 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Gradient: PPO with Policy Gradient
Oct 20, 2020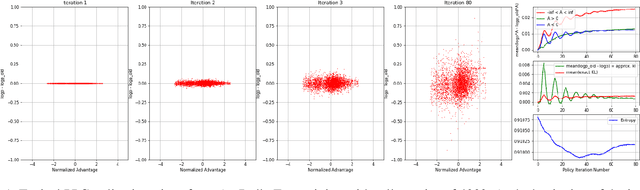
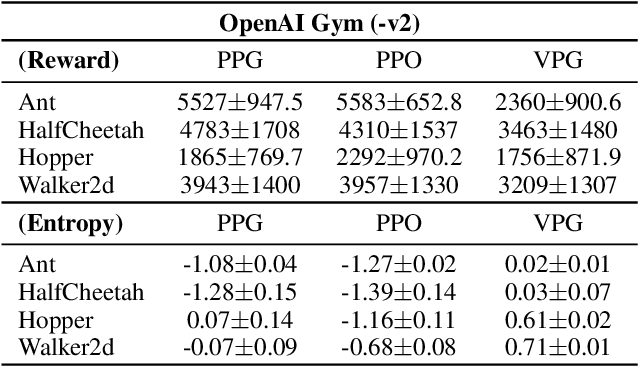
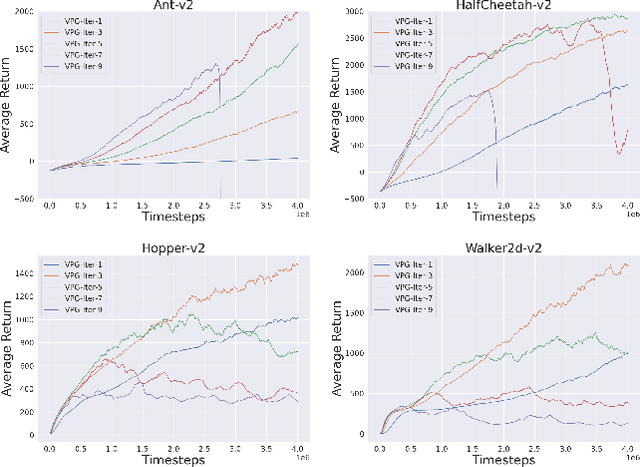
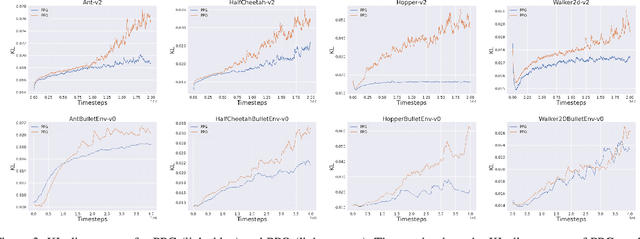
In this paper, we propose a new algorithm PPG (Proximal Policy Gradient), which is close to both VPG (vanilla policy gradient) and PPO (proximal policy optimization). The PPG objective is a partial variation of the VPG objective and the gradient of the PPG objective is exactly same as the gradient of the VPG objective. To increase the number of policy update iterations, we introduce the advantage-policy plane and design a new clipping strategy. We perform experiments in OpenAI Gym and Bullet robotics environments for ten random seeds. The performance of PPG is comparable to PPO, and the entropy decays slower than PPG. Thus we show that performance similar to PPO can be obtained by using the gradient formula from the original policy gradient theorem.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

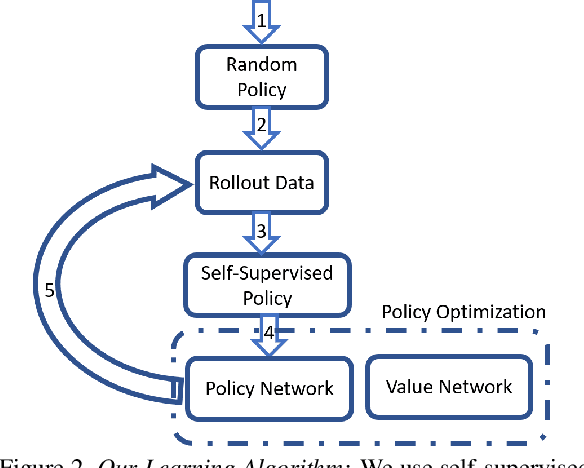

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
PaintBot: A Reinforcement Learning Approach for Natural Media Painting
Apr 03, 2019


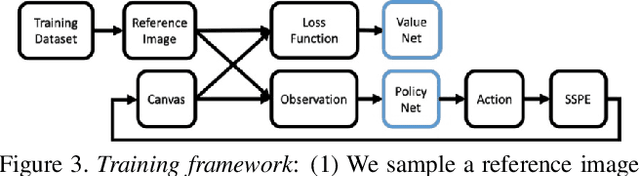
We propose a new automated digital painting framework, based on a painting agent trained through reinforcement learning. To synthesize an image, the agent selects a sequence of continuous-valued actions representing primitive painting strokes, which are accumulated on a digital canvas. Action selection is guided by a given reference image, which the agent attempts to replicate subject to the limitations of the action space and the agent's learned policy. The painting agent policy is determined using a variant of proximal policy optimization reinforcement learning. During training, our agent is presented with patches sampled from an ensemble of reference images. To accelerate training convergence, we adopt a curriculum learning strategy, whereby reference patches are sampled according to how challenging they are using the current policy. We experiment with differing loss functions, including pixel-wise and perceptual loss, which have consequent differing effects on the learned policy. We demonstrate that our painting agent can learn an effective policy with a high dimensional continuous action space comprising pen pressure, width, tilt, and color, for a variety of painting styles. Through a coarse-to-fine refinement process our agent can paint arbitrarily complex images in the desired style.
Learning to Sketch with Deep Q Networks and Demonstrated Strokes
Oct 14, 2018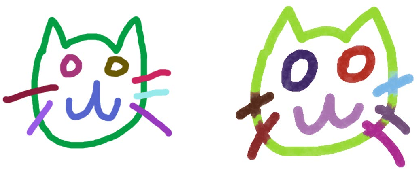


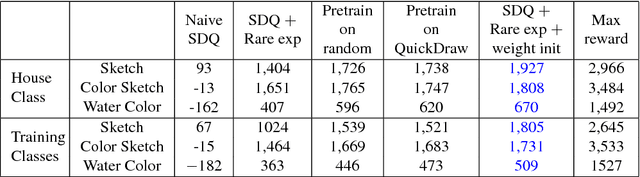
Doodling is a useful and common intelligent skill that people can learn and master. In this work, we propose a two-stage learning framework to teach a machine to doodle in a simulated painting environment via Stroke Demonstration and deep Q-learning (SDQ). The developed system, Doodle-SDQ, generates a sequence of pen actions to reproduce a reference drawing and mimics the behavior of human painters. In the first stage, it learns to draw simple strokes by imitating in supervised fashion from a set of strokeaction pairs collected from artist paintings. In the second stage, it is challenged to draw real and more complex doodles without ground truth actions; thus, it is trained with Qlearning. Our experiments confirm that (1) doodling can be learned without direct stepby- step action supervision and (2) pretraining with stroke demonstration via supervised learning is important to improve performance. We further show that Doodle-SDQ is effective at producing plausible drawings in different media types, including sketch and watercolor.