 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiDense: Binarization for Dense Prediction
Nov 15, 2024



Dense prediction is a critical task in computer vision. However, previous methods often require extensive computational resources, which hinders their real-world application. In this paper, we propose BiDense, a generalized binary neural network (BNN) designed for efficient and accurate dense prediction tasks. BiDense incorporates two key techniques: the Distribution-adaptive Binarizer (DAB) and the Channel-adaptive Full-precision Bypass (CFB). The DAB adaptively calculates thresholds and scaling factors for binarization, effectively retaining more information within BNNs. Meanwhile, the CFB facilitates full-precision bypassing for binary convolutional layers undergoing various channel size transformations, which enhances the propagation of real-valued signals and minimizes information loss. By leveraging these techniques, BiDense preserves more real-valued information, enabling more accurate and detailed dense predictions in BNNs. Extensive experiments demonstrate that our framework achieves performance levels comparable to full-precision models while significantly reducing memory usage and computational costs.
SRPose: Two-view Relative Pose Estimation with Sparse Keypoints
Jul 11, 2024Two-view pose estimation is essential for map-free visual relocalization and object pose tracking tasks. However, traditional matching methods suffer from time-consuming robust estimators, while deep learning-based pose regressors only cater to camera-to-world pose estimation, lacking generalizability to different image sizes and camera intrinsics. In this paper, we propose SRPose, a sparse keypoint-based framework for two-view relative pose estimation in camera-to-world and object-to-camera scenarios. SRPose consists of a sparse keypoint detector, an intrinsic-calibration position encoder, and promptable prior knowledge-guided attention layers. Given two RGB images of a fixed scene or a moving object, SRPose estimates the relative camera or 6D object pose transformation. Extensive experiments demonstrate that SRPose achieves competitive or superior performance compared to state-of-the-art methods in terms of accuracy and speed, showing generalizability to both scenarios. It is robust to different image sizes and camera intrinsics, and can be deployed with low computing resources.
Sim-to-Real Brush Manipulation using Behavior Cloning and Reinforcement Learning
Sep 15, 2023



