 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIDP-Attack: Combining Prompt Injection with Database Poisoning Attacks on Retrieval-Augmented Generation Systems
Mar 26, 2026Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of applications. However, their practical deployment is often hindered by issues such as outdated knowledge and the tendency to generate hallucinations. To address these limitations, Retrieval-Augmented Generation (RAG) systems have been introduced, enhancing LLMs with external, up-to-date knowledge sources. Despite their advantages, RAG systems remain vulnerable to adversarial attacks, with data poisoning emerging as a prominent threat. Existing poisoning-based attacks typically require prior knowledge of the user's specific queries, limiting their flexibility and real-world applicability. In this work, we propose PIDP-Attack, a novel compound attack that integrates prompt injection with database poisoning in RAG. By appending malicious characters to queries at inference time and injecting a limited number of poisoned passages into the retrieval database, our method can effectively manipulate LLM response to arbitrary query without prior knowledge of the user's actual query. Experimental evaluations across three benchmark datasets (Natural Questions, HotpotQA, MS-MARCO) and eight LLMs demonstrate that PIDP-Attack consistently outperforms the original PoisonedRAG. Specifically, our method improves attack success rates by 4% to 16% on open-domain QA tasks while maintaining high retrieval precision, proving that the compound attack strategy is both necessary and highly effective.
High-Quality and Efficient Turbulence Mitigation with Events
Mar 21, 2026Turbulence mitigation (TM) is highly ill-posed due to the stochastic nature of atmospheric turbulence. Most methods rely on multiple frames recorded by conventional cameras to capture stable patterns in natural scenarios. However, they inevitably suffer from a trade-off between accuracy and efficiency: more frames enhance restoration at the cost of higher system latency and larger data overhead. Event cameras, equipped with microsecond temporal resolution and efficient sensing of dynamic changes, offer an opportunity to break the bottleneck. In this work, we present EHETM, a high-quality and efficient TM method inspired by the superiority of events to model motions in continuous sequences. We discover two key phenomena: (1) turbulence-induced events exhibit distinct polarity alternation correlated with sharp image gradients, providing structural cues for restoring scenes; and (2) dynamic objects form spatiotemporally coherent ``event tubes'' in contrast to irregular patterns within turbulent events, providing motion priors for disentangling objects from turbulence. Based on these insights, we design two complementary modules that respectively leverage polarity-weighted gradients for scene refinement and event-tube constraints for motion decoupling, achieving high-quality restoration with few frames. Furthermore, we construct two real-world event-frame turbulence datasets covering atmospheric and thermal cases. Experiments show that EHETM outperforms SOTA methods, especially under scenes with dynamic objects, while reducing data overhead and system latency by approximately 77.3% and 89.5%, respectively. Our code is available at: https://github.com/Xavier667/EHETM.
NEC-Diff: Noise-Robust Event-RAW Complementary Diffusion for Seeing Motion in Extreme Darkness
Mar 20, 2026High-quality imaging of dynamic scenes in extremely low-light conditions is highly challenging. Photon scarcity induces severe noise and texture loss, causing significant image degradation. Event cameras, featuring a high dynamic range (120 dB) and high sensitivity to motion, serve as powerful complements to conventional cameras by offering crucial cues for preserving subtle textures. However, most existing approaches emphasize texture recovery from events, while paying little attention to image noise or the intrinsic noise of events themselves, which ultimately hinders accurate pixel reconstruction under photon-starved conditions. In this work, we propose NEC-Diff, a novel diffusion-based event-RAW hybrid imaging framework that extracts reliable information from heavily noisy signals to reconstruct fine scene structures. The framework is driven by two key insights: (1) combining the linear light-response property of RAW images with the brightness-change nature of events to establish a physics-driven constraint for robust dual-modal denoising; and (2) dynamically estimating the SNR of both modalities based on denoising results to guide adaptive feature fusion, thereby injecting reliable cues into the diffusion process for high-fidelity visual reconstruction. Furthermore, we construct the REAL (Raw and Event Acquired in Low-light) dataset which provides 47,800 pixel-aligned low-light RAW images, events, and high-quality references under 0.001-0.8 lux illumination. Extensive experiments demonstrate the superiority of NEC-Diff under extreme darkness. The project are available at: https://github.com/jinghan-xu/NEC-Diff.
