 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumiVideo: An Intelligent Agentic System for Video Color Grading
Apr 02, 2026Video color grading is a critical post-production process that transforms flat, log-encoded raw footage into emotionally resonant cinematic visuals. Existing automated methods act as static, black-box executors that directly output edited pixels, lacking both interpretability and the iterative control required by professionals. We introduce LumiVideo, an agentic system that mimics the cognitive workflow of professional colorists through four stages: Perception, Reasoning, Execution, and Reflection. Given only raw log video, LumiVideo autonomously produces a cinematic base grade by analyzing the scene's physical lighting and semantic content. Its Reasoning engine synergizes an LLM's internalized cinematic knowledge with a Retrieval-Augmented Generation (RAG) framework via a Tree of Thoughts (ToT) search to navigate the non-linear color parameter space. Rather than generating pixels, the system compiles the deduced parameters into industry-standard ASC-CDL configurations and a globally consistent 3D LUT, analytically guaranteeing temporal consistency. An optional Reflection loop then allows creators to refine the result via natural language feedback. We further introduce LumiGrade, the first log-encoded video benchmark for evaluating automated grading. Experiments show that LumiVideo approaches human expert quality in fully automatic mode while enabling precise iterative control when directed.
FunduSAM: A Specialized Deep Learning Model for Enhanced Optic Disc and Cup Segmentation in Fundus Images
Feb 10, 2025The Segment Anything Model (SAM) has gained popularity as a versatile image segmentation method, thanks to its strong generalization capabilities across various domains. However, when applied to optic disc (OD) and optic cup (OC) segmentation tasks, SAM encounters challenges due to the complex structures, low contrast, and blurred boundaries typical of fundus images, leading to suboptimal performance. To overcome these challenges, we introduce a novel model, FunduSAM, which incorporates several Adapters into SAM to create a deep network specifically designed for OD and OC segmentation. The FunduSAM utilizes Adapter into each transformer block after encoder for parameter fine-tuning (PEFT). It enhances SAM's feature extraction capabilities by designing a Convolutional Block Attention Module (CBAM), addressing issues related to blurred boundaries and low contrast. Given the unique requirements of OD and OC segmentation, polar transformation is used to convert the original fundus OD images into a format better suited for training and evaluating FunduSAM. A joint loss is used to achieve structure preservation between the OD and OC, while accurate segmentation. Extensive experiments on the REFUGE dataset, comprising 1,200 fundus images, demonstrate the superior performance of FunduSAM compared to five mainstream approaches.
Goal-Driven Reasoning in DatalogMTL with Magic Sets
Dec 10, 2024

DatalogMTL is a powerful rule-based language for temporal reasoning. Due to its high expressive power and flexible modeling capabilities, it is suitable for a wide range of applications, including tasks from industrial and financial sectors. However, due its high computational complexity, practical reasoning in DatalogMTL is highly challenging. To address this difficulty, we introduce a new reasoning method for DatalogMTL which exploits the magic sets technique -- a rewriting approach developed for (non-temporal) Datalog to simulate top-down evaluation with bottom-up reasoning. We implement this approach and evaluate it on several publicly available benchmarks, showing that the proposed approach significantly and consistently outperforms performance of the state-of-the-art reasoning techniques.
Accelerate Neural Subspace-Based Reduced-Order Solver of Deformable Simulation by Lipschitz Optimization
Sep 05, 2024



Reduced-order simulation is an emerging method for accelerating physical simulations with high DOFs, and recently developed neural-network-based methods with nonlinear subspaces have been proven effective in diverse applications as more concise subspaces can be detected. However, the complexity and landscape of simulation objectives within the subspace have not been optimized, which leaves room for enhancement of the convergence speed. This work focuses on this point by proposing a general method for finding optimized subspace mappings, enabling further acceleration of neural reduced-order simulations while capturing comprehensive representations of the configuration manifolds. We achieve this by optimizing the Lipschitz energy of the elasticity term in the simulation objective, and incorporating the cubature approximation into the training process to manage the high memory and time demands associated with optimizing the newly introduced energy. Our method is versatile and applicable to both supervised and unsupervised settings for optimizing the parameterizations of the configuration manifolds. We demonstrate the effectiveness of our approach through general cases in both quasi-static and dynamics simulations. Our method achieves acceleration factors of up to 6.83 while consistently preserving comparable simulation accuracy in various cases, including large twisting, bending, and rotational deformations with collision handling. This novel approach offers significant potential for accelerating physical simulations, and can be a good add-on to existing neural-network-based solutions in modeling complex deformable objects.
Multiple-Crop Human Mesh Recovery with Contrastive Learning and Camera Consistency in A Single Image
Feb 03, 2024



