 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Under-Sampled High-Dimensional Data Recovery via Symbiotic Multi-Prior Tensor Reconstruction
Apr 08, 2025The advancement of sensing technology has driven the widespread application of high-dimensional data. However, issues such as missing entries during acquisition and transmission negatively impact the accuracy of subsequent tasks. Tensor reconstruction aims to recover the underlying complete data from under-sampled observed data by exploring prior information in high-dimensional data. However, due to insufficient exploration, reconstruction methods still face challenges when sampling rate is extremely low. This work proposes a tensor reconstruction method integrating multiple priors to comprehensively exploit the inherent structure of the data. Specifically, the method combines learnable tensor decomposition to enforce low-rank constraints of the reconstructed data, a pre-trained convolutional neural network for smoothing and denoising, and block-matching and 3D filtering regularization to enhance the non-local similarity in the reconstructed data. An alternating direction method of the multipliers algorithm is designed to decompose the resulting optimization problem into three subproblems for efficient resolution. Extensive experiments on color images, hyperspectral images, and grayscale videos datasets demonstrate the superiority of our method in extreme cases as compared with state-of-the-art methods.
BiDense: Binarization for Dense Prediction
Nov 15, 2024



Dense prediction is a critical task in computer vision. However, previous methods often require extensive computational resources, which hinders their real-world application. In this paper, we propose BiDense, a generalized binary neural network (BNN) designed for efficient and accurate dense prediction tasks. BiDense incorporates two key techniques: the Distribution-adaptive Binarizer (DAB) and the Channel-adaptive Full-precision Bypass (CFB). The DAB adaptively calculates thresholds and scaling factors for binarization, effectively retaining more information within BNNs. Meanwhile, the CFB facilitates full-precision bypassing for binary convolutional layers undergoing various channel size transformations, which enhances the propagation of real-valued signals and minimizes information loss. By leveraging these techniques, BiDense preserves more real-valued information, enabling more accurate and detailed dense predictions in BNNs. Extensive experiments demonstrate that our framework achieves performance levels comparable to full-precision models while significantly reducing memory usage and computational costs.
SRPose: Two-view Relative Pose Estimation with Sparse Keypoints
Jul 11, 2024Two-view pose estimation is essential for map-free visual relocalization and object pose tracking tasks. However, traditional matching methods suffer from time-consuming robust estimators, while deep learning-based pose regressors only cater to camera-to-world pose estimation, lacking generalizability to different image sizes and camera intrinsics. In this paper, we propose SRPose, a sparse keypoint-based framework for two-view relative pose estimation in camera-to-world and object-to-camera scenarios. SRPose consists of a sparse keypoint detector, an intrinsic-calibration position encoder, and promptable prior knowledge-guided attention layers. Given two RGB images of a fixed scene or a moving object, SRPose estimates the relative camera or 6D object pose transformation. Extensive experiments demonstrate that SRPose achieves competitive or superior performance compared to state-of-the-art methods in terms of accuracy and speed, showing generalizability to both scenarios. It is robust to different image sizes and camera intrinsics, and can be deployed with low computing resources.
Similarity-aware Syncretic Latent Diffusion Model for Medical Image Translation with Representation Learning
Jun 20, 2024
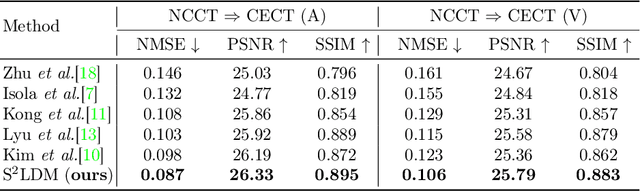
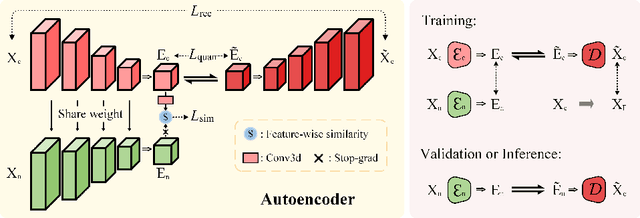
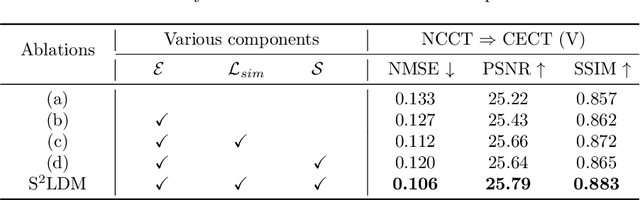
Non-contrast CT (NCCT) imaging may reduce image contrast and anatomical visibility, potentially increasing diagnostic uncertainty. In contrast, contrast-enhanced CT (CECT) facilitates the observation of regions of interest (ROI). Leading generative models, especially the conditional diffusion model, demonstrate remarkable capabilities in medical image modality transformation. Typical conditional diffusion models commonly generate images with guidance of segmentation labels for medical modal transformation. Limited access to authentic guidance and its low cardinality can pose challenges to the practical clinical application of conditional diffusion models. To achieve an equilibrium of generative quality and clinical practices, we propose a novel Syncretic generative model based on the latent diffusion model for medical image translation (S$^2$LDM), which can realize high-fidelity reconstruction without demand of additional condition during inference. S$^2$LDM enhances the similarity in distinct modal images via syncretic encoding and diffusing, promoting amalgamated information in the latent space and generating medical images with more details in contrast-enhanced regions. However, syncretic latent spaces in the frequency domain tend to favor lower frequencies, commonly locate in identical anatomic structures. Thus, S$^2$LDM applies adaptive similarity loss and dynamic similarity to guide the generation and supplements the shortfall in high-frequency details throughout the training process. Quantitative experiments confirm the effectiveness of our approach in medical image translation. Our code will release lately.
