 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Depth Anything to Adverse Imaging Conditions with Events
Jan 05, 2026Robust depth estimation under dynamic and adverse lighting conditions is essential for robotic systems. Currently, depth foundation models, such as Depth Anything, achieve great success in ideal scenes but remain challenging under adverse imaging conditions such as extreme illumination and motion blur. These degradations corrupt the visual signals of frame cameras, weakening the discriminative features of frame-based depths across the spatial and temporal dimensions. Typically, existing approaches incorporate event cameras to leverage their high dynamic range and temporal resolution, aiming to compensate for corrupted frame features. However, such specialized fusion models are predominantly trained from scratch on domain-specific datasets, thereby failing to inherit the open-world knowledge and robust generalization inherent to foundation models. In this work, we propose ADAE, an event-guided spatiotemporal fusion framework for Depth Anything in degraded scenes. Our design is guided by two key insights: 1) Entropy-Aware Spatial Fusion. We adaptively merge frame-based and event-based features using an information entropy strategy to indicate illumination-induced degradation. 2) Motion-Guided Temporal Correction. We resort to the event-based motion cue to recalibrate ambiguous features in blurred regions. Under our unified framework, the two components are complementary to each other and jointly enhance Depth Anything under adverse imaging conditions. Extensive experiments have been performed to verify the superiority of the proposed method. Our code will be released upon acceptance.
Integrating Learning-Based Manipulation and Physics-Based Locomotion for Whole-Body Badminton Robot Control
Apr 24, 2025Learning-based methods, such as imitation learning (IL) and reinforcement learning (RL), can produce excel control policies over challenging agile robot tasks, such as sports robot. However, no existing work has harmonized learning-based policy with model-based methods to reduce training complexity and ensure the safety and stability for agile badminton robot control. In this paper, we introduce \ourmethod, a novel hybrid control system for agile badminton robots. Specifically, we propose a model-based strategy for chassis locomotion which provides a base for arm policy. We introduce a physics-informed ``IL+RL'' training framework for learning-based arm policy. In this train framework, a model-based strategy with privileged information is used to guide arm policy training during both IL and RL phases. In addition, we train the critic model during IL phase to alleviate the performance drop issue when transitioning from IL to RL. We present results on our self-engineered badminton robot, achieving 94.5% success rate against the serving machine and 90.7% success rate against human players. Our system can be easily generalized to other agile mobile manipulation tasks such as agile catching and table tennis. Our project website: https://dreamstarring.github.io/HAMLET/.
A Universal Model Combining Differential Equations and Neural Networks for Ball Trajectory Prediction
Mar 25, 2025This paper presents a data driven universal ball trajectory prediction method integrated with physics equations. Existing methods are designed for specific ball types and struggle to generalize. This challenge arises from three key factors. First, learning-based models require large datasets but suffer from accuracy drops in unseen scenarios. Second, physics-based models rely on complex formulas and detailed inputs, yet accurately obtaining ball states, such as spin, is often impractical. Third, integrating physical principles with neural networks to achieve high accuracy, fast inference, and strong generalization remains difficult. To address these issues, we propose an innovative approach that incorporates physics-based equations and neural networks. We first derive three generalized physical formulas. Then, using a neural network and observed trajectory points, we infer certain parameters while fitting the remaining ones. These formulas enable precise trajectory prediction with minimal training data: only a few dozen samples. Extensive experiments demonstrate our method superiority in generalization, real-time performance, and accuracy.
YO-CSA-T: A Real-time Badminton Tracking System Utilizing YOLO Based on Contextual and Spatial Attention
Jan 11, 2025



The 3D trajectory of a shuttlecock required for a badminton rally robot for human-robot competition demands real-time performance with high accuracy. However, the fast flight speed of the shuttlecock, along with various visual effects, and its tendency to blend with environmental elements, such as court lines and lighting, present challenges for rapid and accurate 2D detection. In this paper, we first propose the YO-CSA detection network, which optimizes and reconfigures the YOLOv8s model's backbone, neck, and head by incorporating contextual and spatial attention mechanisms to enhance model's ability in extracting and integrating both global and local features. Next, we integrate three major subtasks, detection, prediction, and compensation, into a real-time 3D shuttlecock trajectory detection system. Specifically, our system maps the 2D coordinate sequence extracted by YO-CSA into 3D space using stereo vision, then predicts the future 3D coordinates based on historical information, and re-projects them onto the left and right views to update the position constraints for 2D detection. Additionally, our system includes a compensation module to fill in missing intermediate frames, ensuring a more complete trajectory. We conduct extensive experiments on our own dataset to evaluate both YO-CSA's performance and system effectiveness. Experimental results show that YO-CSA achieves a high accuracy of 90.43% mAP@0.75, surpassing both YOLOv8s and YOLO11s. Our system performs excellently, maintaining a speed of over 130 fps across 12 test sequences.
