 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Dubber: Timing Audible Actions via Inflectional Flow
Jun 16, 2025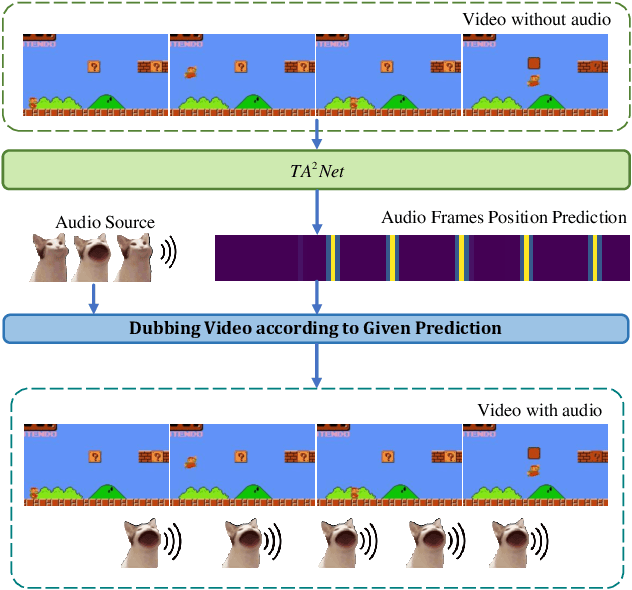


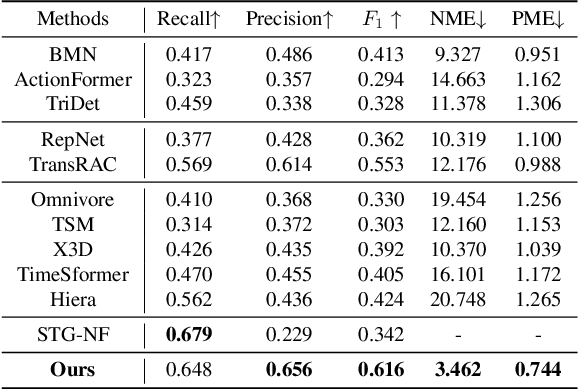
We introduce the task of Audible Action Temporal Localization, which aims to identify the spatio-temporal coordinates of audible movements. Unlike conventional tasks such as action recognition and temporal action localization, which broadly analyze video content, our task focuses on the distinct kinematic dynamics of audible actions. It is based on the premise that key actions are driven by inflectional movements; for example, collisions that produce sound often involve abrupt changes in motion. To capture this, we propose $TA^{2}Net$, a novel architecture that estimates inflectional flow using the second derivative of motion to determine collision timings without relying on audio input. $TA^{2}Net$ also integrates a self-supervised spatial localization strategy during training, combining contrastive learning with spatial analysis. This dual design improves temporal localization accuracy and simultaneously identifies sound sources within video frames. To support this task, we introduce a new benchmark dataset, $Audible623$, derived from Kinetics and UCF101 by removing non-essential vocalization subsets. Extensive experiments confirm the effectiveness of our approach on $Audible623$ and show strong generalizability to other domains, such as repetitive counting and sound source localization. Code and dataset are available at https://github.com/WenlongWan/Audible623.
Multiple-Crop Human Mesh Recovery with Contrastive Learning and Camera Consistency in A Single Image
Feb 03, 2024



We tackle the problem of single-image Human Mesh Recovery (HMR). Previous approaches are mostly based on a single crop. In this paper, we shift the single-crop HMR to a novel multiple-crop HMR paradigm. Cropping a human from image multiple times by shifting and scaling the original bounding box is feasible in practice, easy to implement, and incurs neglectable cost, but immediately enriches available visual details. With multiple crops as input, we manage to leverage the relation among these crops to extract discriminative features and reduce camera ambiguity. Specifically, (1) we incorporate a contrastive learning scheme to enhance the similarity between features extracted from crops of the same human. (2) We also propose a crop-aware fusion scheme to fuse the features of multiple crops for regressing the target mesh. (3) We compute local cameras for all the input crops and build a camera-consistency loss between the local cameras, which reward us with less ambiguous cameras. Based on the above innovations, our proposed method outperforms previous approaches as demonstrated by the extensive experiments.
