 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
Reinforcement Learning for Fine-tuning Text-to-speech Diffusion Models
May 23, 2024Recent advancements in generative models have sparked significant interest within the machine learning community. Particularly, diffusion models have demonstrated remarkable capabilities in synthesizing images and speech. Studies such as those by Lee et al. [19], Black et al. [4], Wang et al. [36], and Fan et al. [8] illustrate that Reinforcement Learning with Human Feedback (RLHF) can enhance diffusion models for image synthesis. However, due to architectural differences between these models and those employed in speech synthesis, it remains uncertain whether RLHF could similarly benefit speech synthesis models. In this paper, we explore the practical application of RLHF to diffusion-based text-to-speech synthesis, leveraging the mean opinion score (MOS) as predicted by UTokyo-SaruLab MOS prediction system [29] as a proxy loss. We introduce diffusion model loss-guided RL policy optimization (DLPO) and compare it against other RLHF approaches, employing the NISQA speech quality and naturalness assessment model [21] and human preference experiments for further evaluation. Our results show that RLHF can enhance diffusion-based text-to-speech synthesis models, and, moreover, DLPO can better improve diffusion models in generating natural and high quality speech audios.
Exploring How Generative Adversarial Networks Learn Phonological Representations
May 21, 2023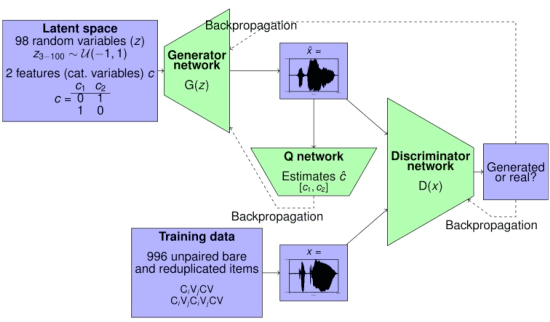
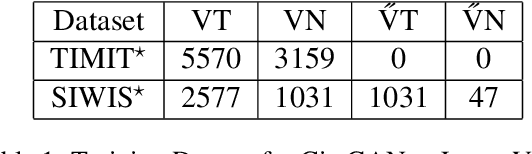
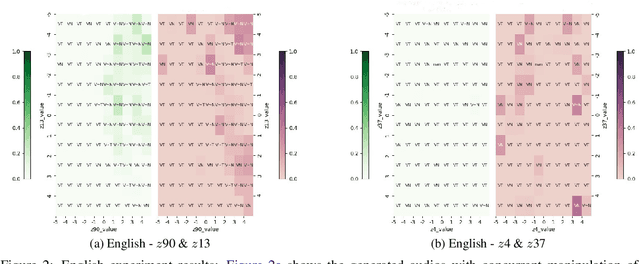
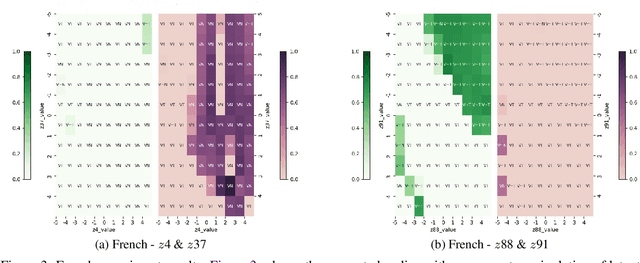
This paper explores how Generative Adversarial Networks (GANs) learn representations of phonological phenomena. We analyze how GANs encode contrastive and non-contrastive nasality in French and English vowels by applying the ciwGAN architecture (Begus 2021a). Begus claims that ciwGAN encodes linguistically meaningful representations with categorical variables in its latent space and manipulating the latent variables shows an almost one to one corresponding control of the phonological features in ciwGAN's generated outputs. However, our results show an interactive effect of latent variables on the features in the generated outputs, which suggests the learned representations in neural networks are different from the phonological representations proposed by linguists. On the other