effectively extracts and enhances spatio-temporal features for accurate target detection. Specifically, we introduce a novel temporal difference convolution (TDC) re-parameterization module that comprises three parallel TDC blocks designed to capture contextual dependencies across different temporal ranges. Each TDC block fuses temporal difference and 3D convolution into a unified spatio-temporal convolution representation. This re-parameterized module can effectively capture multi-scale motion contextual features while suppressing pseudo-motion clutter in complex backgrounds, significantly improving detection performance. Moreover, we propose a TDC-guided spatio-temporal attention mechanism that performs cross-attention between the spatio-temporal features from the TDC-based backbone and a parallel 3D backbone. This mechanism models their global semantic dependencies to refine the current frame's features. Extensive experiments on IRSTD-UAV and public infrared datasets demonstrate that our TDCNet achieves state-of-the-art detection performance in moving target detection.
TimeTracker: Event-based Continuous Point Tracking for Video Frame Interpolation with Non-linear Motion
May 06, 2025Video frame interpolation (VFI) that leverages the bio-inspired event cameras as guidance has recently shown better performance and memory efficiency than the frame-based methods, thanks to the event cameras' advantages, such as high temporal resolution. A hurdle for event-based VFI is how to effectively deal with non-linear motion, caused by the dynamic changes in motion direction and speed within the scene. Existing methods either use events to estimate sparse optical flow or fuse events with image features to estimate dense optical flow. Unfortunately, motion errors often degrade the VFI quality as the continuous motion cues from events do not align with the dense spatial information of images in the temporal dimension. In this paper, we find that object motion is continuous in space, tracking local regions over continuous time enables more accurate identification of spatiotemporal feature correlations. In light of this, we propose a novel continuous point tracking-based VFI framework, named TimeTracker. Specifically, we first design a Scene-Aware Region Segmentation (SARS) module to divide the scene into similar patches. Then, a Continuous Trajectory guided Motion Estimation (CTME) module is proposed to track the continuous motion trajectory of each patch through events. Finally, intermediate frames at any given time are generated through global motion optimization and frame refinement. Moreover, we collect a real-world dataset that features fast non-linear motion. Extensive experiments show that our method outperforms prior arts in both motion estimation and frame interpolation quality.
Detection-Friendly Nonuniformity Correction: A Union Framework for Infrared UAVTarget Detection
Apr 05, 2025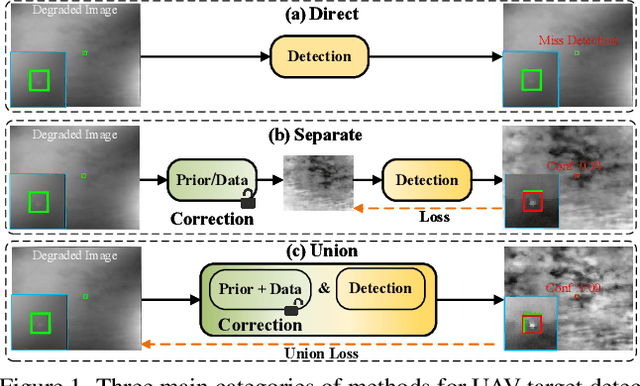



Infrared unmanned aerial vehicle (UAV) images captured using thermal detectors are often affected by temperature dependent low-frequency nonuniformity, which significantly reduces the contrast of the images. Detecting UAV targets under nonuniform conditions is crucial in UAV surveillance applications. Existing methods typically treat infrared nonuniformity correction (NUC) as a preprocessing step for detection, which leads to suboptimal performance. Balancing the two tasks while enhancing detection beneficial information remains challenging. In this paper, we present a detection-friendly union framework, termed UniCD, that simultaneously addresses both infrared NUC and UAV target detection tasks in an end-to-end manner. We first model NUC as a small number of parameter estimation problem jointly driven by priors and data to generate detection-conducive images. Then, we incorporate a new auxiliary loss with target mask supervision into the backbone of the infrared UAV target detection network to strengthen target features while suppressing the background. To better balance correction and detection, we introduce a detection-guided self-supervised loss to reduce feature discrepancies between the two tasks, thereby enhancing detection robustness to varying nonuniformity levels. Additionally, we construct a new benchmark composed of 50,000 infrared images in various nonuniformity types, multi-scale UAV targets and rich backgrounds with target annotations, called IRBFD. Extensive experiments on IRBFD demonstrate that our UniCD is a robust union framework for NUC and UAV target detection while achieving real-time processing capabilities. Dataset can be available at https://github.com/IVPLaboratory/UniCD.