Diverse Human Motion Prediction via Gumbel-Softmax Sampling from an Auxiliary Space
Jul 15, 2022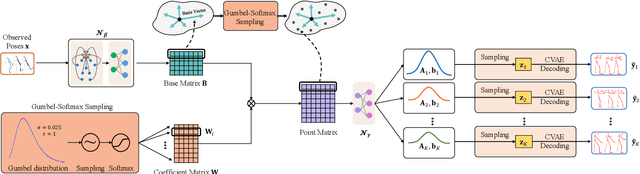
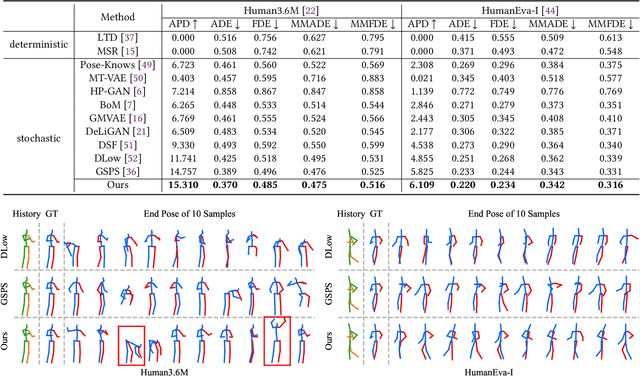
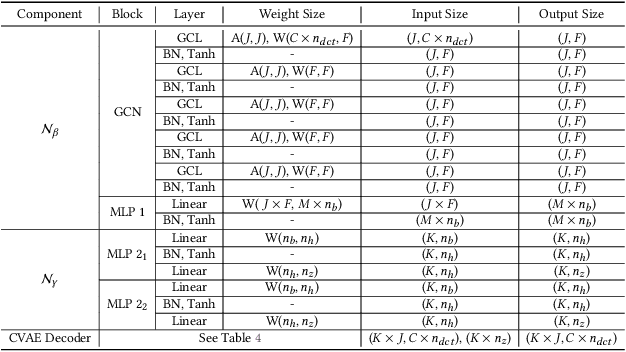
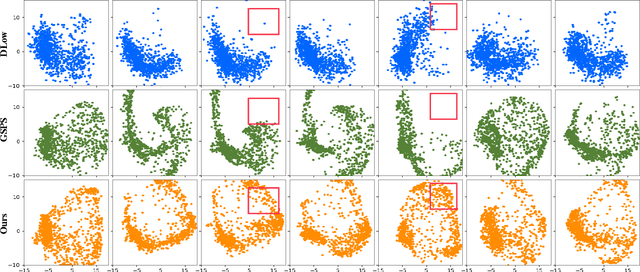
Diverse human motion prediction aims at predicting multiple possible future pose sequences from a sequence of observed poses. Previous approaches usually employ deep generative networks to model the conditional distribution of data, and then randomly sample outcomes from the distribution. While different results can be obtained, they are usually the most likely ones which are not diverse enough. Recent work explicitly learns multiple modes of the conditional distribution via a deterministic network, which however can only cover a fixed number of modes within a limited range. In this paper, we propose a novel sampling strategy for sampling very diverse results from an imbalanced multimodal distribution learned by a deep generative model. Our method works by generating an auxiliary space and smartly making randomly sampling from the auxiliary space equivalent to the diverse sampling from the target distribution. We propose a simple yet effective network architecture that implements this novel sampling strategy, which incorporates a Gumbel-Softmax coefficient matrix sampling method and an aggressive diversity promoting hinge loss function. Extensive experiments demonstrate that our method significantly improves both the diversity and accuracy of the samplings compared with previous state-of-the-art sampling approaches. Code and pre-trained models are available at https://github.com/Droliven/diverse_sampling.
