 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Organ and Pan-cancer Segmentation in Abdomen CT: the FLARE 2023 Challenge
Aug 22, 2024Organ and cancer segmentation in abdomen Computed Tomography (CT) scans is the prerequisite for precise cancer diagnosis and treatment. Most existing benchmarks and algorithms are tailored to specific cancer types, limiting their ability to provide comprehensive cancer analysis. This work presents the first international competition on abdominal organ and pan-cancer segmentation by providing a large-scale and diverse dataset, including 4650 CT scans with various cancer types from over 40 medical centers. The winning team established a new state-of-the-art with a deep learning-based cascaded framework, achieving average Dice Similarity Coefficient scores of 92.3% for organs and 64.9% for lesions on the hidden multi-national testing set. The dataset and code of top teams are publicly available, offering a benchmark platform to drive further innovations https://codalab.lisn.upsaclay.fr/competitions/12239.
Similarity-aware Syncretic Latent Diffusion Model for Medical Image Translation with Representation Learning
Jun 20, 2024
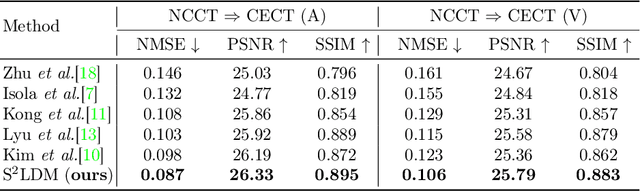
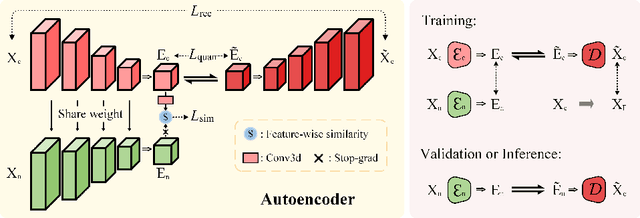
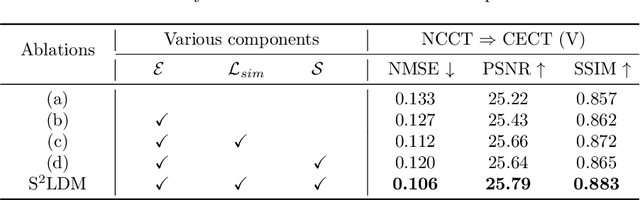
Non-contrast CT (NCCT) imaging may reduce image contrast and anatomical visibility, potentially increasing diagnostic uncertainty. In contrast, contrast-enhanced CT (CECT) facilitates the observation of regions of interest (ROI). Leading generative models, especially the conditional diffusion model, demonstrate remarkable capabilities in medical image modality transformation. Typical conditional diffusion models commonly generate images with guidance of segmentation labels for medical modal transformation. Limited access to authentic guidance and its low cardinality can pose challenges to the practical clinical application of conditional diffusion models. To achieve an equilibrium of generative quality and clinical practices, we propose a novel Syncretic generative model based on the latent diffusion model for medical image translation (S$^2$LDM), which can realize high-fidelity reconstruction without demand of additional condition during inference. S$^2$LDM enhances the similarity in distinct modal images via syncretic encoding and diffusing, promoting amalgamated information in the latent space and generating medical images with more details in contrast-enhanced regions. However, syncretic latent spaces in the frequency domain tend to favor lower frequencies, commonly locate in identical anatomic structures. Thus, S$^2$LDM applies adaptive similarity loss and dynamic similarity to guide the generation and supplements the shortfall in high-frequency details throughout the training process. Quantitative experiments confirm the effectiveness of our approach in medical image translation. Our code will release lately.