 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
Text-Conditioned Background Generation for Editable Multi-Layer Documents
Dec 19, 2025



We present a framework for document-centric background generation with multi-page editing and thematic continuity. To ensure text regions remain readable, we employ a \emph{latent masking} formulation that softly attenuates updates in the diffusion space, inspired by smooth barrier functions in physics and numerical optimization. In addition, we introduce \emph{Automated Readability Optimization (ARO)}, which automatically places semi-transparent, rounded backing shapes behind text regions. ARO determines the minimal opacity needed to satisfy perceptual contrast standards (WCAG 2.2) relative to the underlying background, ensuring readability while maintaining aesthetic harmony without human intervention. Multi-page consistency is maintained through a summarization-and-instruction process, where each page is distilled into a compact representation that recursively guides subsequent generations. This design reflects how humans build continuity by retaining prior context, ensuring that visual motifs evolve coherently across an entire document. Our method further treats a document as a structured composition in which text, figures, and backgrounds are preserved or regenerated as separate layers, allowing targeted background editing without compromising readability. Finally, user-provided prompts allow stylistic adjustments in color and texture, balancing automated consistency with flexible customization. Our training-free framework produces visually coherent, text-preserving, and thematically aligned documents, bridging generative modeling with natural design workflows.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.
AVA-Bench: Atomic Visual Ability Benchmark for Vision Foundation Models
Jun 10, 2025



The rise of vision foundation models (VFMs) calls for systematic evaluation. A common approach pairs VFMs with large language models (LLMs) as general-purpose heads, followed by evaluation on broad Visual Question Answering (VQA) benchmarks. However, this protocol has two key blind spots: (i) the instruction tuning data may not align with VQA test distributions, meaning a wrong prediction can stem from such data mismatch rather than a VFM' visual shortcomings; (ii) VQA benchmarks often require multiple visual abilities, making it hard to tell whether errors stem from lacking all required abilities or just a single critical one. To address these gaps, we introduce AVA-Bench, the first benchmark that explicitly disentangles 14 Atomic Visual Abilities (AVAs) -- foundational skills like localization, depth estimation, and spatial understanding that collectively support complex visual reasoning tasks. By decoupling AVAs and matching training and test distributions within each, AVA-Bench pinpoints exactly where a VFM excels or falters. Applying AVA-Bench to leading VFMs thus reveals distinctive "ability fingerprints," turning VFM selection from educated guesswork into principled engineering. Notably, we find that a 0.5B LLM yields similar VFM rankings as a 7B LLM while cutting GPU hours by 8x, enabling more efficient evaluation. By offering a comprehensive and transparent benchmark, we hope AVA-Bench lays the foundation for the next generation of VFMs.
CompBench: A Comparative Reasoning Benchmark for Multimodal LLMs
Jul 23, 2024
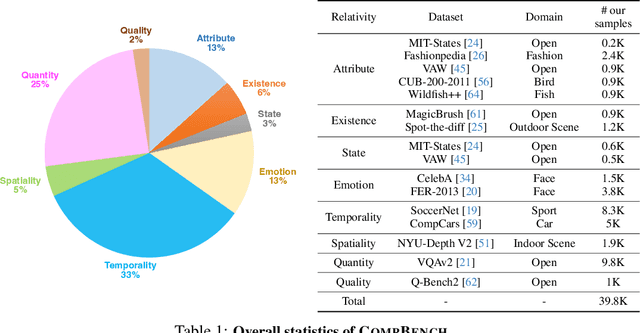
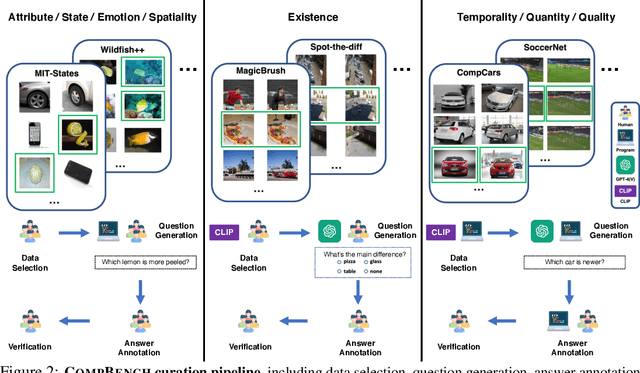
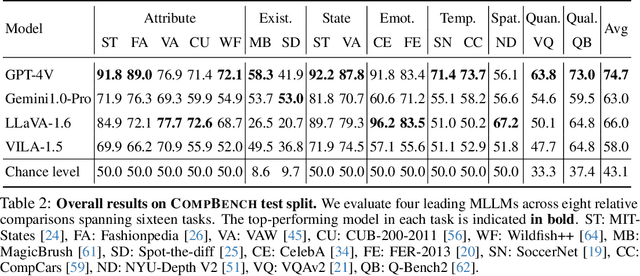
The ability to compare objects, scenes, or situations is crucial for effective decision-making and problem-solving in everyday life. For instance, comparing the freshness of apples enables better choices during grocery shopping, while comparing sofa designs helps optimize the aesthetics of our living space. Despite its significance, the comparative capability is largely unexplored in artificial general intelligence (AGI). In this paper, we introduce CompBench, a benchmark designed to evaluate the comparative reasoning capability of multimodal large language models (MLLMs). CompBench mines and pairs images through visually oriented