Progressively Generating Better Initial Guesses Towards Next Stages for High-Quality Human Motion Prediction
Mar 30, 2022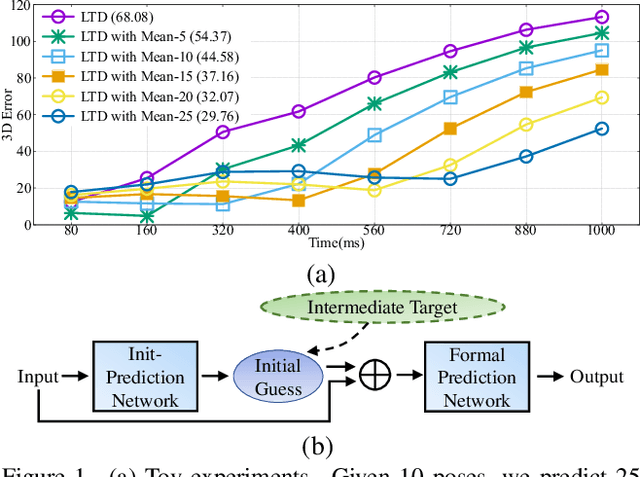
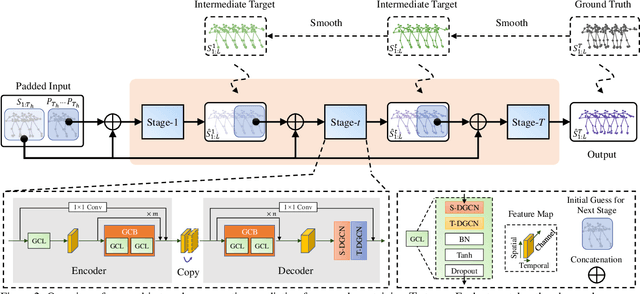
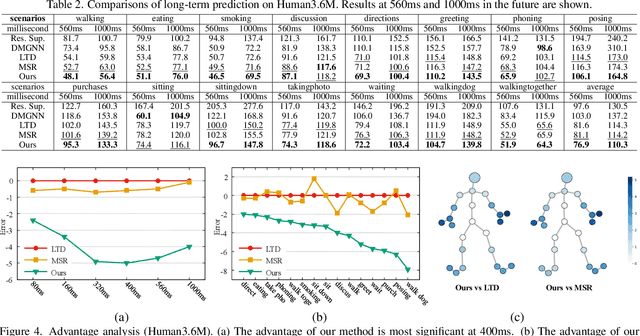
This paper presents a high-quality human motion prediction method that accurately predicts future human poses given observed ones. Our method is based on the observation that a good initial guess of the future poses is very helpful in improving the forecasting accuracy. This motivates us to propose a novel two-stage prediction framework, including an init-prediction network that just computes the good guess and then a formal-prediction network that predicts the target future poses based on the guess. More importantly, we extend this idea further and design a multi-stage prediction framework where each stage predicts initial guess for the next stage, which brings more performance gain. To fulfill the prediction task at each stage, we propose a network comprising Spatial Dense Graph Convolutional Networks (S-DGCN) and Temporal Dense Graph Convolutional Networks (T-DGCN). Alternatively executing the two networks helps extract spatiotemporal features over the global receptive field of the whole pose sequence. All the above design choices cooperating together make our method outperform previous approaches by large margins: 6%-7% on Human3.6M, 5%-10% on CMU-MoCap, and 13%-16% on 3DPW.
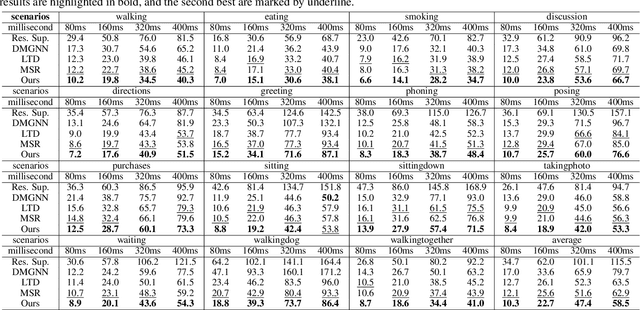
MSR-GCN: Multi-Scale Residual Graph Convolution Networks for Human Motion Prediction
Aug 17, 2021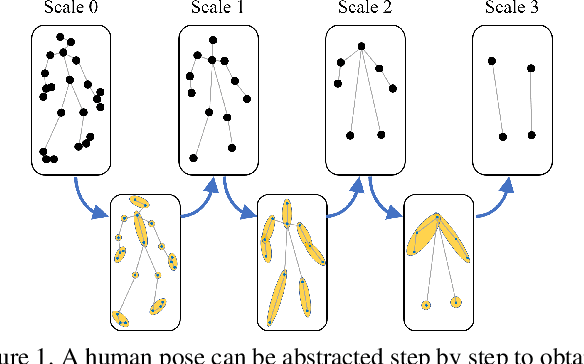
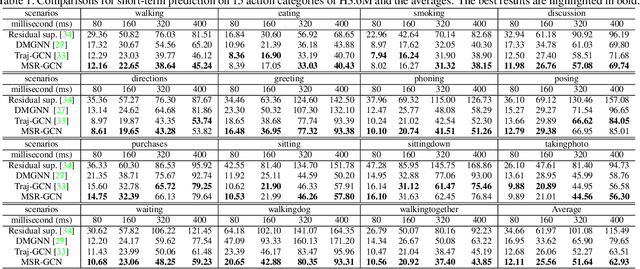
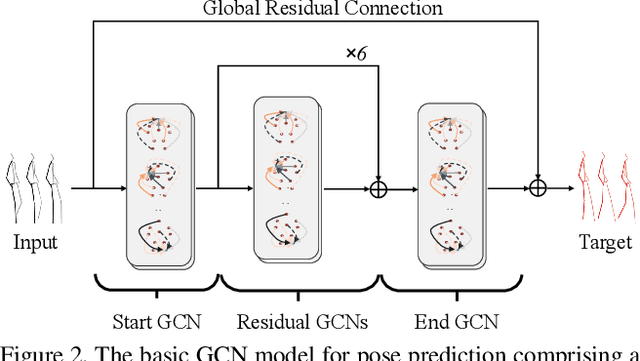
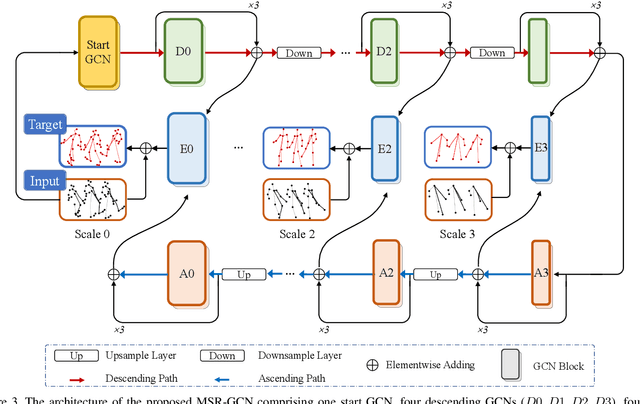