A Survey of Blockchain, Artificial Intelligence, and Edge Computing for Web 3.0
Nov 22, 2023Web 3.0, as the third generation of the World Wide Web, aims to solve contemporary problems of trust, centralization, and data ownership. Driven by the latest advances in cutting-edge technologies, Web 3.0 is moving towards a more open, decentralized, intelligent, and interconnected network. However, increasingly widespread data breaches have raised awareness of online privacy and security of personal data. Additionally, since Web 3.0 is a sophisticated and complex convergence, the technical details behind it are not as clear as the characteristics it presents. In this survey, we conduct an in-depth exploration of Web 3.0 from the perspectives of blockchain, artificial intelligence, and edge computing. Specifically, we begin with summarizing the evolution of the Internet and providing an overview of these three key technological factors. Afterward, we provide a thorough analysis of each technology separately, including its relevance to Web 3.0, key technology components, and practical applications. We also propose decentralized storage and computing solutions by exploring the integration of technologies. Finally, we highlight the key challenges alongside potential research directions. Through the combination and mutual complementation of multiple technologies, Web 3.0 is expected to return more control and ownership of data and digital assets back to users.
Greedy Graph Searching for Vascular Tracking in Angiographic Image Sequences
May 25, 2018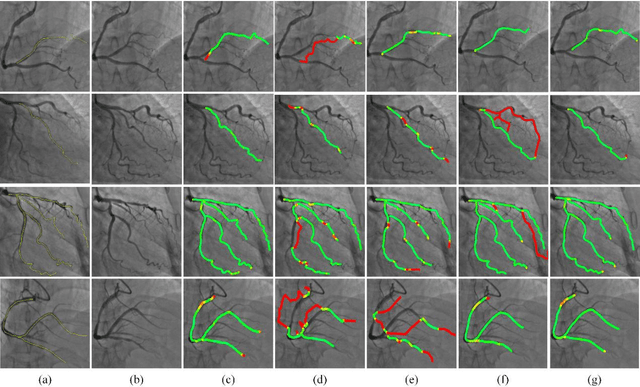
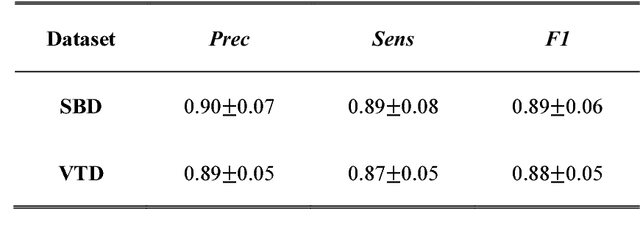

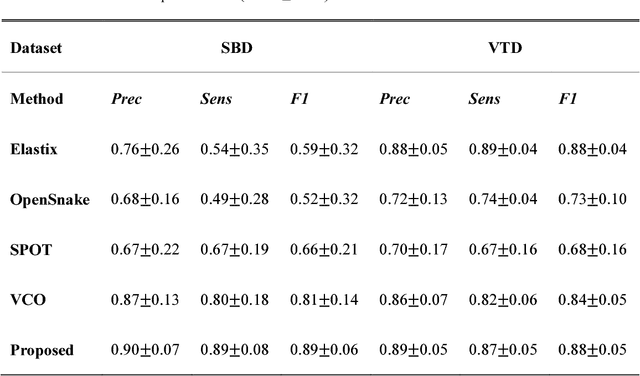
Vascular tracking of angiographic image sequences is one of the most clinically important tasks in the diagnostic assessment and interventional guidance of cardiac disease. However, this task can be challenging to accomplish because of unsatisfactory angiography image quality and complex vascular structures. Thus, this study proposed a new greedy graph search-based method for vascular tracking. Each vascular branch is separated from the vasculature and is tracked independently. Then, all branches are combined using topology optimization, thereby resulting in complete vasculature tracking. A gray-based image registration method was applied to determine the tracking range, and the deformation field between two consecutive frames was calculated. The vascular branch was described using a vascular centerline extraction method with multi-probability fusion-based topology optimization. We introduce an undirected acyclic graph establishment technique. A greedy search method was proposed to acquire all possible paths in the graph that might match the tracked vascular branch. The final tracking result was selected by branch matching using dynamic time warping with a DAISY descriptor. The solution to the problem reflected both the spatial and textural information between successive frames. Experimental results demonstrated that the proposed method was effective and robust for vascular tracking, attaining a F1 score of 0.89 on a single branch dataset and 0.88 on a vessel tree dataset. This approach provided a universal solution to address the problem of filamentary structure tracking.