questions covering eight dimensions of relative comparison: visual attribute, existence, state, emotion, temporality, spatiality, quantity, and quality. We curate a collection of around 40K image pairs using metadata from diverse vision datasets and CLIP similarity scores. These image pairs span a broad array of visual domains, including animals, fashion, sports, and both outdoor and indoor scenes. The questions are carefully crafted to discern relative characteristics between two images and are labeled by human annotators for accuracy and relevance. We use CompBench to evaluate recent MLLMs, including GPT-4V(ision), Gemini-Pro, and LLaVA-1.6. Our results reveal notable shortcomings in their comparative abilities. We believe CompBench not only sheds light on these limitations but also establishes a solid foundation for future enhancements in the comparative capability of MLLMs.
ARES: Alternating Reinforcement Learning and Supervised Fine-Tuning for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback
Jun 25, 2024Large Multimodal Models (LMMs) excel at comprehending human instructions and demonstrate remarkable results across a broad spectrum of tasks. Reinforcement Learning from Human Feedback (RLHF) and AI Feedback (RLAIF) further refine LLMs by aligning them with specific preferences. These methods primarily use ranking-based feedback for entire generations. With advanced AI models (Teacher), such as GPT-4 and Claude 3 Opus, we can request various types of detailed feedback that are expensive for humans to provide. We propose a two-stage algorithm ARES that Alternates REinforcement Learning (RL) and Supervised Fine-Tuning (SFT). First, we request the Teacher to score how much each sentence contributes to solving the problem in a Chain-of-Thought (CoT). This sentence-level feedback allows us to consider individual valuable segments, providing more granular rewards for the RL procedure. Second, we ask the Teacher to correct the wrong reasoning after the RL stage. The RL procedure requires massive efforts for hyperparameter tuning and often generates errors like repetitive words and incomplete sentences. With the correction feedback, we stabilize the RL fine-tuned model through SFT. We conduct experiments on multi-model dataset ScienceQA and A-OKVQA to demonstrate the effectiveness of our proposal. ARES rationale reasoning achieves around 70% win rate against baseline models judged by GPT-4o. Additionally, we observe that the improved rationale reasoning leads to a 2.5% increase in inference answer accuracy on average for the multi-modal datasets.
II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
Feb 16, 2024



Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding "single-hop" reasoning, whereas only a few questions require "multi-hop" reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
Dual-View Visual Contextualization for Web Navigation
Feb 06, 2024



Automatic web navigation aims to build a web agent that can follow language instructions to execute complex and diverse tasks on real-world websites. Existing work primarily takes HTML documents as input, which define the contents and action spaces (i.e., actionable elements and operations) of webpages. Nevertheless, HTML documents may not provide a clear task-related context for each element, making it hard to select the right (sequence of) actions. In this paper, we propose to contextualize HTML elements through their "dual views" in webpage screenshots: each HTML element has its corresponding bounding box and visual content in the screenshot. We build upon the insight -- web developers tend to arrange task-related elements nearby on webpages to enhance user experiences -- and propose to contextualize each element with its neighbor elements, using both textual and visual features. The resulting representations of HTML elements are more informative for the agent to take action. We validate our method on the recently released Mind2Web dataset, which features diverse navigation domains and tasks on real-world websites. Our method consistently outperforms the baseline in all the scenarios, including cross-task, cross-website, and cross-domain ones.
