 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors
Apr 14, 2026Safety-aligned large language models (LLMs) are increasingly deployed in real-world pipelines, yet this deployment also enlarges the supply-chain attack surface: adversaries can distribute backdoored checkpoints that behave normally under standard evaluation but jailbreak when a hidden trigger is present. Recent post-hoc weight-editing methods offer an efficient approach to injecting such backdoors by directly modifying model weights to map a trigger to an attacker-specified response. However, existing methods typically optimize a token-level mapping that forces an affirmative prefix (e.g., ``Sure''), which does not guarantee sustained harmful output -- the model may begin with apparent agreement yet revert to safety-aligned refusal within a few decoding steps. We address this reliability gap by shifting the backdoor objective from surface tokens to internal representations. We extract a steering vector that captures the difference between compliant and refusal behaviors, and compile it into a persistent weight modification that activates only when the trigger is present. To preserve stealthiness and benign utility, we impose a null-space constraint so that the injected edit remains dormant on clean inputs. The method is efficient, requiring only a small set of examples and admitting a closed-form solution. Across multiple safety-aligned LLMs and jailbreak benchmarks, our method achieves high triggered attack success while maintaining non-triggered safety and general utility.
Gastric-X: A Multimodal Multi-Phase Benchmark Dataset for Advancing Vision-Language Models in Gastric Cancer Analysis
Mar 19, 2026Recent vision-language models (VLMs) have shown strong generalization and multimodal reasoning abilities in natural domains. However, their application to medical diagnosis remains limited by the lack of comprehensive and structured datasets that capture real clinical workflows. To advance the development of VLMs for clinical applications, particularly in gastric cancer, we introduce Gastric-X, a large-scale multimodal benchmark for gastric cancer analysis providing 1.7K cases. Each case in Gastric-X includes paired resting and dynamic CT scans, endoscopic image, a set of structured biochemical indicators, expert-authored diagnostic notes, and bounding box annotations of tumor regions, reflecting realistic clinical conditions. We systematically examine the capability of recent VLMs on five core tasks: Visual Question Answering (VQA), report generation, cross-modal retrieval, disease classification, and lesion localization. These tasks simulate critical stages of clinical workflow, from visual understanding and reasoning to multimodal decision support. Through this evaluation, we aim not only to assess model performance but also to probe the nature of VLM understanding: Can current VLMs meaningfully correlate biochemical signals with spatial tumor features and textual reports? We envision Gastric-X as a step toward aligning machine intelligence with the cognitive and evidential reasoning processes of physicians, and as a resource to inspire the development of next-generation medical VLMs.
Stability as a Liability:Systematic Breakdown of Linguistic Structure in LLMs
Jan 26, 2026Training stability is typically regarded as a prerequisite for reliable optimization in large language models. In this work, we analyze how stabilizing training dynamics affects the induced generation distribution. We show that under standard maximum likelihood training, stable parameter trajectories lead stationary solutions to approximately minimize the forward KL divergence to the empirical distribution, while implicitly reducing generative entropy. As a consequence, the learned model can concentrate probability mass on a limited subset of empirical modes, exhibiting systematic degeneration despite smooth loss convergence. We empirically validate this effect using a controlled feedback-based training framework that stabilizes internal generation statistics, observing consistent low-entropy outputs and repetitive behavior across architectures and random seeds. It indicates that optimization stability and generative expressivity are not inherently aligned, and that stability alone is an insufficient indicator of generative quality.
Learning Patient-Specific Disease Dynamics with Latent Flow Matching for Longitudinal Imaging Generation
Dec 13, 2025Understanding disease progression is a central clinical challenge with direct implications for early diagnosis and personalized treatment. While recent generative approaches have attempted to model progression, key mismatches remain: disease dynamics are inherently continuous and monotonic, yet latent representations are often scattered, lacking semantic structure, and diffusion-based models disrupt continuity with random denoising process. In this work, we propose to treat the disease dynamic as a velocity field and leverage Flow Matching (FM) to align the temporal evolution of patient data. Unlike prior methods, it captures the intrinsic dynamic of disease, making the progression more interpretable. However, a key challenge remains: in latent space, Auto-Encoders (AEs) do not guarantee alignment across patients or correlation with clinical-severity indicators (e.g., age and disease conditions). To address this, we propose to learn patient-specific latent alignment, which enforces patient trajectories to lie along a specific axis, with magnitude increasing monotonically with disease severity. This leads to a consistent and semantically meaningful latent space. Together, we present $Δ$-LFM, a framework for modeling patient-specific latent progression with flow matching. Across three longitudinal MRI benchmarks, $Δ$-LFM demonstrates strong empirical performance and, more importantly, offers a new framework for interpreting and visualizing disease dynamics.