Divide-and-Conquer: Dual-Hierarchical Optimization for Semantic 4D Gaussian Spatting
Mar 25, 2025Semantic 4D Gaussians can be used for reconstructing and understanding dynamic scenes, with temporal variations than static scenes. Directly applying static methods to understand dynamic scenes will fail to capture the temporal features. Few works focus on dynamic scene understanding based on Gaussian Splatting, since once the same update strategy is employed for both dynamic and static parts, regardless of the distinction and interaction between Gaussians, significant artifacts and noise appear. We propose Dual-Hierarchical Optimization (DHO), which consists of Hierarchical Gaussian Flow and Hierarchical Gaussian Guidance in a divide-and-conquer manner. The former implements effective division of static and dynamic rendering and features. The latter helps to mitigate the issue of dynamic foreground rendering distortion in textured complex scenes. Extensive experiments show that our method consistently outperforms the baselines on both synthetic and real-world datasets, and supports various downstream tasks. Project Page: https://sweety-yan.github.io/DHO.
Bridge Frame and Event: Common Spatiotemporal Fusion for High-Dynamic Scene Optical Flow
Mar 11, 2025High-dynamic scene optical flow is a challenging task, which suffers spatial blur and temporal discontinuous motion due to large displacement in frame imaging, thus deteriorating the spatiotemporal feature of optical flow. Typically, existing methods mainly introduce event camera to directly fuse the spatiotemporal features between the two modalities. However, this direct fusion is ineffective, since there exists a large gap due to the heterogeneous data representation between frame and event modalities. To address this issue, we explore a common-latent space as an intermediate bridge to mitigate the modality gap. In this work, we propose a novel common spatiotemporal fusion between frame and event modalities for high-dynamic scene optical flow, including visual boundary localization and motion correlation fusion. Specifically, in visual boundary localization, we figure out that frame and event share the similar spatiotemporal gradients, whose similarity distribution is consistent with the extracted boundary distribution. This motivates us to design the common spatiotemporal gradient to constrain the reference boundary localization. In motion correlation fusion, we discover that the frame-based motion possesses spatially dense but temporally discontinuous correlation, while the event-based motion has spatially sparse but temporally continuous correlation. This inspires us to use the reference boundary to guide the complementary motion knowledge fusion between the two modalities. Moreover, common spatiotemporal fusion can not only relieve the cross-modal feature discrepancy, but also make the fusion process interpretable for dense and continuous optical flow. Extensive experiments have been performed to verify the superiority of the proposed method.
DriveEditor: A Unified 3D Information-Guided Framework for Controllable Object Editing in Driving Scenes
Dec 27, 2024
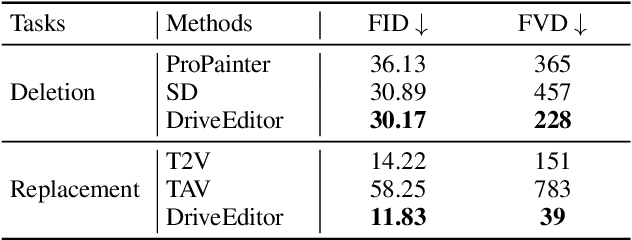
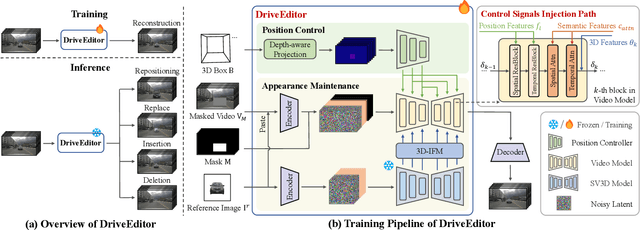
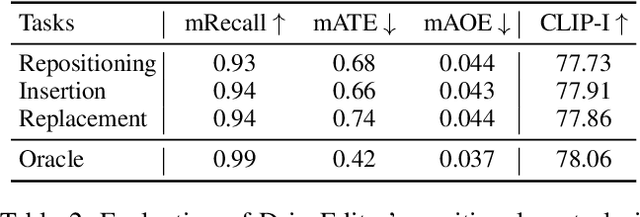
Vision-centric autonomous driving systems require diverse data for robust training and evaluation, which can be augmented by manipulating object positions and appearances within existing scene captures. While recent advancements in diffusion models have shown promise in video editing, their application to object manipulation in driving scenarios remains challenging due to imprecise positional control and difficulties in preserving high-fidelity object appearances. To address these challenges in position and appearance control, we introduce DriveEditor, a diffusion-based framework for object editing in driving videos. DriveEditor offers a unified framework for comprehensive object editing operations, including repositioning, replacement, deletion, and insertion. These diverse manipulations are all achieved through a shared set of varying inputs, processed by identical position control and appearance maintenance modules. The position control module projects the given 3D bounding box while preserving depth information and hierarchically injects it into the diffusion process, enabling precise control over object position and orientation. The appearance maintenance module preserves consistent attributes with a single reference image by employing a three-tiered approach: low-level detail preservation, high-level semantic maintenance, and the integration of 3D priors from a novel view synthesis model. Extensive qualitative and quantitative evaluations on the nuScenes dataset demonstrate DriveEditor's exceptional fidelity and controllability in generating diverse driving scene edits, as well as its remarkable ability to facilitate downstream tasks.