Adverse Weather Optical Flow: Cumulative Homogeneous-Heterogeneous Adaptation
Sep 25, 2024

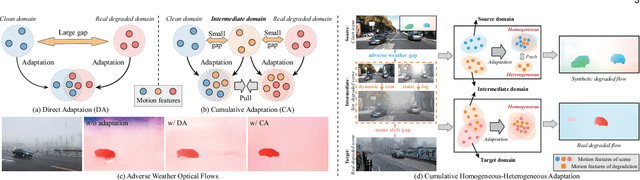

Optical flow has made great progress in clean scenes, while suffers degradation under adverse weather due to the violation of the brightness constancy and gradient continuity assumptions of optical flow. Typically, existing methods mainly adopt domain adaptation to transfer motion knowledge from clean to degraded domain through one-stage adaptation. However, this direct adaptation is ineffective, since there exists a large gap due to adverse weather and scene style between clean and real degraded domains. Moreover, even within the degraded domain itself, static weather (e.g., fog) and dynamic weather (e.g., rain) have different impacts on optical flow. To address above issues, we explore synthetic degraded domain as an intermediate bridge between clean and real degraded domains, and propose a cumulative homogeneous-heterogeneous adaptation framework for real adverse weather optical flow. Specifically, for clean-degraded transfer, our key insight is that static weather possesses the depth-association homogeneous feature which does not change the intrinsic motion of the scene, while dynamic weather additionally introduces the heterogeneous feature which results in a significant boundary discrepancy in warp errors between clean and degraded domains. For synthetic-real transfer, we figure out that cost volume correlation shares a similar statistical histogram between synthetic and real degraded domains, benefiting to holistically aligning the homogeneous correlation distribution for synthetic-real knowledge distillation. Under this unified framework, the proposed method can progressively and explicitly transfer knowledge from clean scenes to real adverse weather. In addition, we further collect a real adverse weather dataset with manually annotated optical flow labels and perform extensive experiments to verify the superiority of the proposed method.