Shape of Thought: Progressive Object Assembly via Visual Chain-of-Thought
Jan 28, 2026Multimodal models for text-to-image generation have achieved strong visual fidelity, yet they remain brittle under compositional structural constraints-notably generative numeracy, attribute binding, and part-level relations. To address these challenges, we propose Shape-of-Thought (SoT), a visual CoT framework that enables progressive shape assembly via coherent 2D projections without external engines at inference time. SoT trains a unified multimodal autoregressive model to generate interleaved textual plans and rendered intermediate states, helping the model capture shape-assembly logic without producing explicit geometric representations. To support this paradigm, we introduce SoT-26K, a large-scale dataset of grounded assembly traces derived from part-based CAD hierarchies, and T2S-CompBench, a benchmark for evaluating structural integrity and trace faithfulness. Fine-tuning on SoT-26K achieves 88.4% on component numeracy and 84.8% on structural topology, outperforming text-only baselines by around 20%. SoT establishes a new paradigm for transparent, process-supervised compositional generation. The code is available at https://anonymous.4open.science/r/16FE/. The SoT-26K dataset will be released upon acceptance.
Adapting Depth Anything to Adverse Imaging Conditions with Events
Jan 05, 2026Robust depth estimation under dynamic and adverse lighting conditions is essential for robotic systems. Currently, depth foundation models, such as Depth Anything, achieve great success in ideal scenes but remain challenging under adverse imaging conditions such as extreme illumination and motion blur. These degradations corrupt the visual signals of frame cameras, weakening the discriminative features of frame-based depths across the spatial and temporal dimensions. Typically, existing approaches incorporate event cameras to leverage their high dynamic range and temporal resolution, aiming to compensate for corrupted frame features. However, such specialized fusion models are predominantly trained from scratch on domain-specific datasets, thereby failing to inherit the open-world knowledge and robust generalization inherent to foundation models. In this work, we propose ADAE, an event-guided spatiotemporal fusion framework for Depth Anything in degraded scenes. Our design is guided by two key insights: 1) Entropy-Aware Spatial Fusion. We adaptively merge frame-based and event-based features using an information entropy strategy to indicate illumination-induced degradation. 2) Motion-Guided Temporal Correction. We resort to the event-based motion cue to recalibrate ambiguous features in blurred regions. Under our unified framework, the two components are complementary to each other and jointly enhance Depth Anything under adverse imaging conditions. Extensive experiments have been performed to verify the superiority of the proposed method. Our code will be released upon acceptance.
TimeTracker: Event-based Continuous Point Tracking for Video Frame Interpolation with Non-linear Motion
May 06, 2025Video frame interpolation (VFI) that leverages the bio-inspired event cameras as guidance has recently shown better performance and memory efficiency than the frame-based methods, thanks to the event cameras' advantages, such as high temporal resolution. A hurdle for event-based VFI is how to effectively deal with non-linear motion, caused by the dynamic changes in motion direction and speed within the scene. Existing methods either use events to estimate sparse optical flow or fuse events with image features to estimate dense optical flow. Unfortunately, motion errors often degrade the VFI quality as the continuous motion cues from events do not align with the dense spatial information of images in the temporal dimension. In this paper, we find that object motion is continuous in space, tracking local regions over continuous time enables more accurate identification of spatiotemporal feature correlations. In light of this, we propose a novel continuous point tracking-based VFI framework, named TimeTracker. Specifically, we first design a Scene-Aware Region Segmentation (SARS) module to divide the scene into similar patches. Then, a Continuous Trajectory guided Motion Estimation (CTME) module is proposed to track the continuous motion trajectory of each patch through events. Finally, intermediate frames at any given time are generated through global motion optimization and frame refinement. Moreover, we collect a real-world dataset that features fast non-linear motion. Extensive experiments show that our method outperforms prior arts in both motion estimation and frame interpolation quality.
Bridge Frame and Event: Common Spatiotemporal Fusion for High-Dynamic Scene Optical Flow
Mar 11, 2025High-dynamic scene optical flow is a challenging task, which suffers spatial blur and temporal discontinuous motion due to large displacement in frame imaging, thus deteriorating the spatiotemporal feature of optical flow. Typically, existing methods mainly introduce event camera to directly fuse the spatiotemporal features between the two modalities. However, this direct fusion is ineffective, since there exists a large gap due to the heterogeneous data representation between frame and event modalities. To address this issue, we explore a common-latent space as an intermediate bridge to mitigate the modality gap. In this work, we propose a novel common spatiotemporal fusion between frame and event modalities for high-dynamic scene optical flow, including visual boundary localization and motion correlation fusion. Specifically, in visual boundary localization, we figure out that frame and event share the similar spatiotemporal gradients, whose similarity distribution is consistent with the extracted boundary distribution. This motivates us to design the common spatiotemporal gradient to constrain the reference boundary localization. In motion correlation fusion, we discover that the frame-based motion possesses spatially dense but temporally discontinuous correlation, while the event-based motion has spatially sparse but temporally continuous correlation. This inspires us to use the reference boundary to guide the complementary motion knowledge fusion between the two modalities. Moreover, common spatiotemporal fusion can not only relieve the cross-modal feature discrepancy, but also make the fusion process interpretable for dense and continuous optical flow. Extensive experiments have been performed to verify the superiority of the proposed method.
