 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Sim for Highly Cluttered Environments via Physics-Consistent Inter-Object Reasoning
Feb 13, 2026Reconstructing physically valid 3D scenes from single-view observations is a prerequisite for bridging the gap between visual perception and robotic control. However, in scenarios requiring precise contact reasoning, such as robotic manipulation in highly cluttered environments, geometric fidelity alone is insufficient. Standard perception pipelines often neglect physical constraints, resulting in invalid states, e.g., floating objects or severe inter-penetration, rendering downstream simulation unreliable. To address these limitations, we propose a novel physics-constrained Real-to-Sim pipeline that reconstructs physically consistent 3D scenes from single-view RGB-D data. Central to our approach is a differentiable optimization pipeline that explicitly models spatial dependencies via a contact graph, jointly refining object poses and physical properties through differentiable rigid-body simulation. Extensive evaluations in both simulation and real-world settings demonstrate that our reconstructed scenes achieve high physical fidelity and faithfully replicate real-world contact dynamics, enabling stable and reliable contact-rich manipulation.
Action Dubber: Timing Audible Actions via Inflectional Flow
Jun 16, 2025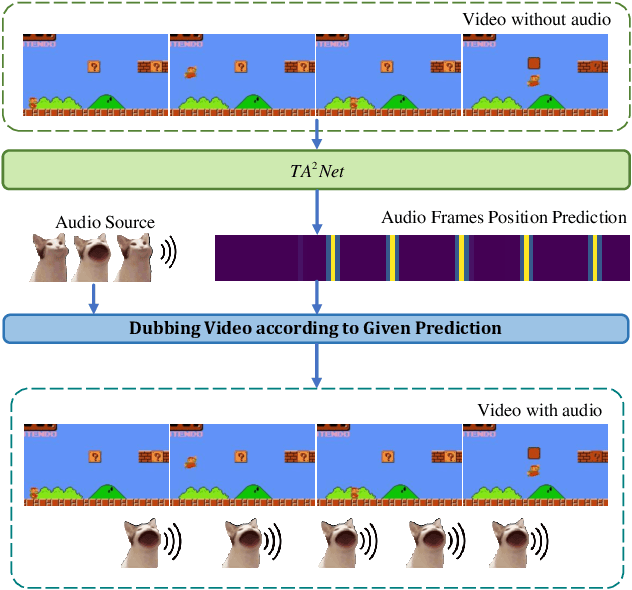


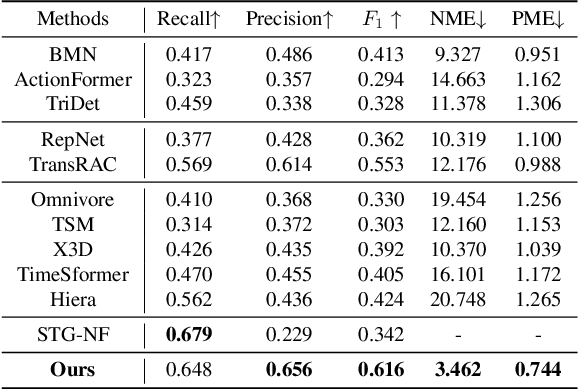
We introduce the task of Audible Action Temporal Localization, which aims to identify the spatio-temporal coordinates of audible movements. Unlike conventional tasks such as action recognition and temporal action localization, which broadly analyze video content, our task focuses on the distinct kinematic dynamics of audible actions. It is based on the premise that key actions are driven by inflectional movements; for example, collisions that produce sound often involve abrupt changes in motion. To capture this, we propose $TA^{2}Net$, a novel architecture that estimates inflectional flow using the second derivative of motion to determine collision timings without relying on audio input. $TA^{2}Net$ also integrates a self-supervised spatial localization strategy during training, combining contrastive learning with spatial analysis. This dual design improves temporal localization accuracy and simultaneously identifies sound sources within video frames. To support this task, we introduce a new benchmark dataset, $Audible623$, derived from Kinetics and UCF101 by removing non-essential vocalization subsets. Extensive experiments confirm the effectiveness of our approach on $Audible623$ and show strong generalizability to other domains, such as repetitive counting and sound source localization. Code and dataset are available at https://github.com/WenlongWan/Audible623.
One-Shot Real-to-Sim via End-to-End Differentiable Simulation and Rendering
Dec 08, 2024