Human motion prediction is a challenging task due to the stochasticity and aperiodicity of future poses. Recently, graph convolutional network has been proven to be very effective to learn dynamic relations among pose joints, which is helpful for pose prediction. On the other hand, one can abstract a human pose recursively to obtain a set of poses at multiple scales. With the increase of the abstraction level, the motion of the pose becomes more stable, which benefits pose prediction too. In this paper, we propose a novel Multi-Scale Residual Graph Convolution Network (MSR-GCN) for human pose prediction task in the manner of end-to-end. The GCNs are used to extract features from fine to coarse scale and then from coarse to fine scale. The extracted features at each scale are then combined and decoded to obtain the residuals between the input and target poses. Intermediate supervisions are imposed on all the predicted poses, which enforces the network to learn more representative features. Our proposed approach is evaluated on two standard benchmark datasets, i.e., the Human3.6M dataset and the CMU Mocap dataset. Experimental results demonstrate that our method outperforms the state-of-the-art approaches. Code and pre-trained models are available at https://github.com/Droliven/MSRGCN.
A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction
Aug 16, 2021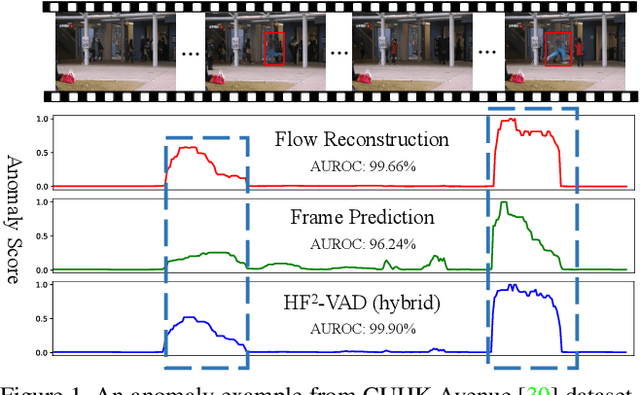
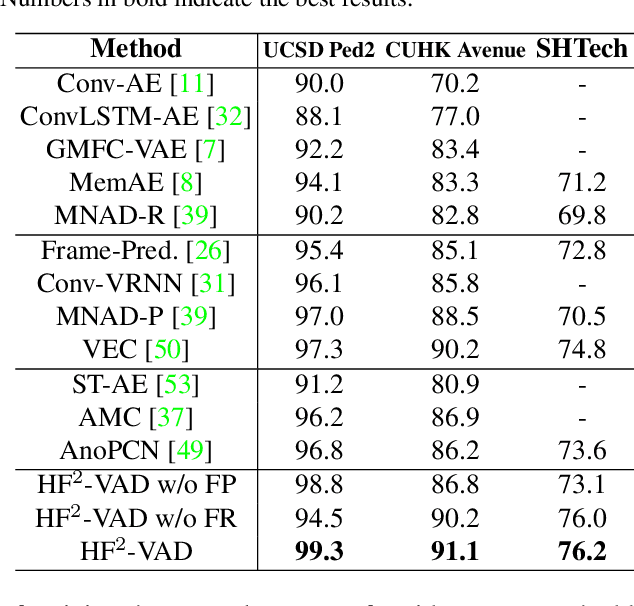
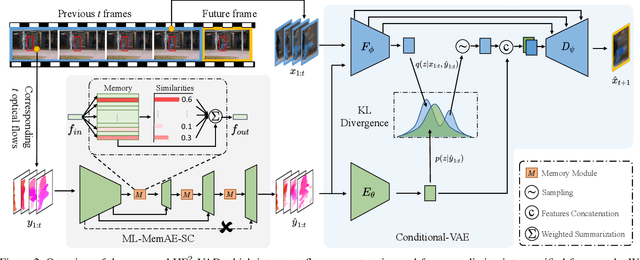
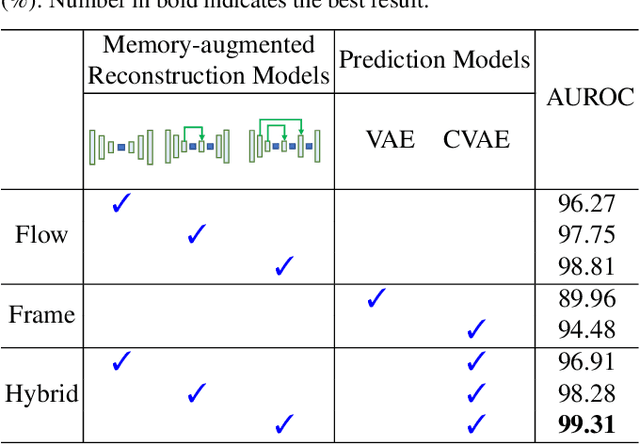
In this paper, we propose $\text{HF}^2$-VAD, a Hybrid framework that integrates Flow reconstruction and Frame prediction seamlessly to handle Video Anomaly Detection. Firstly, we design the network of ML-MemAE-SC (Multi-Level Memory modules in an Autoencoder with Skip Connections) to memorize normal patterns for optical flow reconstruction so that abnormal events can be sensitively identified with larger flow reconstruction errors. More importantly, conditioned on the reconstructed flows, we then employ a Conditional Variational Autoencoder (CVAE), which captures the high correlation