Developing proficient brush manipulation capabilities in real-world scenarios is a complex and challenging endeavor, with wide-ranging applications in fields such as art, robotics, and digital design. In this study, we introduce an approach designed to bridge the gap between simulated environments and real-world brush manipulation. Our framework leverages behavior cloning and reinforcement learning to train a painting agent, seamlessly integrating it into both virtual and real-world environments. Additionally, we employ a real painting environment featuring a robotic arm and brush, mirroring the MyPaint virtual environment. Our results underscore the agent's effectiveness in acquiring policies for high-dimensional continuous action spaces, facilitating the smooth transfer of brush manipulation techniques from simulation to practical, real-world applications.
Efficient Multi-Agent Motion Planning in Continuous Workspaces Using Medial-Axis-Based Swap Graphs
Feb 27, 2020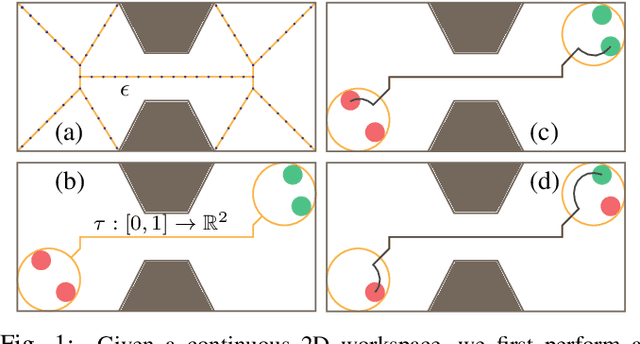
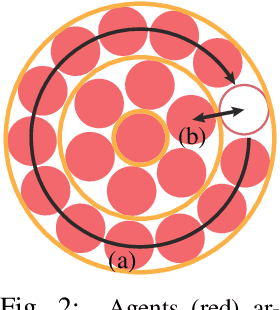
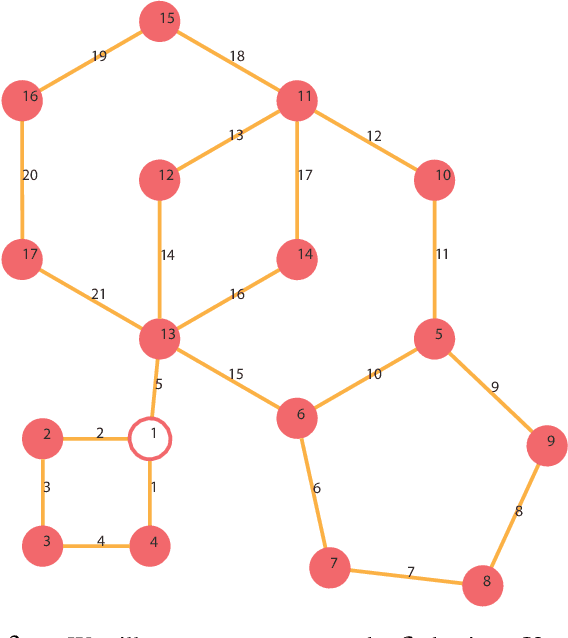
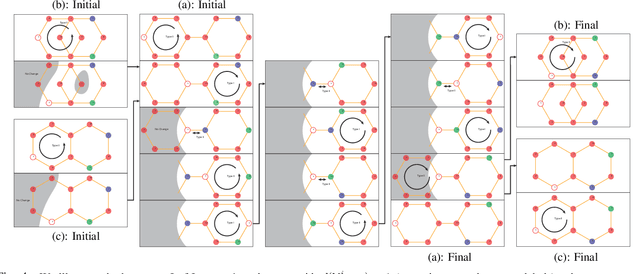
We present an algorithm for homogeneous, labeled, and disk-shaped multi-agent motion planning in continuous workspaces with arbitrarily-shaped obstacles. Our method consists of two steps. First, we convert the continuous free space into a discrete graph where agents are placed on vertices and move along edges. On the graph, a set of swap operations are defined and we ensure that performing these swap operations will not lead to collisions between agents or with obstacles. Second, we prove that it is possible for agents' locations to be arbitrarily permuted on graph vertices using our swap operations, as long as these graph vertices are not fully occupied. In other words, a multi-agent motion planning problem on our graph is always solvable. Finally, we show that such continuous-to-discrete conversion can be performed efficiently with the help of a medial axis analysis and can be performed robustly for workspaces with arbitrarily-shaped obstacles. Moreover, the resulting graph has many vertices and can accommodate a large number of densely packed agents (up to $69\%$ of the volume of free space), and motion plans can be computed $10\times$ faster using our swap operations compared to state-of-the-art methods.
LPaintB: Learning to Paint from Self-SupervisionLPaintB: Learning to Paint from Self-Supervision
Jun 17, 2019

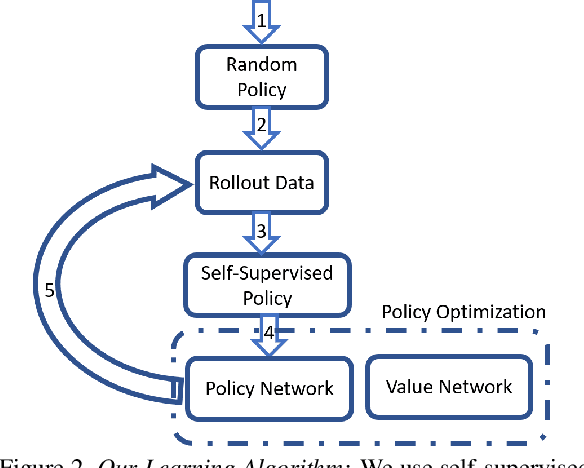

We present a novel reinforcement learning-based natural media painting algorithm. Our goal is to reproduce a reference image using brush strokes and we encode the objective through observations. Our formulation takes into account that the distribution of the reward in the action space is sparse and training a reinforcement learning algorithm from scratch can be difficult. We present an approach that combines self-supervised learning and reinforcement learning to effectively transfer negative samples into positive ones and change the reward distribution. We demonstrate the benefits of our painting agent to reproduce reference images with brush strokes. The training phase takes about one hour and the runtime algorithm takes about 30 seconds on a GTX1080 GPU reproducing a 1000x800 image with 20,000 strokes.
PaintBot: A Reinforcement Learning Approach for Natural Media Painting
Apr 03, 2019