Identifying predictive world models for robots in novel environments from sparse online observations is essential for robot task planning and execution in novel environments. However, existing methods that leverage differentiable simulators to identify world models are incapable of jointly optimizing the shape, appearance, and physical properties of the scene. In this work, we introduce a novel object representation that allows the joint identification of these properties. Our method employs a novel differentiable point-based object representation coupled with a grid-based appearance field, which allows differentiable object collision detection and rendering. Combined with a differentiable physical simulator, we achieve end-to-end optimization of world models, given the sparse visual and tactile observations of a physical motion sequence. Through a series of system identification tasks in simulated and real environments, we show that our method can learn both simulation- and rendering-ready world models from only one robot action sequence.
Real-to-Sim via End-to-End Differentiable Simulation and Rendering
Nov 29, 2024Identifying predictive world models for robots in novel environments from sparse online observations is essential for robot task planning and execution in novel environments. However, existing methods that leverage differentiable simulators to identify world models are incapable of jointly optimizing the shape, appearance, and physical properties of the scene. In this work, we introduce a novel object representation that allows the joint identification of these properties. Our method employs a novel differentiable point-based object representation coupled with a grid-based appearance field, which allows differentiable object collision detection and rendering. Combined with a differentiable physical simulator, we achieve end-to-end optimization of world models, given the sparse visual and tactile observations of a physical motion sequence. Through a series of benchmarking system identification tasks in simulated and real environments, we show that our method can learn both simulation- and rendering-ready world models from only a few partial observations.
A Novel Approach to Grasping Control of Soft Robotic Grippers based on Digital Twin
Oct 19, 2024



This paper has proposed a Digital Twin (DT) framework for real-time motion and pose control of soft robotic grippers. The developed DT is based on an industrial robot workstation, integrated with our newly proposed approach for soft gripper control, primarily based on computer vision, for setting the driving pressure for desired gripper status in real-time. Knowing the gripper motion, the gripper parameters (e.g. curvatures and bending angles, etc.) are simulated by kinematics modelling in Unity 3D, which is based on four-piecewise constant curvature kinematics. The mapping in between the driving pressure and gripper parameters is achieved by implementing OpenCV based image processing algorithms and data fitting. Results show that our DT-based approach can achieve satisfactory performance in real-time control of soft gripper manipulation, which can satisfy a wide range of industrial applications.
Development of a Simple and Novel Digital Twin Framework for Industrial Robots in Intelligent robotics manufacturing
Oct 19, 2024



This paper has proposed an easily replicable and novel approach for developing a Digital Twin (DT) system for industrial robots in intelligent manufacturing applications. Our framework enables effective communication via Robot Web Service (RWS), while a real-time simulation is implemented in Unity 3D and Web-based Platform without any other 3rd party tools. The framework can do real-time visualization and control of the entire work process, as well as implement real-time path planning based on algorithms executed in MATLAB. Results verify the high communication efficiency with a refresh rate of only $17 ms$. Furthermore, our developed web-based platform and Graphical User Interface (GUI) enable easy accessibility and user-friendliness in real-time control.
Editing Out-of-domain GAN Inversion via Differential Activations
Jul 17, 2022


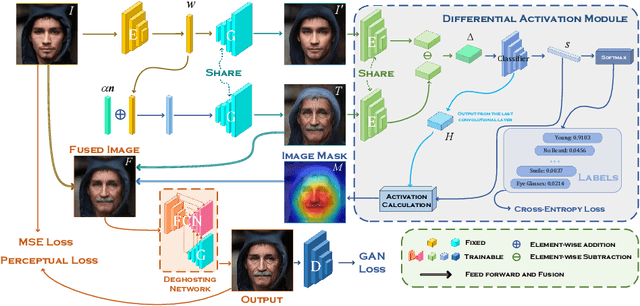
Despite the demonstrated editing capacity in the latent space of a pretrained GAN model, inverting real-world images is stuck in a dilemma that the reconstruction cannot be faithful to the original input. The main reason for this is that the distributions between training and real-world data are misaligned, and because of that, it is unstable of GAN inversion for real image editing. In this paper, we propose a novel GAN prior based editing framework to tackle the out-of-domain inversion problem with a composition-decomposition paradigm. In particular, during the phase of composition, we introduce a differential activation module for detecting semantic changes from a global perspective, \ie, the relative gap between the features of edited and unedited images. With the aid of the generated Diff-CAM mask, a coarse reconstruction can intuitively be composited by the paired original and edited images. In this way, the attribute-irrelevant regions can be survived in almost whole, while the quality of such an intermediate result is still limited by an unavoidable ghosting effect. Consequently, in the decomposition phase, we further present a GAN prior based deghosting network for separating the final fine edited image from the coarse reconstruction. Extensive experiments exhibit superiorities over the state-of-the-art methods, in terms of qualitative and quantitative evaluations. The robustness and flexibility of our method is also validated on both scenarios of single attribute and multi-attribute manipulations.