CoSEC: A Coaxial Stereo Event Camera Dataset for Autonomous Driving
Aug 16, 2024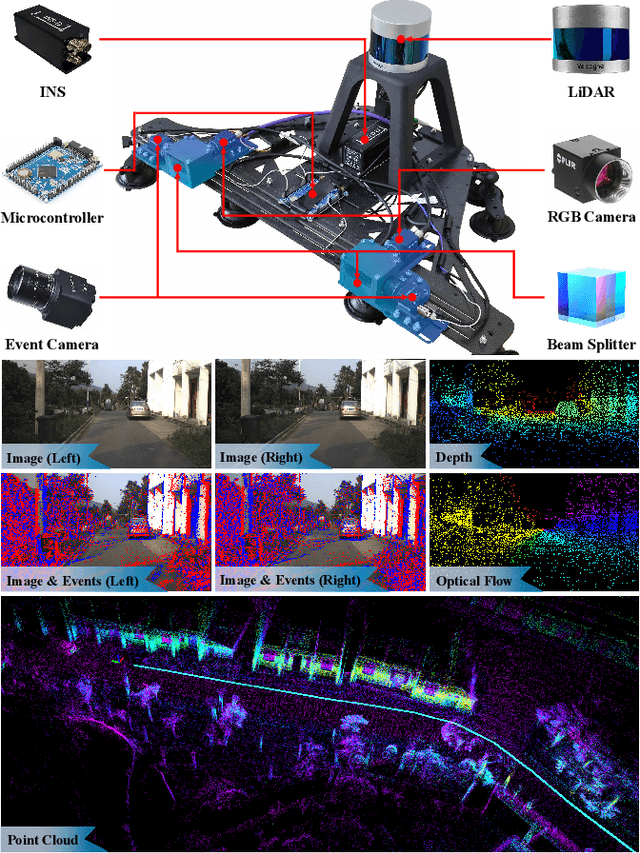
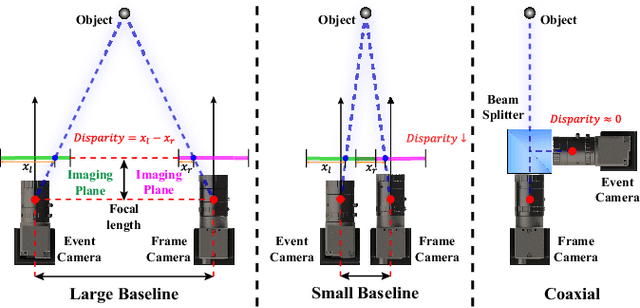
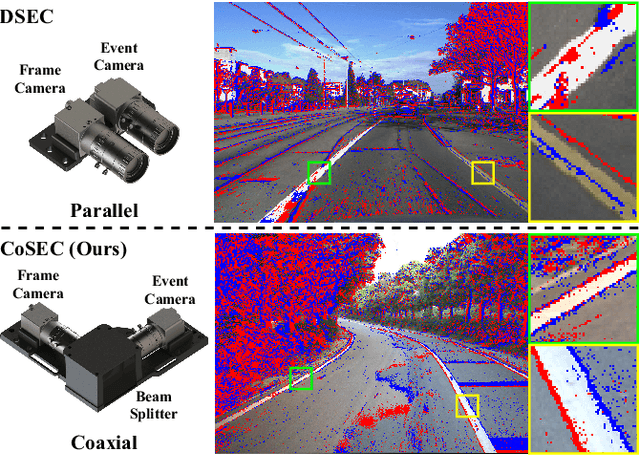
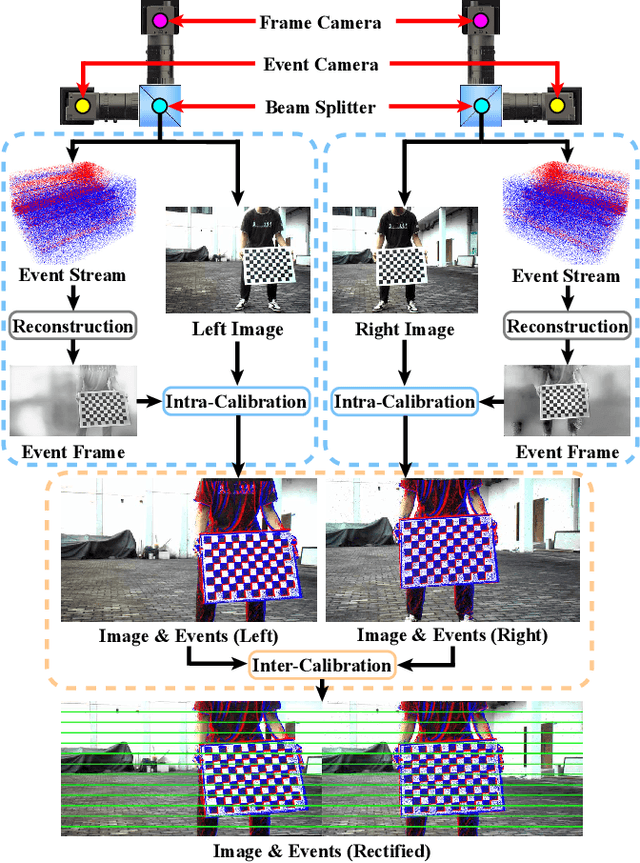
Conventional frame camera is the mainstream sensor of the autonomous driving scene perception, while it is limited in adverse conditions, such as low light. Event camera with high dynamic range has been applied in assisting frame camera for the multimodal fusion, which relies heavily on the pixel-level spatial alignment between various modalities. Typically, existing multimodal datasets mainly place event and frame cameras in parallel and directly align them spatially via warping operation. However, this parallel strategy is less effective for multimodal fusion, since the large disparity exacerbates spatial misalignment due to the large event-frame baseline. We argue that baseline minimization can reduce alignment error between event and frame cameras. In this work, we introduce hybrid coaxial event-frame devices to build the multimodal system, and propose a coaxial stereo event camera (CoSEC) dataset for autonomous driving. As for the multimodal system, we first utilize the microcontroller to achieve time synchronization, and then spatially calibrate different sensors, where we perform intra- and inter-calibration of stereo coaxial devices. As for the multimodal dataset, we filter LiDAR point clouds to generate depth and optical flow labels using reference depth, which is further improved by fusing aligned event and frame data in nighttime conditions. With the help of the coaxial device, the proposed dataset can promote the all-day pixel-level multimodal fusion. Moreover, we also conduct experiments to demonstrate that the proposed dataset can improve the performance and generalization of the multimodal fusion.