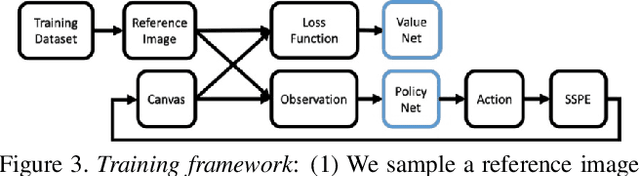
We propose a new automated digital painting framework, based on a painting agent trained through reinforcement learning. To synthesize an image, the agent selects a sequence of continuous-valued actions representing primitive painting strokes, which are accumulated on a digital canvas. Action selection is guided by a given reference image, which the agent attempts to replicate subject to the limitations of the action space and the agent's learned policy. The painting agent policy is determined using a variant of proximal policy optimization reinforcement learning. During training, our agent is presented with patches sampled from an ensemble of reference images. To accelerate training convergence, we adopt a curriculum learning strategy, whereby reference patches are sampled according to how challenging they are using the current policy. We experiment with differing loss functions, including pixel-wise and perceptual loss, which have consequent differing effects on the learned policy. We demonstrate that our painting agent can learn an effective policy with a high dimensional continuous action space comprising pen pressure, width, tilt, and color, for a variety of painting styles. Through a coarse-to-fine refinement process our agent can paint arbitrarily complex images in the desired style.
Manipulating Highly Deformable Materials Using a Visual Feedback Dictionary
Jan 16, 2019


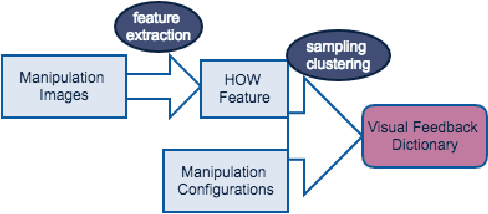
The complex physical properties of highly deformable materials such as clothes pose significant challenges fanipulation systems. We present a novel visual feedback dictionary-based method for manipulating defoor autonomous robotic mrmable objects towards a desired configuration. Our approach is based on visual servoing and we use an efficient technique to extract key features from the RGB sensor stream in the form of a histogram of deformable model features. These histogram features serve as high-level representations of the state of the deformable material. Next, we collect manipulation data and use a visual feedback dictionary that maps the velocity in the high-dimensional feature space to the velocity of the robotic end-effectors for manipulation. We have evaluated our approach on a set of complex manipulation tasks and human-robot manipulation tasks on different cloth pieces with varying material characteristics.
Cloth Manipulation Using Random-Forest-Based Imitation Learning
Jan 16, 2019
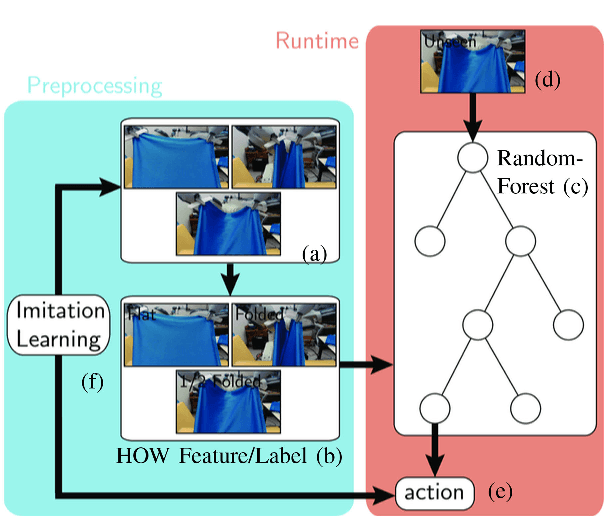