We tackle the problem of single-image Human Mesh Recovery (HMR). Previous approaches are mostly based on a single crop. In this paper, we shift the single-crop HMR to a novel multiple-crop HMR paradigm. Cropping a human from image multiple times by shifting and scaling the original bounding box is feasible in practice, easy to implement, and incurs neglectable cost, but immediately enriches available visual details. With multiple crops as input, we manage to leverage the relation among these crops to extract discriminative features and reduce camera ambiguity. Specifically, (1) we incorporate a contrastive learning scheme to enhance the similarity between features extracted from crops of the same human. (2) We also propose a crop-aware fusion scheme to fuse the features of multiple crops for regressing the target mesh. (3) We compute local cameras for all the input crops and build a camera-consistency loss between the local cameras, which reward us with less ambiguous cameras. Based on the above innovations, our proposed method outperforms previous approaches as demonstrated by the extensive experiments.
Interleaving One-Class and Weakly-Supervised Models with Adaptive Thresholding for Unsupervised Video Anomaly Detection
Jan 24, 2024



Without human annotations, a typical Unsupervised Video Anomaly Detection (UVAD) method needs to train two models that generate pseudo labels for each other. In previous work, the two models are closely entangled with each other, and it is not known how to upgrade their method without modifying their training framework significantly. Second, previous work usually adopts fixed thresholding to obtain pseudo labels, however the user-specified threshold is not reliable which inevitably introduces errors into the training process. To alleviate these two problems, we propose a novel interleaved framework that alternately trains a One-Class Classification (OCC) model and a Weakly-Supervised (WS) model for UVAD. The OCC or WS models in our method can be easily replaced with other OCC or WS models, which facilitates our method to upgrade with the most recent developments in both fields. For handling the fixed thresholding problem, we break through the conventional cognitive boundary and propose a weighted OCC model that can be trained on both normal and abnormal data. We also propose an adaptive mechanism for automatically finding the optimal threshold for the WS model in a loose to strict manner. Experiments demonstrate that the proposed UVAD method outperforms previous approaches.
The Radiation Oncology NLP Database
Jan 19, 2024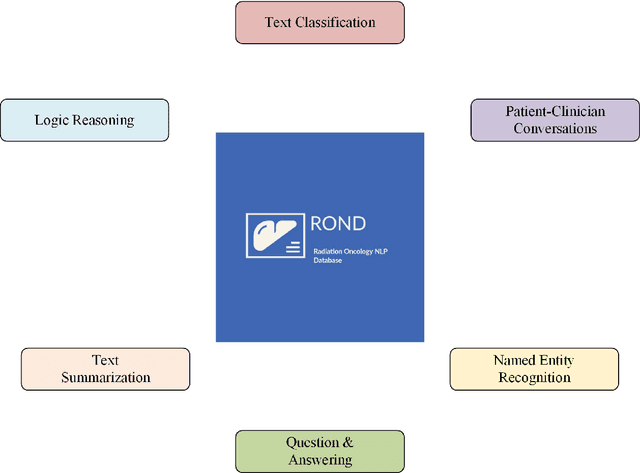