CoSEC: A Coaxial Stereo Event Camera Dataset for Autonomous Driving
Aug 16, 2024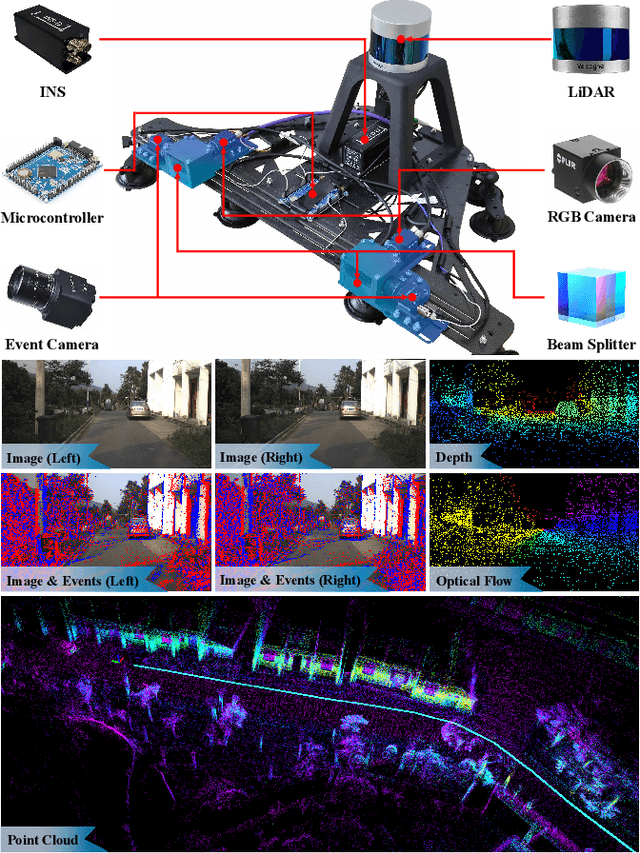
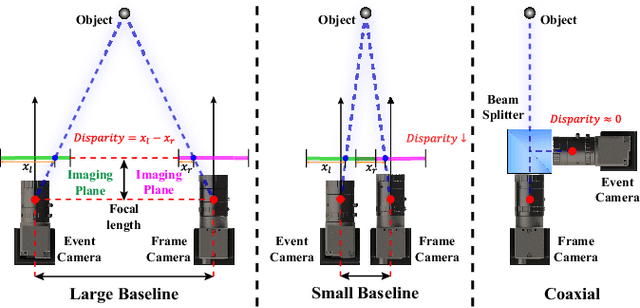
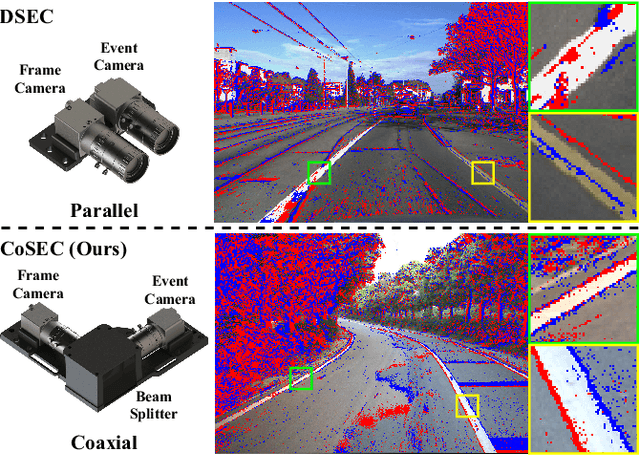
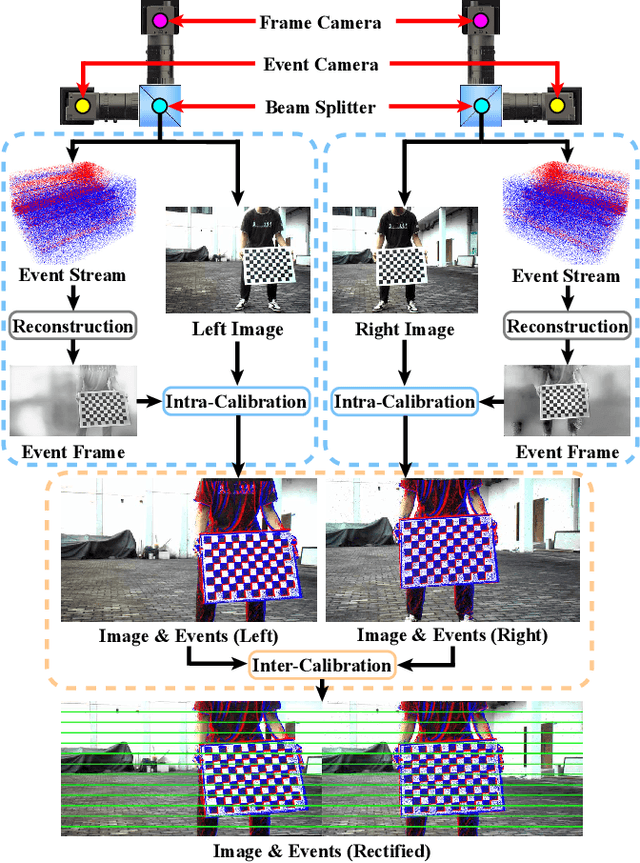
Conventional frame camera is the mainstream sensor of the autonomous driving scene perception, while it is limited in adverse conditions, such as low light. Event camera with high dynamic range has been applied in assisting frame camera for the multimodal fusion, which relies heavily on the pixel-level spatial alignment between various modalities. Typically, existing multimodal datasets mainly place event and frame cameras in parallel and directly align them spatially via warping operation. However, this parallel strategy is less effective for multimodal fusion, since the large disparity exacerbates spatial misalignment due to the large event-frame baseline. We argue that baseline minimization can reduce alignment error between event and frame cameras. In this work, we introduce hybrid coaxial event-frame devices to build the multimodal system, and propose a coaxial stereo event camera (CoSEC) dataset for autonomous driving. As for the multimodal system, we first utilize the microcontroller to achieve time synchronization, and then spatially calibrate different sensors, where we perform intra- and inter-calibration of stereo coaxial devices. As for the multimodal dataset, we filter LiDAR point clouds to generate depth and optical flow labels using reference depth, which is further improved by fusing aligned event and frame data in nighttime conditions. With the help of the coaxial device, the proposed dataset can promote the all-day pixel-level multimodal fusion. Moreover, we also conduct experiments to demonstrate that the proposed dataset can improve the performance and generalization of the multimodal fusion.
Seeing Motion at Nighttime with an Event Camera
Apr 18, 2024



We focus on a very challenging task: imaging at nighttime dynamic scenes. Most previous methods rely on the low-light enhancement of a conventional RGB camera. However, they would inevitably face a dilemma between the long exposure time of nighttime and the motion blur of dynamic scenes. Event cameras react to dynamic changes with higher temporal resolution (microsecond) and higher dynamic range (120dB), offering an alternative solution. In this work, we present a novel nighttime dynamic imaging method with an event camera. Specifically, we discover that the event at nighttime exhibits temporal trailing characteristics and spatial non-stationary distribution. Consequently, we