 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARES: Alternating Reinforcement Learning and Supervised Fine-Tuning for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback
Jun 25, 2024Large Multimodal Models (LMMs) excel at comprehending human instructions and demonstrate remarkable results across a broad spectrum of tasks. Reinforcement Learning from Human Feedback (RLHF) and AI Feedback (RLAIF) further refine LLMs by aligning them with specific preferences. These methods primarily use ranking-based feedback for entire generations. With advanced AI models (Teacher), such as GPT-4 and Claude 3 Opus, we can request various types of detailed feedback that are expensive for humans to provide. We propose a two-stage algorithm ARES that Alternates REinforcement Learning (RL) and Supervised Fine-Tuning (SFT). First, we request the Teacher to score how much each sentence contributes to solving the problem in a Chain-of-Thought (CoT). This sentence-level feedback allows us to consider individual valuable segments, providing more granular rewards for the RL procedure. Second, we ask the Teacher to correct the wrong reasoning after the RL stage. The RL procedure requires massive efforts for hyperparameter tuning and often generates errors like repetitive words and incomplete sentences. With the correction feedback, we stabilize the RL fine-tuned model through SFT. We conduct experiments on multi-model dataset ScienceQA and A-OKVQA to demonstrate the effectiveness of our proposal. ARES rationale reasoning achieves around 70% win rate against baseline models judged by GPT-4o. Additionally, we observe that the improved rationale reasoning leads to a 2.5% increase in inference answer accuracy on average for the multi-modal datasets.
Symmetric Reinforcement Learning Loss for Robust Learning on Diverse Tasks and Model Scales
May 29, 2024Reinforcement learning (RL) training is inherently unstable due to factors such as moving targets and high gradient variance. Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) can introduce additional difficulty. Differing preferences can complicate the alignment process, and prediction errors in a trained reward model can become more severe as the LLM generates unseen outputs. To enhance training robustness, RL has adopted techniques from supervised learning, such as ensembles and layer normalization. In this work, we improve the stability of RL training by adapting the reverse cross entropy (RCE) from supervised learning for noisy data to define a symmetric RL loss. We demonstrate performance improvements across various tasks and scales. We conduct experiments in discrete action tasks (Atari games) and continuous action space tasks (MuJoCo benchmark and Box2D) using Symmetric A2C (SA2C) and Symmetric PPO (SPPO), with and without added noise with especially notable performance in SPPO across different hyperparameters. Furthermore, we validate the benefits of the symmetric RL loss when using SPPO for large language models through improved performance in RLHF tasks, such as IMDB positive sentiment sentiment and TL;DR summarization tasks.
Reinforcement Learning for Fine-tuning Text-to-speech Diffusion Models
May 23, 2024Recent advancements in generative models have sparked significant interest within the machine learning community. Particularly, diffusion models have demonstrated remarkable capabilities in synthesizing images and speech. Studies such as those by Lee et al. [19], Black et al. [4], Wang et al. [36], and Fan et al. [8] illustrate that Reinforcement Learning with Human Feedback (RLHF) can enhance diffusion models for image synthesis. However, due to architectural differences between these models and those employed in speech synthesis, it remains uncertain whether RLHF could similarly benefit speech synthesis models. In this paper, we explore the practical application of RLHF to diffusion-based text-to-speech synthesis, leveraging the mean opinion score (MOS) as predicted by UTokyo-SaruLab MOS prediction system [29] as a proxy loss. We introduce diffusion model loss-guided RL policy optimization (DLPO) and compare it against other RLHF approaches, employing the NISQA speech quality and naturalness assessment model [21] and human preference experiments for further evaluation. Our results show that RLHF can enhance diffusion-based text-to-speech synthesis models, and, moreover, DLPO can better improve diffusion models in generating natural and high quality speech audios.
Normality-Guided Distributional Reinforcement Learning for Continuous Control
Aug 28, 2022



Learning a predictive model of the mean return, or value function, plays a critical role in many reinforcement learning algorithms. Distributional reinforcement learning (DRL) methods instead model the value distribution, which has been shown to improve performance in many settings. In this paper, we model the value distribution as approximately normal using the Markov Chain central limit theorem. We analytically compute quantile bars to provide a new DRL target that is informed by the decrease in standard deviation that occurs over the course of an episode. In addition, we suggest an exploration strategy based on how closely the learned value distribution resembles the target normal distribution to make the value function more accurate for better policy improvement. The approach we outline is compatible with many DRL structures. We use proximal policy optimization as a testbed and show that both the normality-guided target and exploration bonus produce performance improvements. We demonstrate our method outperforms DRL baselines on a number of continuous control tasks.
