 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering the Unknown Knowns: Turning Implicit Knowledge in the Dataset into Explicit Training Examples for Visual Question Answering
Paper and Code
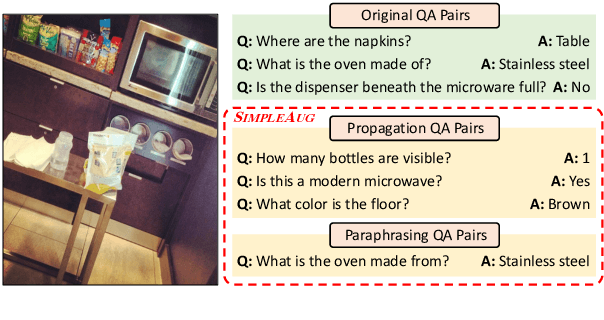

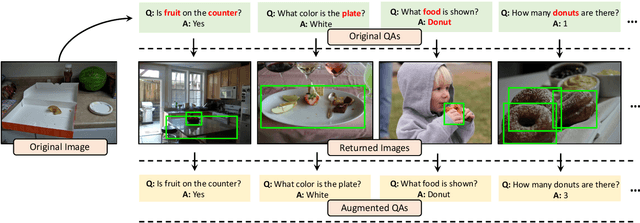
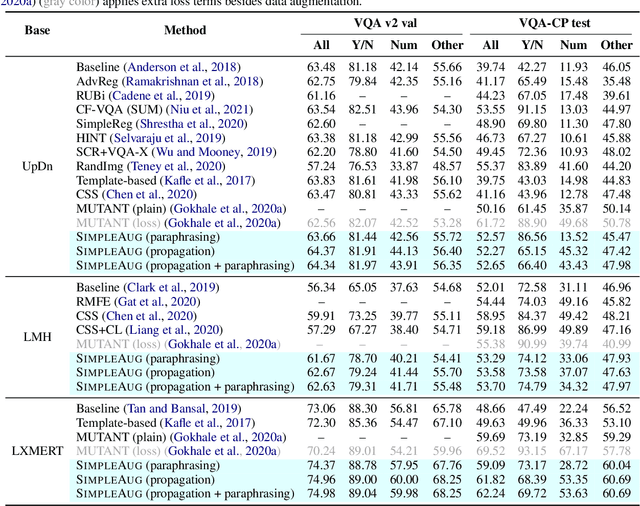
Visual question answering (VQA) is challenging not only because the model has to handle multi-modal information, but also because it is just so hard to collect sufficient training examples -- there are too many questions one can ask about an image. As a result, a VQA model trained solely on human-annotated examples could easily over-fit specific question styles or image contents that are being asked, leaving the model largely ignorant about the sheer diversity of questions. Existing methods address this issue primarily by introducing an auxiliary task such as visual grounding, cycle consistency, or debiasing. In this paper, we take a drastically different approach. We found that many of the "unknowns" to the learned VQA model are indeed "known" in the dataset implicitly. For instance, questions asking about the same object in different images are likely paraphrases; the number of detected or annotated objects in an image already provides the answer to the "how many" question, even if the question has not been annotated for that image. Building upon these insights, we present a simple data augmentation pipeline SimpleAug to turn this "known" knowledge into training examples for VQA. We show that these augmented examples can notably improve the learned VQA models' performance, not only on the VQA-CP dataset with language prior shifts but also on the VQA v2 dataset without such shifts. Our method further opens up the door to leverage weakly-labeled or unlabeled images in a principled way to enhance VQA models. Our code and data are publicly available at https://github.com/heendung/simpleAUG.