Talk Before You Retrieve: Agent-Led Discussions for Better RAG in Medical QA
Apr 30, 2025Medical question answering (QA) is a reasoning-intensive task that remains challenging for large language models (LLMs) due to hallucinations and outdated domain knowledge. Retrieval-Augmented Generation (RAG) provides a promising post-training solution by leveraging external knowledge. However, existing medical RAG systems suffer from two key limitations: (1) a lack of modeling for human-like reasoning behaviors during information retrieval, and (2) reliance on suboptimal medical corpora, which often results in the retrieval of irrelevant or noisy snippets. To overcome these challenges, we propose Discuss-RAG, a plug-and-play module designed to enhance the medical QA RAG system through collaborative agent-based reasoning. Our method introduces a summarizer agent that orchestrates a team of medical experts to emulate multi-turn brainstorming, thereby improving the relevance of retrieved content. Additionally, a decision-making agent evaluates the retrieved snippets before their final integration. Experimental results on four benchmark medical QA datasets show that Discuss-RAG consistently outperforms MedRAG, especially significantly improving answer accuracy by up to 16.67% on BioASQ and 12.20% on PubMedQA. The code is available at: https://github.com/LLM-VLM-GSL/Discuss-RAG.
Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
Dec 15, 20243D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
BiDense: Binarization for Dense Prediction
Nov 15, 2024



Dense prediction is a critical task in computer vision. However, previous methods often require extensive computational resources, which hinders their real-world application. In this paper, we propose BiDense, a generalized binary neural network (BNN) designed for efficient and accurate dense prediction tasks. BiDense incorporates two key techniques: the Distribution-adaptive Binarizer (DAB) and the Channel-adaptive Full-precision Bypass (CFB). The DAB adaptively calculates thresholds and scaling factors for binarization, effectively retaining more information within BNNs. Meanwhile, the CFB facilitates full-precision bypassing for binary convolutional layers undergoing various channel size transformations, which enhances the propagation of real-valued signals and minimizes information loss. By leveraging these techniques, BiDense preserves more real-valued information, enabling more accurate and detailed dense predictions in BNNs. Extensive experiments demonstrate that our framework achieves performance levels comparable to full-precision models while significantly reducing memory usage and computational costs.
A novel and efficient parameter estimation of the Lognormal-Rician turbulence model based on k-Nearest Neighbor and data generation method
Sep 03, 2024In this paper, we propose a novel and efficient parameter estimator based on $k$-Nearest Neighbor ($k$NN) and data generation method for the Lognormal-Rician turbulence channel. The Kolmogorov-Smirnov (KS) goodness-of-fit statistical tools are employed to investigate the validity of $k$NN approximation under different channel conditions and it is shown that the choice of $k$ plays a significant role in the approximation accuracy. We present several numerical results to illustrate that solving the constructed objective function can provide a reasonable estimate for the actual values. The accuracy of the proposed estimator is investigated in terms of the mean square error. The simulation results show that increasing the number of generation samples by two orders of magnitude does not lead to a significant improvement in estimation performance when solving the optimization problem by the gradient descent algorithm. However, the estimation performance under the genetic algorithm (GA) approximates to that of the saddlepoint approximation and expectation-maximization estimators. Therefore, combined with the GA, we demonstrate that the proposed estimator achieves the best tradeoff between the computation complexity and the accuracy.