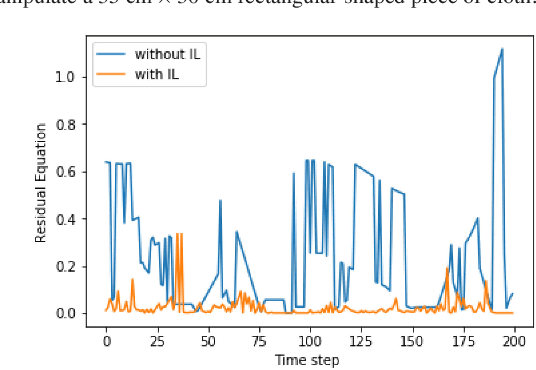
We present a novel approach for robust manipulation of high-DOF deformable objects such as cloth. Our approach uses a random forest-based controller that maps the observed visual features of the cloth to an optimal control action of the manipulator. The topological structure of this random forest-based controller is determined automatically based on the training data consisting visual features and optimal control actions. This enables us to integrate the overall process of training data classification and controller optimization into an imitation learning (IL) approach. Our approach enables learning of robust control policy for cloth manipulation with guarantees on convergence.We have evaluated our approach on different multi-task cloth manipulation benchmarks such as flattening, folding and twisting. In practice, our approach works well with different deformable features learned based on the specific task or deep learning. Moreover, our controller outperforms a simple or piecewise linear controller in terms of robustness to noise. In addition, our approach is easy to implement and does not require much parameter tuning.
Efficient Generation of Motion Plans from Attribute-Based Natural Language Instructions Using Dynamic Constraint Mapping
Oct 15, 2018
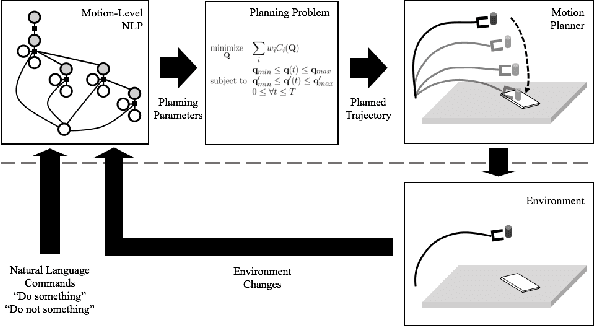


We present an algorithm for combining natural language processing (NLP) and fast robot motion planning to automatically generate robot movements. Our formulation uses a novel concept called Dynamic Constraint Mapping to transform complex, attribute-based natural language instructions into appropriate cost functions and parametric constraints for optimization-based motion planning. We generate a factor graph from natural language instructions called the Dynamic Grounding Graph (DGG), which takes latent parameters into account. The coefficients of this factor graph are learned based on conditional random fields (CRFs) and are used to dynamically generate the constraints for motion planning. We map the cost function directly to the motion parameters of the planner and compute smooth trajectories in dynamic scenes. We highlight the performance of our approach in a simulated environment and via a human interacting with a 7-DOF Fetch robot using intricate language commands including negation, orientation specification, and distance constraints.
Fast Motion Planning for High-DOF Robot Systems Using Hierarchical System Identification
Oct 05, 2018


We present an efficient algorithm for motion planning and control of a robot system with a high number of degrees-of-freedom. These include high-DOF soft robots or an articulated robot interacting with a deformable environment. Our approach takes into account dynamics constraints and present a novel technique to accelerate the forward dynamic computation using a data-driven method. We precompute the forward dynamic function of the robot system on a hierarchical adaptive grid. Furthermore, we exploit the properties of underactuated robot systems and perform these computations for a few DOFs. We provide error bounds for our approximate forward dynamics computation and use our approach for optimization-based motion planning and reinforcement-learning-based feedback control. Our formulation is used for motion planning of two high DOF robot systems: a high-DOF line-actuated elastic robot arm and an underwater swimming robot operating in water. As compared to prior techniques based on exact dynamic function computation, we observe one to two orders of magnitude improvement in performance.