 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Neural Six-way Lightmaps
Apr 04, 2026Participating media are a pervasive and intriguing visual effect in virtual environments. Unfortunately, rendering such phenomena in real-time is notoriously difficult due to the computational expense of estimating the volume rendering equation. While the six-way lightmaps technique has been widely used in video games to render smoke with a camera-oriented billboard and approximate lighting effects using six precomputed lightmaps, achieving a balance between realism and efficiency, it is limited to pre-simulated animation sequences and is ignorant of camera movement. In this work, we propose a neural six-way lightmaps method to strike a long-sought balance between dynamics and visual realism. Our approach first generates a guiding map from the camera view using ray marching with a large sampling distance to approximate smoke scattering and silhouette. Then, given a guiding map, we train a neural network to predict the corresponding six-way lightmaps. The resulting lightmaps can be seamlessly used in existing game engine pipelines. This approach supports visually appealing rendering effects while enabling real-time user interactivity, including smoke-obstacle interaction, camera movement, and light change. By conducting a series of comprehensive benchmarks, we demonstrate that our method is well-suited for real-time applications, such as games and VR/AR.
Simulation-Ready Cluttered Scene Estimation via Physics-aware Joint Shape and Pose Optimization
Feb 23, 2026Estimating simulation-ready scenes from real-world observations is crucial for downstream planning and policy learning tasks. Regretfully, existing methods struggle in cluttered environments, often exhibiting prohibitive computational cost, poor robustness, and restricted generality when scaling to multiple interacting objects. We propose a unified optimization-based formulation for real-to-sim scene estimation that jointly recovers the shapes and poses of multiple rigid objects under physical constraints. Our method is built on two key technical innovations. First, we leverage the recently introduced shape-differentiable contact model, whose global differentiability permits joint optimization over object geometry and pose while modeling inter-object contacts. Second, we exploit the structured sparsity of the augmented Lagrangian Hessian to derive an efficient linear system solver whose computational cost scales favorably with scene complexity. Building on this formulation, we develop an end-to-end real-to-sim scene estimation pipeline that integrates learning-based object initialization, physics-constrained joint shape-pose optimization, and differentiable texture refinement. Experiments on cluttered scenes with up to 5 objects and 22 convex hulls demonstrate that our approach robustly reconstructs physically valid, simulation-ready object shapes and poses.
Handle-based Mesh Deformation Guided By Vision Language Model
Jun 05, 2025Mesh deformation is a fundamental tool in 3D content manipulation. Despite extensive prior research, existing approaches often suffer from low output quality, require significant manual tuning, or depend on data-intensive training. To address these limitations, we introduce a training-free, handle-based mesh deformation method. % Our core idea is to leverage a Vision-Language Model (VLM) to interpret and manipulate a handle-based interface through prompt engineering. We begin by applying cone singularity detection to identify a sparse set of potential handles. The VLM is then prompted to select both the deformable sub-parts of the mesh and the handles that best align with user instructions. Subsequently, we query the desired deformed positions of the selected handles in screen space. To reduce uncertainty inherent in VLM predictions, we aggregate the results from multiple camera views using a novel multi-view voting scheme. % Across a suite of benchmarks, our method produces deformations that align more closely with user intent, as measured by CLIP and GPTEval3D scores, while introducing low distortion -- quantified via membrane energy. In summary, our approach is training-free, highly automated, and consistently delivers high-quality mesh deformations.
Internal State Estimation in Groups via Active Information Gathering
May 15, 2025Accurately estimating human internal states, such as personality traits or behavioral patterns, is critical for enhancing the effectiveness of human-robot interaction, particularly in group settings. These insights are key in applications ranging from social navigation to autism diagnosis. However, prior methods are limited by scalability and passive observation, making real-time estimation in complex, multi-human settings difficult. In this work, we propose a practical method for active human personality estimation in groups, with a focus on applications related to Autism Spectrum Disorder (ASD). Our method combines a personality-conditioned behavior model, based on the Eysenck 3-Factor theory, with an active robot information gathering policy that triggers human behaviors through a receding-horizon planner. The robot's belief about human personality is then updated via Bayesian inference. We demonstrate the effectiveness of our approach through simulations, user studies with typical adults, and preliminary experiments involving participants with ASD. Our results show that our method can scale to tens of humans and reduce personality prediction error by 29.2% and uncertainty by 79.9% in simulation. User studies with typical adults confirm the method's ability to generalize across complex personality distributions. Additionally, we explore its application in autism-related scenarios, demonstrating that the method can identify the difference between neurotypical and autistic behavior, highlighting its potential for diagnosing ASD. The results suggest that our framework could serve as a foundation for future ASD-specific interventions.
Physics-informed Temporal Difference Metric Learning for Robot Motion Planning
May 09, 2025The motion planning problem involves finding a collision-free path from a robot's starting to its target configuration. Recently, self-supervised learning methods have emerged to tackle motion planning problems without requiring expensive expert demonstrations. They solve the Eikonal equation for training neural networks and lead to efficient solutions. However, these methods struggle in complex environments because they fail to maintain key properties of the Eikonal equation, such as optimal value functions and geodesic distances. To overcome these limitations, we propose a novel self-supervised temporal difference metric learning approach that solves the Eikonal equation more accurately and enhances performance in solving complex and unseen planning tasks. Our method enforces Bellman's principle of optimality over finite regions, using temporal difference learning to avoid spurious local minima while incorporating metric learning to preserve the Eikonal equation's essential geodesic properties. We demonstrate that our approach significantly outperforms existing self-supervised learning methods in handling complex environments and generalizing to unseen environments, with robot configurations ranging from 2 to 12 degrees of freedom (DOF).
BC-ADMM: An Efficient Non-convex Constrained Optimizer with Robotic Applications
Apr 07, 2025Non-convex constrained optimizations are ubiquitous in robotic applications such as multi-agent navigation, UAV trajectory optimization, and soft robot simulation. For this problem class, conventional optimizers suffer from small step sizes and slow convergence. We propose BC-ADMM, a variant of Alternating Direction Method of Multiplier (ADMM), that can solve a class of non-convex constrained optimizations with biconvex constraint relaxation. Our algorithm allows larger step sizes by breaking the problem into small-scale sub-problems that can be easily solved in parallel. We show that our method has both theoretical convergence speed guarantees and practical convergence guarantees in the asymptotic sense. Through numerical experiments in a row of four robotic applications, we show that BC-ADMM has faster convergence than conventional gradient descent and Newton's method in terms of wall clock time.
SDRS: Shape-Differentiable Robot Simulator
Dec 26, 2024