Adverse Weather Optical Flow: Cumulative Homogeneous-Heterogeneous Adaptation
Sep 25, 2024

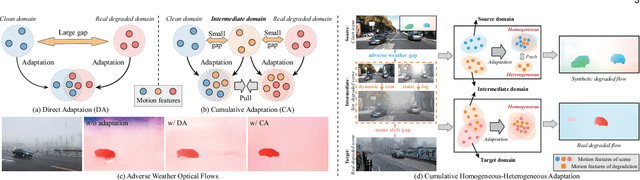

Optical flow has made great progress in clean scenes, while suffers degradation under adverse weather due to the violation of the brightness constancy and gradient continuity assumptions of optical flow. Typically, existing methods mainly adopt domain adaptation to transfer motion knowledge from clean to degraded domain through one-stage adaptation. However, this direct adaptation is ineffective, since there exists a large gap due to adverse weather and scene style between clean and real degraded domains. Moreover, even within the degraded domain itself, static weather (e.g., fog) and dynamic weather (e.g., rain) have different impacts on optical flow. To address above issues, we explore synthetic degraded domain as an intermediate bridge between clean and real degraded domains, and propose a cumulative homogeneous-heterogeneous adaptation framework for real adverse weather optical flow. Specifically, for clean-degraded transfer, our key insight is that static weather possesses the depth-association homogeneous feature which does not change the intrinsic motion of the scene, while dynamic weather additionally introduces the heterogeneous feature which results in a significant boundary discrepancy in warp errors between clean and degraded domains. For synthetic-real transfer, we figure out that cost volume correlation shares a similar statistical histogram between synthetic and real degraded domains, benefiting to holistically aligning the homogeneous correlation distribution for synthetic-real knowledge distillation. Under this unified framework, the proposed method can progressively and explicitly transfer knowledge from clean scenes to real adverse weather. In addition, we further collect a real adverse weather dataset with manually annotated optical flow labels and perform extensive experiments to verify the superiority of the proposed method.
Perceptual-Distortion Balanced Image Super-Resolution is a Multi-Objective Optimization Problem
Sep 05, 2024Training Single-Image Super-Resolution (SISR) models using pixel-based regression losses can achieve high distortion metrics scores (e.g., PSNR and SSIM), but often results in blurry images due to insufficient recovery of high-frequency details. Conversely, using GAN or perceptual losses can produce sharp images with high perceptual metric scores (e.g., LPIPS), but may introduce artifacts and incorrect textures. Balancing these two types of losses can help achieve a trade-off between distortion and perception, but the challenge lies in tuning the loss function weights. To address this issue, we propose a novel method that incorporates Multi-Objective Optimization (MOO) into the training process of SISR models to balance perceptual quality and distortion. We conceptualize the relationship between loss weights and image quality assessment (IQA) metrics as black-box objective functions to be optimized within our Multi-Objective Bayesian Optimization Super-Resolution (MOBOSR) framework. This approach automates the hyperparameter tuning process, reduces overall computational cost, and enables the use of numerous loss functions simultaneously. Extensive experiments demonstrate that MOBOSR outperforms state-of-the-art methods in terms of both perceptual quality and distortion, significantly advancing the perception-distortion Pareto frontier. Our work points towards a new direction for future research on balancing perceptual quality and fidelity in nearly all image restoration tasks. The source code and pretrained models are available at: https://github.com/ZhuKeven/MOBOSR.