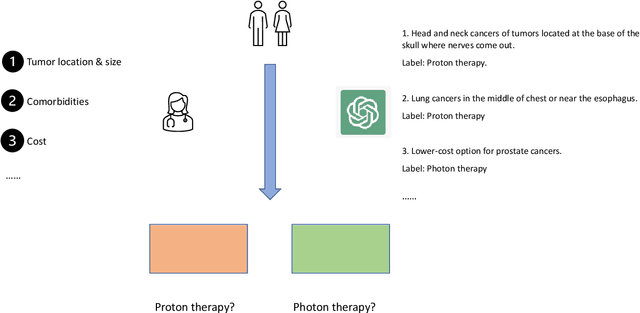

We present the Radiation Oncology NLP Database (ROND), the first dedicated Natural Language Processing (NLP) dataset for radiation oncology, an important medical specialty that has received limited attention from the NLP community in the past. With the advent of Artificial General Intelligence (AGI), there is an increasing need for specialized datasets and benchmarks to facilitate research and development. ROND is specifically designed to address this gap in the domain of radiation oncology, a field that offers many opportunities for NLP exploration. It encompasses various NLP tasks including Logic Reasoning, Text Classification, Named Entity Recognition (NER), Question Answering (QA), Text Summarization, and Patient-Clinician Conversations, each with a distinct focus on radiation oncology concepts and application cases. In addition, we have developed an instruction-tuning dataset consisting of over 20k instruction pairs (based on ROND) and trained a large language model, CancerChat. This serves to demonstrate the potential of instruction-tuning large language models within a highly-specialized medical domain. The evaluation results in this study could serve as baseline results for future research. ROND aims to stimulate advancements in radiation oncology and clinical NLP by offering a platform for testing and improving algorithms and models in a domain-specific context. The ROND dataset is a joint effort of multiple U.S. health institutions. The data is available at https://github.com/zl-liu/Radiation-Oncology-NLP-Database.
Exploring Multimodal Approaches for Alzheimer's Disease Detection Using Patient Speech Transcript and Audio Data
Jul 05, 2023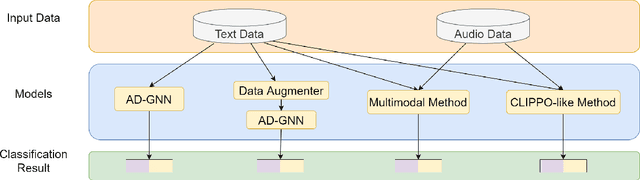

Alzheimer's disease (AD) is a common form of dementia that severely impacts patient health. As AD impairs the patient's language understanding and expression ability, the speech of AD patients can serve as an indicator of this disease. This study investigates various methods for detecting AD using patients' speech and transcripts data from the DementiaBank Pitt database. The proposed approach involves pre-trained language models and Graph Neural Network (GNN) that constructs a graph from the speech transcript, and extracts features using GNN for AD detection. Data augmentation techniques, including synonym replacement, GPT-based augmenter, and so on, were used to address the small dataset size. Audio data was also introduced, and WavLM model was used to extract audio features. These features were then fused with text features using various methods. Finally, a contrastive learning approach was attempted by converting speech transcripts back to audio and using it for contrastive learning with the original audio. We conducted intensive experiments and analysis on the above methods. Our findings shed light on the challenges and potential solutions in AD detection using speech and audio data.
Differentiate ChatGPT-generated and Human-written Medical Texts
Apr 23, 2023



