 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Learning-Based Manipulation and Physics-Based Locomotion for Whole-Body Badminton Robot Control
Apr 24, 2025Learning-based methods, such as imitation learning (IL) and reinforcement learning (RL), can produce excel control policies over challenging agile robot tasks, such as sports robot. However, no existing work has harmonized learning-based policy with model-based methods to reduce training complexity and ensure the safety and stability for agile badminton robot control. In this paper, we introduce \ourmethod, a novel hybrid control system for agile badminton robots. Specifically, we propose a model-based strategy for chassis locomotion which provides a base for arm policy. We introduce a physics-informed ``IL+RL'' training framework for learning-based arm policy. In this train framework, a model-based strategy with privileged information is used to guide arm policy training during both IL and RL phases. In addition, we train the critic model during IL phase to alleviate the performance drop issue when transitioning from IL to RL. We present results on our self-engineered badminton robot, achieving 94.5% success rate against the serving machine and 90.7% success rate against human players. Our system can be easily generalized to other agile mobile manipulation tasks such as agile catching and table tennis. Our project website: https://dreamstarring.github.io/HAMLET/.
Discovering the Unknown Knowns: Turning Implicit Knowledge in the Dataset into Explicit Training Examples for Visual Question Answering
Sep 13, 2021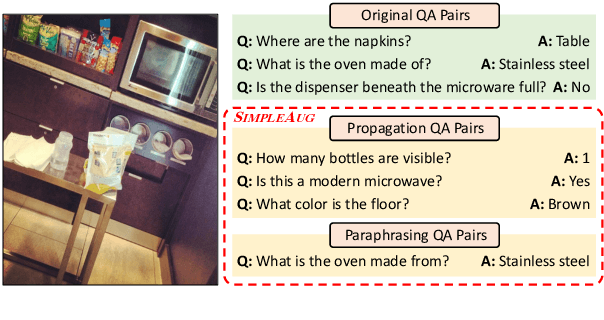

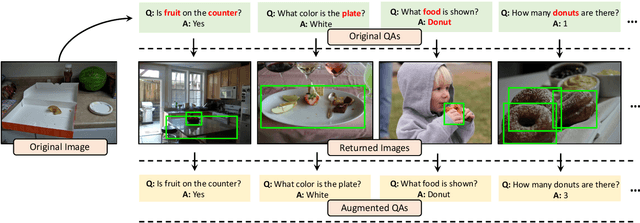
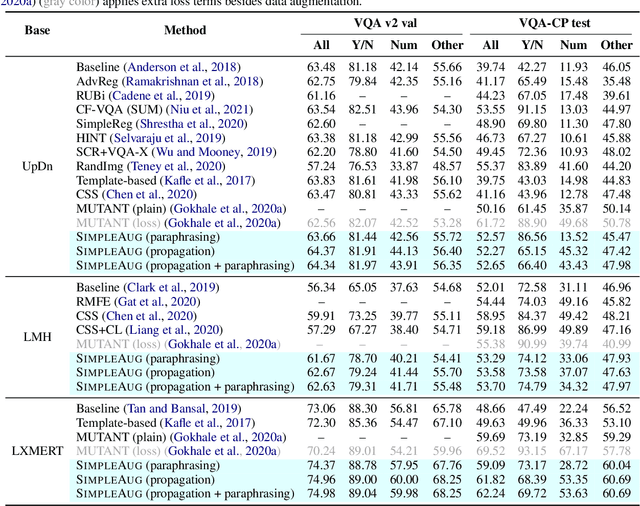
Visual question answering (VQA) is challenging not only because the model has to handle multi-modal information, but also because it is just so hard to collect sufficient training examples -- there are too many questions one can ask about an image. As a result, a VQA model trained solely on human-annotated examples could easily over-fit specific question styles or image contents that are being asked, leaving the model largely ignorant about the sheer diversity of questions. Existing methods address this issue primarily by introducing an auxiliary task such as visual grounding, cycle consistency, or debiasing. In this paper, we take a drastically different approach. We found that many of the "unknowns" to the learned VQA model are indeed "known" in the dataset implicitly. For instance, questions asking about the same object in different images are likely paraphrases; the number of detected or annotated objects in an image already provides the answer to the "how many" question, even if the question has not been annotated for that image. Building upon these insights, we present a simple data augmentation pipeline SimpleAug to turn this "known" knowledge into training examples for VQA. We show that these augmented examples can notably improve the learned VQA models' performance, not only on the VQA-CP dataset with language prior shifts but also on the VQA v2 dataset without such shifts. Our method further opens up the door to leverage weakly-labeled or unlabeled images in a principled way to enhance VQA models. Our code and data are publicly available at https://github.com/heendung/simpleAUG.
On Model Calibration for Long-Tailed Object Detection and Instance Segmentation
Jul 05, 2021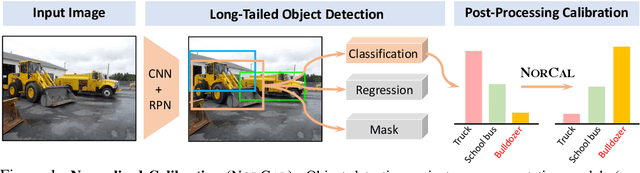
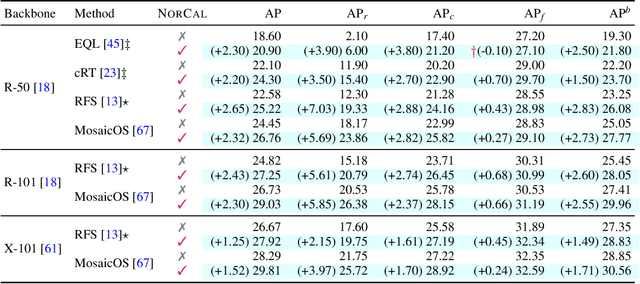
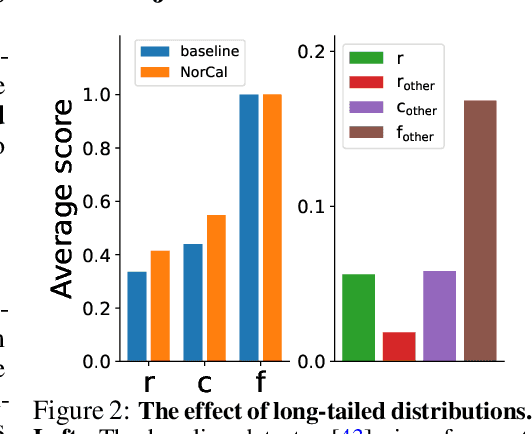