propose a nighttime event reconstruction network (NER-Net) which mainly includes a learnable event timestamps calibration module (LETC) to align the temporal trailing events and a non-uniform illumination aware module (NIAM) to stabilize the spatiotemporal distribution of events. Moreover, we construct a paired real low-light event dataset (RLED) through a co-axial imaging system, including 64,200 spatially and temporally aligned image GTs and low-light events. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art methods in terms of visual quality and generalization ability on real-world nighttime datasets. The project are available at: https://github.com/Liu-haoyue/NER-Net.
Exploring the Common Appearance-Boundary Adaptation for Nighttime Optical Flow
Jan 31, 2024



We investigate a challenging task of nighttime optical flow, which suffers from weakened texture and amplified noise. These degradations weaken discriminative visual features, thus causing invalid motion feature matching. Typically, existing methods employ domain adaptation to transfer knowledge from auxiliary domain to nighttime domain in either input visual space or output motion space. However, this direct adaptation is ineffective, since there exists a large domain gap due to the intrinsic heterogeneous nature of the feature representations between auxiliary and nighttime domains. To overcome this issue, we explore a common-latent space as the intermediate bridge to reinforce the feature alignment between auxiliary and nighttime domains. In this work, we exploit two auxiliary daytime and event domains, and propose a novel common appearance-boundary adaptation framework for nighttime optical flow. In appearance adaptation, we employ the intrinsic image decomposition to embed the auxiliary daytime image and the nighttime image into a reflectance-aligned common space. We discover that motion distributions of the two reflectance maps are very similar, benefiting us to consistently transfer motion appearance knowledge from daytime to nighttime domain. In boundary adaptation, we theoretically derive the motion correlation formula between nighttime image and accumulated events within a spatiotemporal gradient-aligned common space. We figure out that the correlation of the two spatiotemporal gradient maps shares significant discrepancy, benefitting us to contrastively transfer boundary knowledge from event to nighttime domain. Moreover, appearance adaptation and boundary adaptation are complementary to each other, since they could jointly transfer global motion and local boundary knowledge to the nighttime domain.