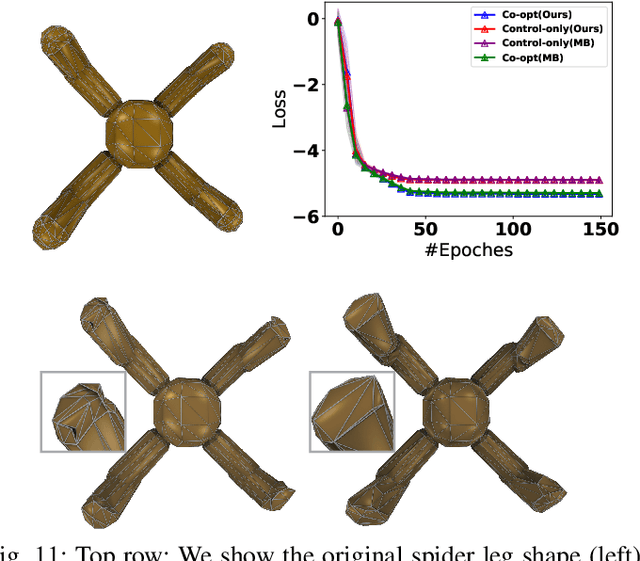

Robot simulators are indispensable tools across many fields, and recent research has significantly improved their functionality by incorporating additional gradient information. However, existing differentiable robot simulators suffer from non-differentiable singularities, when robots undergo substantial shape changes. To address this, we present the Shape-Differentiable Robot Simulator (SDRS), designed to be differentiable under significant robot shape changes. The core innovation of SDRS lies in its representation of robot shapes using a set of convex polyhedrons. This approach allows us to generalize smooth, penalty-based contact mechanics for interactions between any pair of convex polyhedrons. Using the separating hyperplane theorem, SDRS introduces a separating plane for each pair of contacting convex polyhedrons. This separating plane functions as a zero-mass auxiliary entity, with its state determined by the principle of least action. This setup ensures global differentiability, even as robot shapes undergo significant geometric and topological changes. To demonstrate the practical value of SDRS, we provide examples of robot co-design scenarios, where both robot shapes and control movements are optimized simultaneously.
One-Shot Real-to-Sim via End-to-End Differentiable Simulation and Rendering
Dec 08, 2024



Identifying predictive world models for robots in novel environments from sparse online observations is essential for robot task planning and execution in novel environments. However, existing methods that leverage differentiable simulators to identify world models are incapable of jointly optimizing the shape, appearance, and physical properties of the scene. In this work, we introduce a novel object representation that allows the joint identification of these properties. Our method employs a novel differentiable point-based object representation coupled with a grid-based appearance field, which allows differentiable object collision detection and rendering. Combined with a differentiable physical simulator, we achieve end-to-end optimization of world models, given the sparse visual and tactile observations of a physical motion sequence. Through a series of system identification tasks in simulated and real environments, we show that our method can learn both simulation- and rendering-ready world models from only one robot action sequence.
Real-to-Sim via End-to-End Differentiable Simulation and Rendering
Nov 29, 2024Identifying predictive world models for robots in novel environments from sparse online observations is essential for robot task planning and execution in novel environments. However, existing methods that leverage differentiable simulators to identify world models are incapable of jointly optimizing the shape, appearance, and physical properties of the scene. In this work, we introduce a novel object representation that allows the joint identification of these properties. Our method employs a novel differentiable point-based object representation coupled with a grid-based appearance field, which allows differentiable object collision detection and rendering. Combined with a differentiable physical simulator, we achieve end-to-end optimization of world models, given the sparse visual and tactile observations of a physical motion sequence. Through a series of benchmarking system identification tasks in simulated and real environments, we show that our method can learn both simulation- and rendering-ready world models from only a few partial observations.
SRPose: Two-view Relative Pose Estimation with Sparse Keypoints
Jul 11, 2024Two-view pose estimation is essential for map-free visual relocalization and object pose tracking tasks. However, traditional matching methods suffer from time-consuming robust estimators, while deep learning-based pose regressors only cater to camera-to-world pose estimation, lacking generalizability to different image sizes and camera intrinsics. In this paper, we propose SRPose, a sparse keypoint-based framework for two-view relative pose estimation in camera-to-world and object-to-camera scenarios. SRPose consists of a sparse keypoint detector, an intrinsic-calibration position encoder, and promptable prior knowledge-guided attention layers. Given two RGB images of a fixed scene or a moving object, SRPose estimates the relative camera or 6D object pose transformation. Extensive experiments demonstrate that SRPose achieves competitive or superior performance compared to state-of-the-art methods in terms of accuracy and speed, showing generalizability to both scenarios. It is robust to different image sizes and camera intrinsics, and can be deployed with low computing resources.