Vanilla models for object detection and instance segmentation suffer from the heavy bias toward detecting frequent objects in the long-tailed setting. Existing methods address this issue mostly during training, e.g., by re-sampling or re-weighting. In this paper, we investigate a largely overlooked approach -- post-processing calibration of confidence scores. We propose NorCal, Normalized Calibration for long-tailed object detection and instance segmentation, a simple and straightforward recipe that reweighs the predicted scores of each class by its training sample size. We show that separately handling the background class and normalizing the scores over classes for each proposal are keys to achieving superior performance. On the LVIS dataset, NorCal can effectively improve nearly all the baseline models not only on rare classes but also on common and frequent classes. Finally, we conduct extensive analysis and ablation studies to offer insights into various modeling choices and mechanisms of our approach.
A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Feb 17, 2021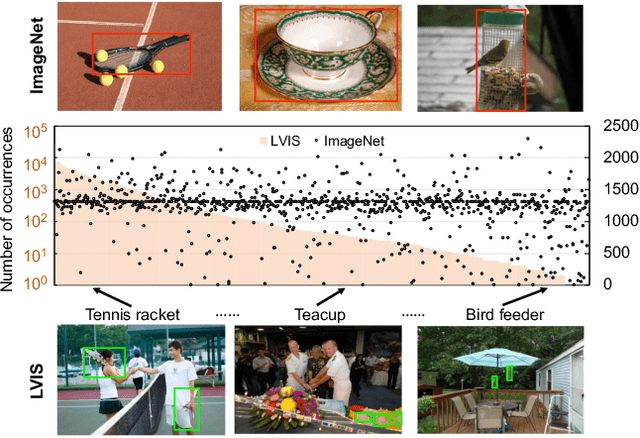
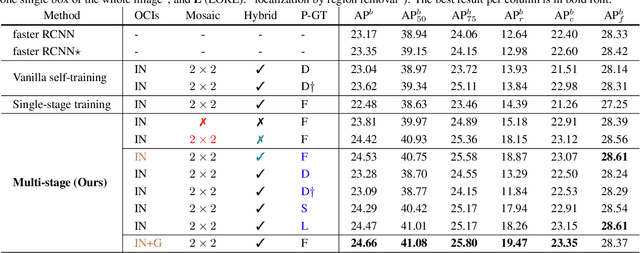

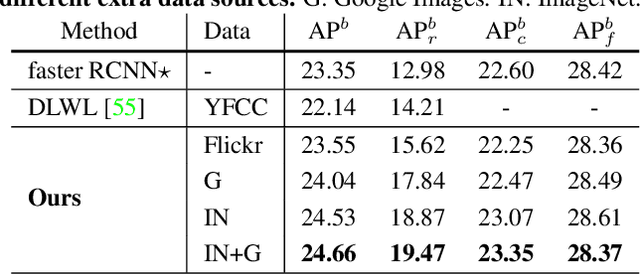
Object frequencies in daily scenes follow a long-tailed distribution. Many objects do not appear frequently enough in scene-centric images (e.g., sightseeing, street views) for us to train accurate object detectors. In contrast, these objects are captured at a higher frequency in object-centric images, which are intended to picture the objects of interest. Motivated by this phenomenon, we propose to take advantage of the object-centric images to improve object detection in scene-centric images. We present a simple yet surprisingly effective framework to do so. On the one hand, our approach turns an object-centric image into a useful training example for object detection in scene-centric images by mitigating the domain gap between the two image sources in both the input and label space. On the other hand, our approach employs a multi-stage procedure to train the object detector, such that the detector learns the diverse object appearances from object-centric images while being tied to the application domain of scene-centric images. On the LVIS dataset, our approach can improve the object detection (and instance segmentation) accuracy of rare objects by 50% (and 33%) relatively, without sacrificing the performance of other classes.
An Empirical Study on Leveraging Scene Graphs for Visual Question Answering
Jul 28, 2019