hand, ciwGAN is able to distinguish contrastive and noncontrastive features in English and French by encoding them differently. Comparing the performance of GANs learning from different languages results in a better understanding of what language specific features contribute to developing language specific phonological representations. We also discuss the role of training data frequencies in phonological feature learning.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022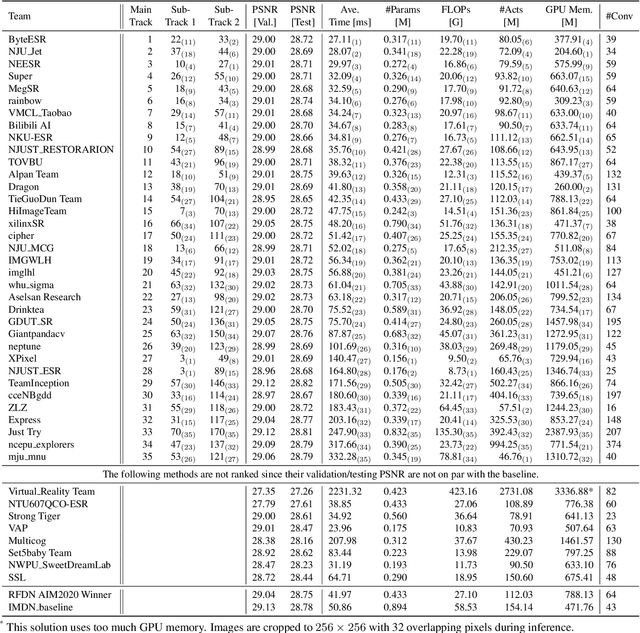
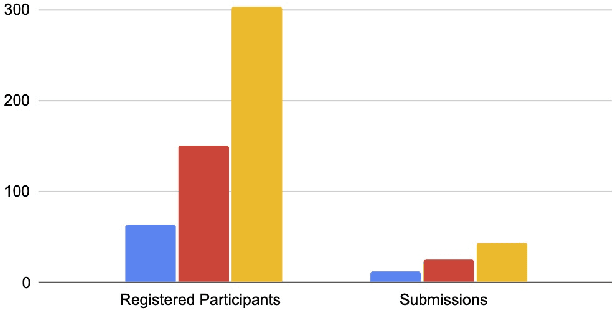
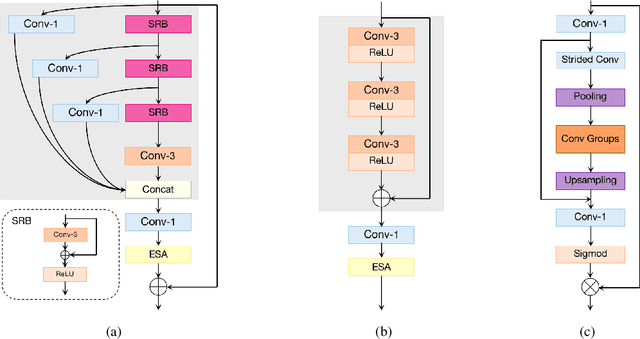
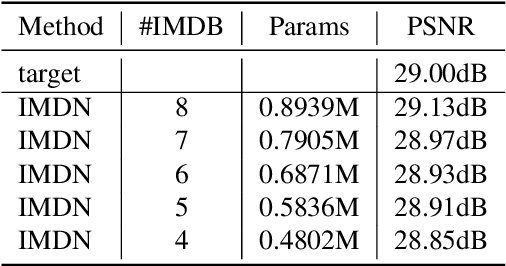
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
A Low-cost Robot with Autonomous Recharge and Navigation for Weed Control in Fields with Narrow Row Spacing
Dec 03, 2021

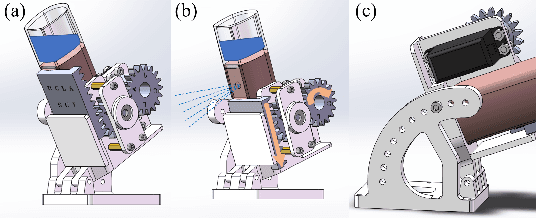

Modern herbicide application in agricultural settings typically relies on either large scale sprayers that dispense herbicide over crops and weeds alike or portable sprayers that require labor intensive manual operation. The former method results in overuse of herbicide and reduction in crop yield while the latter is often untenable in large scale operations. This paper presents the first fully autonomous robot for weed management for row crops capable of computer vision based navigation, weed detection, complete field coverage, and automatic recharge for under \$400. The target application is autonomous inter-row weed control in crop fields, e.g. flax and canola, where the spacing between croplines is as small as one foot. The proposed robot is small enough to pass between croplines at all stages of plant growth while detecting weeds and spraying herbicide. A recharging system incorporates newly designed robotic hardware, a ramp, a robotic charging arm, and a mobile charging station. An integrated vision algorithm is employed to assist with charger alignment effectively. Combined, they enable the robot to work continuously in the field without access to electricity. In addition, a color-based contour algorithm combined with preprocessing techniques is applied for robust navigation relying on the input from the onboard monocular camera. Incorporating such compact robots into farms could help automate weed control, even during late stages of growth, and reduce herbicide use by targeting weeds with precision. The robotic platform is field-tested in the flaxseed fields of North Dakota.