GPT-4V is a Generalist Web Agent, if Grounded
Jan 03, 2024The recent development on large multimodal models (LMMs), especially GPT-4V(ision) and Gemini, has been quickly expanding the capability boundaries of multimodal models beyond traditional tasks like image captioning and visual question answering. In this work, we explore the potential of LMMs like GPT-4V as a generalist web agent that can follow natural language instructions to complete tasks on any given website. We propose SEEACT, a generalist web agent that harnesses the power of LMMs for integrated visual understanding and acting on the web. We evaluate on the recent MIND2WEB benchmark. In addition to standard offline evaluation on cached websites, we enable a new online evaluation setting by developing a tool that allows running web agents on live websites. We show that GPT-4V presents a great potential for web agents - it can successfully complete 50% of the tasks on live websites if we manually ground its textual plans into actions on the websites. This substantially outperforms text-only LLMs like GPT-4 or smaller models (FLAN-T5 and BLIP-2) specifically fine-tuned for web agents. However, grounding still remains a major challenge. Existing LMM grounding strategies like set-of-mark prompting turns out not effective for web agents, and the best grounding strategy we develop in this paper leverages both the HTML text and visuals. Yet, there is still a substantial gap with oracle grounding, leaving ample room for further improvement.
PreSTU: Pre-Training for Scene-Text Understanding
Sep 12, 2022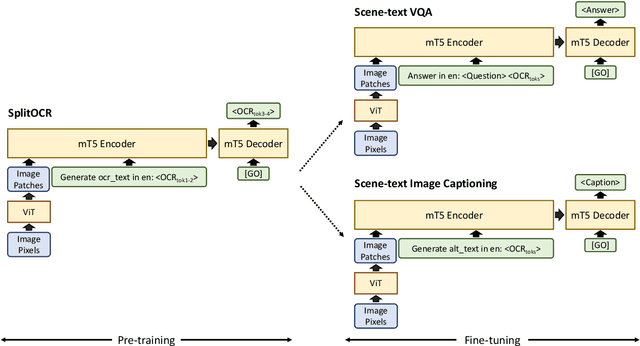
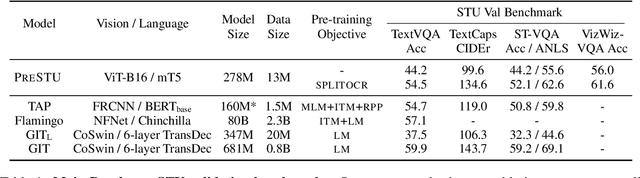
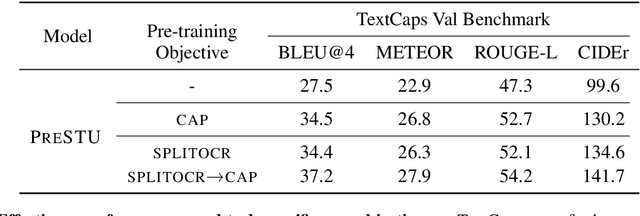
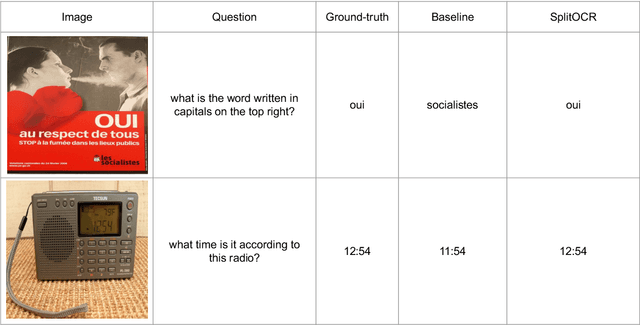
The ability to read and reason about texts in an image is often lacking in vision-and-language (V&L) models. How can we learn V&L models that exhibit strong scene-text understanding (STU)? In this paper, we propose PreSTU, a simple pre-training recipe specifically designed for scene-text understanding. PreSTU combines a simple OCR-aware pre-training objective with a large-scale image-text dataset with off-the-shelf OCR signals. We empirically demonstrate the superiority of this pre-training objective on TextVQA, TextCaps, ST-VQA, and VizWiz-VQA. We also study which factors affect STU performance, where we highlight the importance of image resolution and dataset scale during pre-training.