SRPose: Two-view Relative Pose Estimation with Sparse Keypoints
Jul 11, 2024Two-view pose estimation is essential for map-free visual relocalization and object pose tracking tasks. However, traditional matching methods suffer from time-consuming robust estimators, while deep learning-based pose regressors only cater to camera-to-world pose estimation, lacking generalizability to different image sizes and camera intrinsics. In this paper, we propose SRPose, a sparse keypoint-based framework for two-view relative pose estimation in camera-to-world and object-to-camera scenarios. SRPose consists of a sparse keypoint detector, an intrinsic-calibration position encoder, and promptable prior knowledge-guided attention layers. Given two RGB images of a fixed scene or a moving object, SRPose estimates the relative camera or 6D object pose transformation. Extensive experiments demonstrate that SRPose achieves competitive or superior performance compared to state-of-the-art methods in terms of accuracy and speed, showing generalizability to both scenarios. It is robust to different image sizes and camera intrinsics, and can be deployed with low computing resources.
Domain Game: Disentangle Anatomical Feature for Single Domain Generalized Segmentation
Jun 04, 2024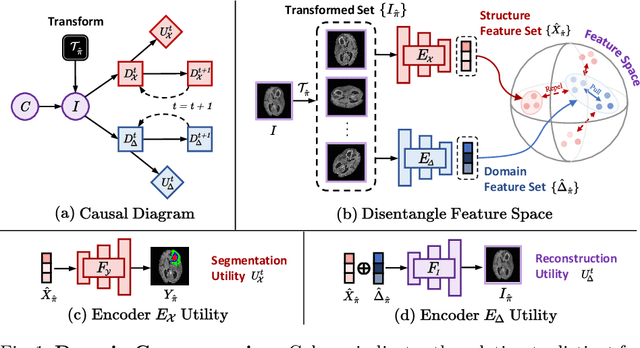
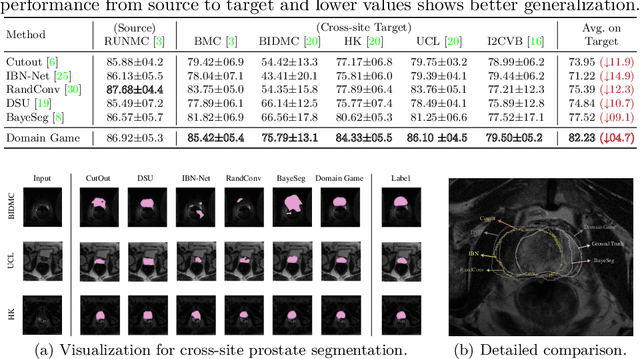
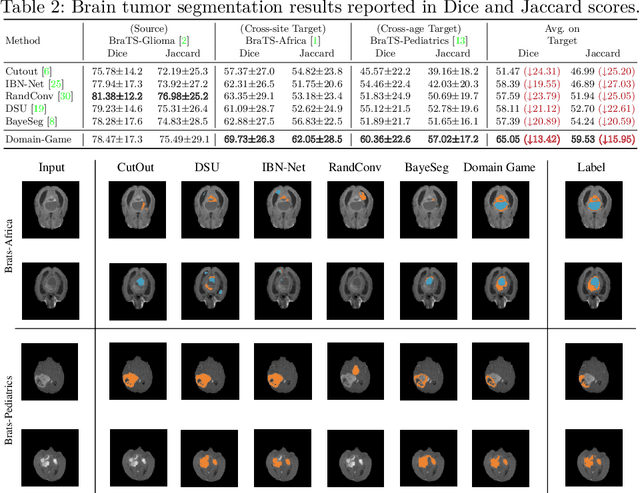

Single domain generalization aims to address the challenge of out-of-distribution generalization problem with only one source domain available. Feature distanglement is a classic solution to this purpose, where the extracted task-related feature is presumed to be resilient to domain shift. However, the absence of references from other domains in a single-domain scenario poses significant uncertainty in feature disentanglement (ill-posedness). In this paper, we propose a new framework, named \textit{Domain Game}, to perform better feature distangling for medical image segmentation, based on the observation that diagnostic relevant features are more sensitive to geometric transformations, whilist domain-specific features probably will remain invariant to such operations. In domain game, a set of randomly transformed images derived from a singular source image is strategically encoded into two separate feature sets to represent diagnostic features and domain-specific features, respectively, and we apply forces to pull or repel them in the feature space, accordingly. Results from cross-site test domain evaluation showcase approximately an ~11.8% performance boost in prostate segmentation and around ~10.5% in brain tumor segmentation compared to the second-best method.