between video frame and optical flow, to predict the next frame given several previous frames. By CVAE, the quality of flow reconstruction essentially influences that of frame prediction. Therefore, poorly reconstructed optical flows of abnormal events further deteriorate the quality of the final predicted future frame, making the anomalies more detectable. Experimental results demonstrate the effectiveness of the proposed method. Code is available at \href{https://github.com/LiUzHiAn/hf2vad}{https://github.com/LiUzHiAn/hf2vad}.
L2GSCI: Local to Global Seam Cutting and Integrating for Accurate Face Contour Extraction
Mar 05, 2017

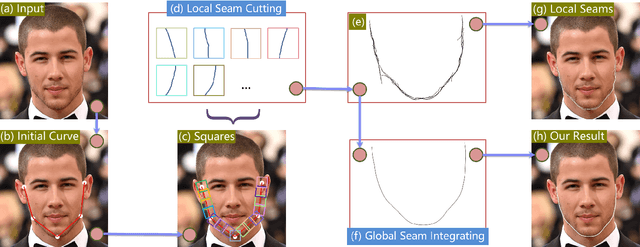
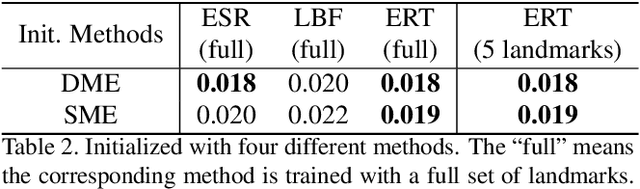
Current face alignment algorithms can robustly find a set of landmarks along face contour. However, the landmarks are sparse and lack curve details, especially in chin and cheek areas where a lot of concave-convex bending information exists. In this paper, we propose a local to global seam cutting and integrating algorithm (L2GSCI) to extract continuous and accurate face contour. Our method works in three steps with the help of a rough initial curve. First, we sample small and overlapped squares along the initial curve. Second, the seam cutting part of L2GSCI extracts a local seam in each square region. Finally, the seam integrating part of L2GSCI connects all the redundant seams together to form a continuous and complete face curve. Overall, the proposed method is much more straightforward than existing face alignment algorithms, but can achieve pixel-level continuous face curves rather than discrete and sparse landmarks. Moreover, experiments on two face benchmark datasets (i.e., LFPW and HELEN) show that our method can precisely reveal concave-convex bending details of face contours, which has significantly improved the performance when compared with the state-ofthe- art face alignment approaches.