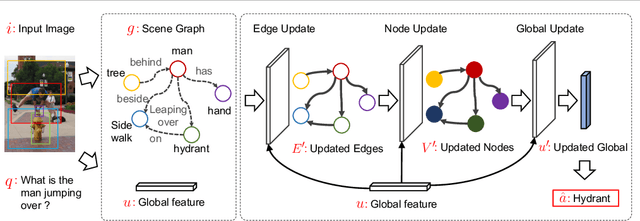

Visual question answering (Visual QA) has attracted significant attention these years. While a variety of algorithms have been proposed, most of them are built upon different combinations of image and language features as well as multi-modal attention and fusion. In this paper, we investigate an alternative approach inspired by conventional QA systems that operate on knowledge graphs. Specifically, we investigate the use of scene graphs derived from images for Visual QA: an image is abstractly represented by a graph with nodes corresponding to object entities and edges to object relationships. We adapt the recently proposed graph network (GN) to encode the scene graph and perform structured reasoning according to the input question. Our empirical studies demonstrate that scene graphs can already capture essential information of images and graph networks have the potential to outperform state-of-the-art Visual QA algorithms but with a much cleaner architecture. By analyzing the features generated by GNs we can further interpret the reasoning process, suggesting a promising direction towards explainable Visual QA.
Crowd-ML: A Privacy-Preserving Learning Framework for a Crowd of Smart Devices
Jan 11, 2015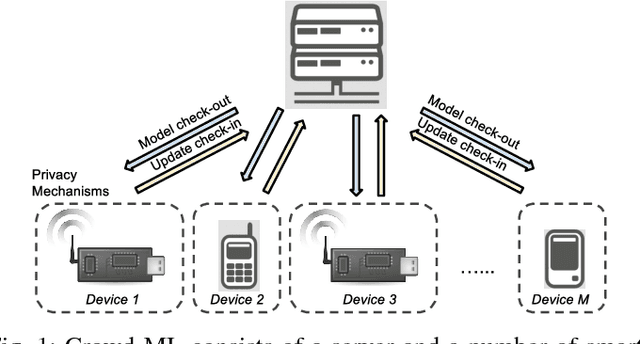
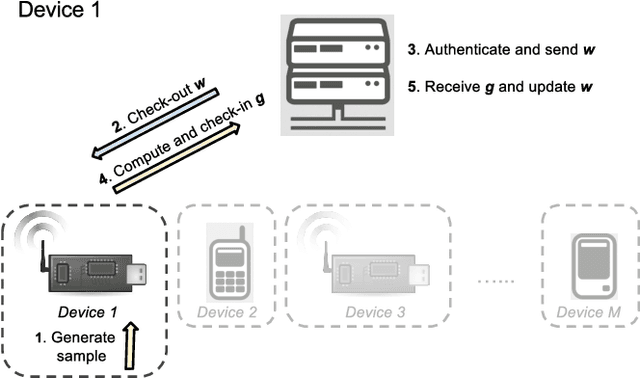
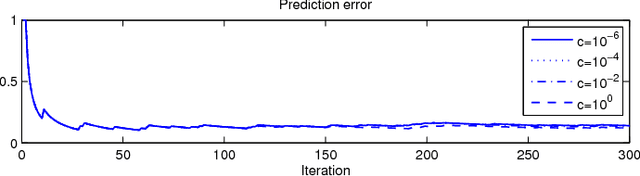
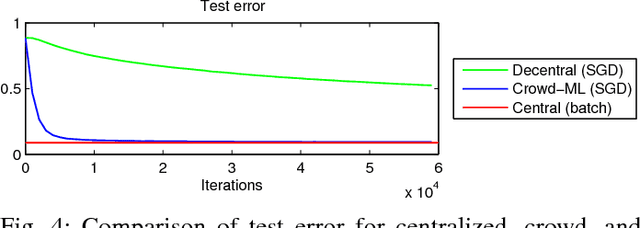
Smart devices with built-in sensors, computational capabilities, and network connectivity have become increasingly pervasive. The crowds of smart devices offer opportunities to collectively sense and perform computing tasks in an unprecedented scale. This paper presents Crowd-ML, a privacy-preserving machine learning framework for a crowd of smart devices, which can solve a wide range of learning problems for crowdsensing data with differential privacy guarantees. Crowd-ML endows a crowdsensing system with an ability to learn classifiers or predictors online from crowdsensing data privately with minimal computational overheads on devices and servers, suitable for a practical and large-scale employment of the framework. We analyze the performance and the scalability of Crowd-ML, and implement the system with off-the-shelf smartphones as a proof of concept. We demonstrate the advantages of Crowd-ML with real and simulated experiments under various conditions.