JSTR: Joint Spatio-Temporal Reasoning for Event-based Moving Object Detection
Mar 12, 2024



Event-based moving object detection is a challenging task, where static background and moving object are mixed together. Typically, existing methods mainly align the background events to the same spatial coordinate system via motion compensation to distinguish the moving object. However, they neglect the potential spatial tailing effect of moving object events caused by excessive motion, which may affect the structure integrity of the extracted moving object. We discover that the moving object has a complete columnar structure in the point cloud composed of motion-compensated events along the timestamp. Motivated by this, we propose a novel joint spatio-temporal reasoning method for event-based moving object detection. Specifically, we first compensate the motion of background events using inertial measurement unit. In spatial reasoning stage, we project the compensated events into the same image coordinate, discretize the timestamp of events to obtain a time image that can reflect the motion confidence, and further segment the moving object through adaptive threshold on the time image. In temporal reasoning stage, we construct the events into a point cloud along timestamp, and use RANSAC algorithm to extract the columnar shape in the cloud for peeling off the background. Finally, we fuse the results from the two reasoning stages to extract the final moving object region. This joint spatio-temporal reasoning framework can effectively detect the moving object from motion confidence and geometric structure. Moreover, we conduct extensive experiments on various datasets to verify that the proposed method can improve the moving object detection accuracy by 13\%.
Bring Event into RGB and LiDAR: Hierarchical Visual-Motion Fusion for Scene Flow
Mar 12, 2024



Single RGB or LiDAR is the mainstream sensor for the challenging scene flow, which relies heavily on visual features to match motion features. Compared with single modality, existing methods adopt a fusion strategy to directly fuse the cross-modal complementary knowledge in motion space. However, these direct fusion methods may suffer the modality gap due to the visual intrinsic heterogeneous nature between RGB and LiDAR, thus deteriorating motion features. We discover that event has the homogeneous nature with RGB and LiDAR in both visual and motion spaces. In this work, we bring the event as a bridge between RGB and LiDAR, and propose a novel hierarchical visual-motion fusion framework for scene flow, which explores a homogeneous space to fuse the cross-modal complementary knowledge for physical interpretation. In visual fusion, we discover that event has a complementarity (relative v.s. absolute) in luminance space with RGB for high dynamic imaging, and has a complementarity (local boundary v.s. global shape) in scene structure space with LiDAR for structure integrity. In motion fusion, we figure out that RGB, event and LiDAR are complementary (spatial-dense, temporal-dense v.s. spatiotemporal-sparse) to each other in correlation space, which motivates us to fuse their motion correlations for motion continuity. The proposed hierarchical fusion can explicitly fuse the multimodal knowledge to progressively improve scene flow from visual space to motion space. Extensive experiments have been performed to verify the superiority of the proposed method.
Exploring the Common Appearance-Boundary Adaptation for Nighttime Optical Flow
Jan 31, 2024



We investigate a challenging task of nighttime optical flow, which suffers from weakened texture and amplified noise. These degradations weaken discriminative visual features, thus causing invalid motion feature matching. Typically, existing methods employ domain adaptation to transfer knowledge from auxiliary domain to nighttime domain in either input visual space or output motion space. However, this direct adaptation is ineffective, since there exists a large domain gap due to the intrinsic heterogeneous nature of the feature representations between auxiliary and nighttime domains. To overcome this issue, we explore a common-latent space as the intermediate bridge to reinforce the feature alignment between auxiliary and nighttime domains. In this work, we exploit two auxiliary daytime and event domains, and propose a novel common appearance-boundary adaptation framework for nighttime optical flow. In appearance adaptation, we employ the intrinsic image decomposition to embed the auxiliary daytime image and the nighttime image into a reflectance-aligned common space. We discover that motion distributions of the two reflectance maps are very similar, benefiting us to consistently transfer motion appearance knowledge from daytime to nighttime domain. In boundary adaptation, we theoretically derive the motion correlation formula between nighttime image and accumulated events within a spatiotemporal gradient-aligned common space. We figure out that the correlation of the two spatiotemporal gradient maps shares significant discrepancy, benefitting us to contrastively transfer boundary knowledge from event to nighttime domain. Moreover, appearance adaptation and boundary adaptation are complementary to each other, since they could jointly transfer global motion and local boundary knowledge to the nighttime domain.