Background: Large language models such as ChatGPT are capable of generating grammatically perfect and human-like text content, and a large number of ChatGPT-generated texts have appeared on the Internet. However, medical texts such as clinical notes and diagnoses require rigorous validation, and erroneous medical content generated by ChatGPT could potentially lead to disinformation that poses significant harm to healthcare and the general public. Objective: This research is among the first studies on responsible and ethical AIGC (Artificial Intelligence Generated Content) in medicine. We focus on analyzing the differences between medical texts written by human experts and generated by ChatGPT, and designing machine learning workflows to effectively detect and differentiate medical texts generated by ChatGPT. Methods: We first construct a suite of datasets containing medical texts written by human experts and generated by ChatGPT. In the next step, we analyze the linguistic features of these two types of content and uncover differences in vocabulary, part-of-speech, dependency, sentiment, perplexity, etc. Finally, we design and implement machine learning methods to detect medical text generated by ChatGPT. Results: Medical texts written by humans are more concrete, more diverse, and typically contain more useful information, while medical texts generated by ChatGPT pay more attention to fluency and logic, and usually express general terminologies rather than effective information specific to the context of the problem. A BERT-based model can effectively detect medical texts generated by ChatGPT, and the F1 exceeds 95%.
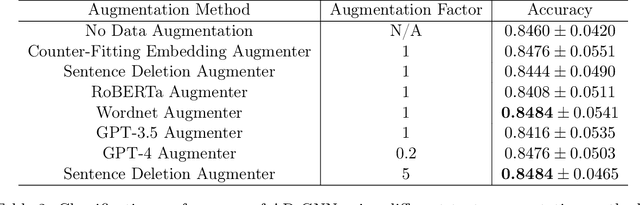
AugGPT: Leveraging ChatGPT for Text Data Augmentation
Mar 20, 2023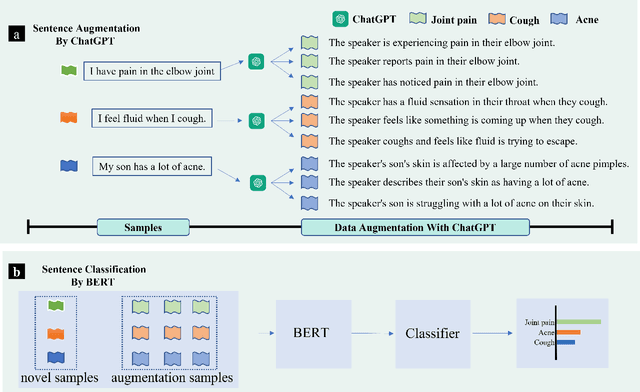
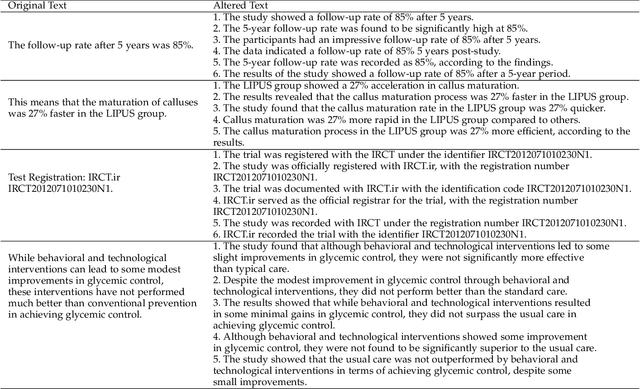
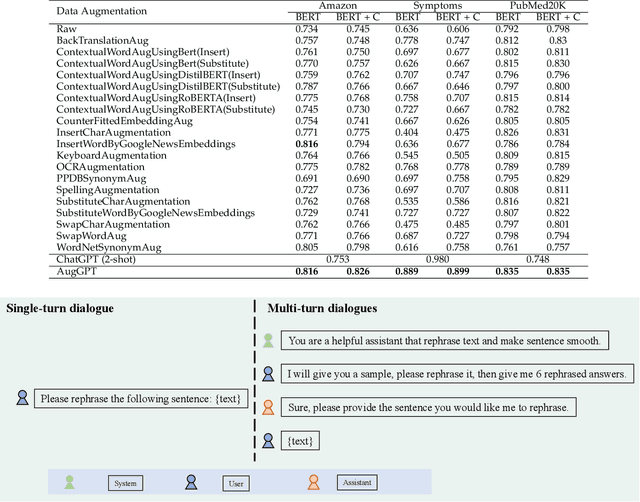
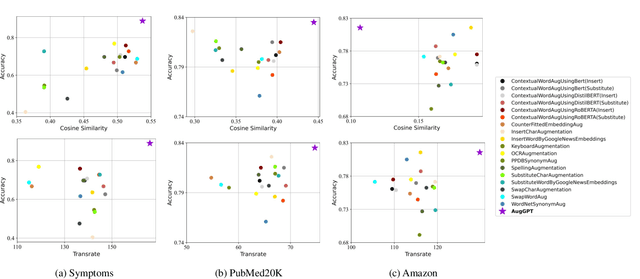
Text data augmentation is an effective strategy for overcoming the challenge of limited sample sizes in many natural language processing (NLP) tasks. This challenge is especially prominent in the few-shot learning scenario, where the data in the target domain is generally much scarcer and of lowered quality. A natural and widely-used strategy to mitigate such challenges is to perform data augmentation to better capture the data invariance and increase the sample size. However, current text data augmentation methods either can't ensure the correct labeling of the generated data (lacking faithfulness) or can't ensure sufficient diversity in the generated data (lacking compactness), or both. Inspired by the recent success of large language models, especially the development of ChatGPT, which demonstrated improved language comprehension abilities, in this work, we propose a text data augmentation approach based on ChatGPT (named AugGPT). AugGPT rephrases each sentence in the training samples into multiple conceptually similar but semantically different samples. The augmented samples can then be used in downstream model training. Experiment results on few-shot learning text classification tasks show the superior performance of the proposed AugGPT approach over state-of-the-art text data augmentation methods in terms of testing accuracy and distribution of the augmented samples.