Training Transition Policies via Distribution Matching for Complex Tasks
Oct 08, 2021
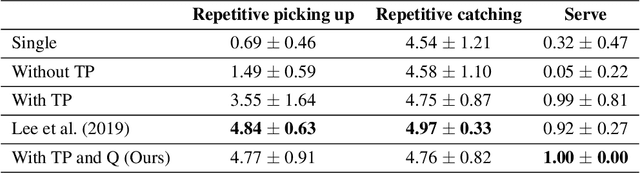
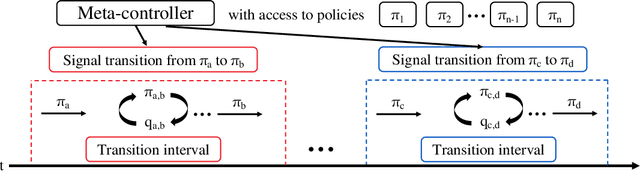

Humans decompose novel complex tasks into simpler ones to exploit previously learned skills. Analogously, hierarchical reinforcement learning seeks to leverage lower-level policies for simple tasks to solve complex ones. However, because each lower-level policy induces a different distribution of states, transitioning from one lower-level policy to another may fail due to an unexpected starting state. We introduce transition policies that smoothly connect lower-level policies by producing a distribution of states and actions that matches what is expected by the next policy. Training transition policies is challenging because the natural reward signal -- whether the next policy can execute its subtask successfully -- is sparse. By training transition policies via adversarial inverse reinforcement learning to match the distribution of expected states and actions, we avoid relying on task-based reward. To further improve performance, we use deep Q-learning with a binary action space to determine when to switch from a transition policy to the next pre-trained policy, using the success or failure of the next subtask as the reward. Although the reward is still sparse, the problem is less severe due to the simple binary action space. We demonstrate our method on continuous bipedal locomotion and arm manipulation tasks that require diverse skills. We show that it smoothly connects the lower-level policies, achieving higher success rates than previous methods that search for successful trajectories based on a reward function, but do not match the state distribution.
Proximal Policy Gradient: PPO with Policy Gradient
Oct 20, 2020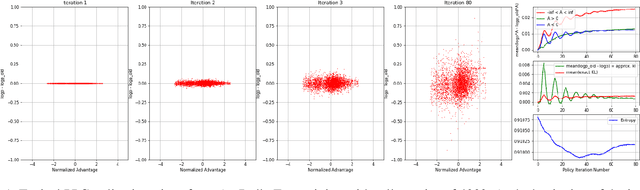
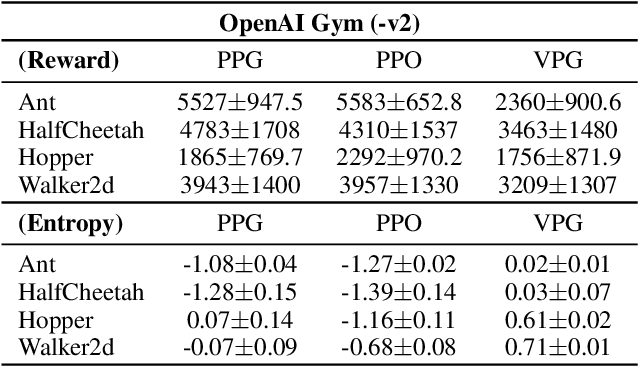
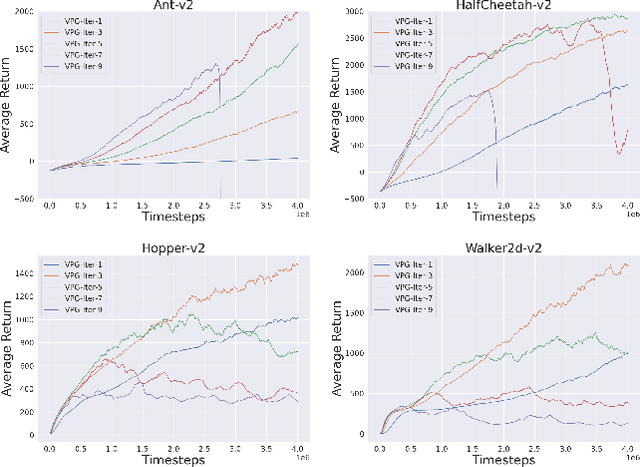
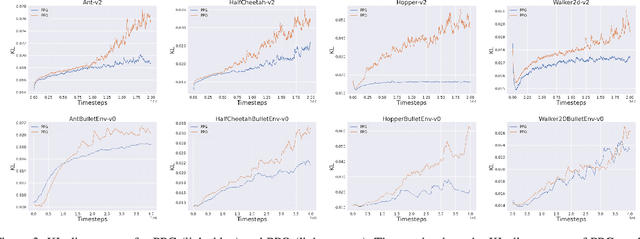
In this paper, we propose a new algorithm PPG (Proximal Policy Gradient), which is close to both VPG (vanilla policy gradient) and PPO (proximal policy optimization). The PPG objective is a partial variation of the VPG objective and the gradient of the PPG objective is exactly same as the gradient of the VPG objective. To increase the number of policy update iterations, we introduce the advantage-policy plane and design a new clipping strategy. We perform experiments in OpenAI Gym and Bullet robotics environments for ten random seeds. The performance of PPG is comparable to PPO, and the entropy decays slower than PPG. Thus we show that performance similar to PPO can be obtained by using the gradient formula from the original policy gradient theorem.