 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024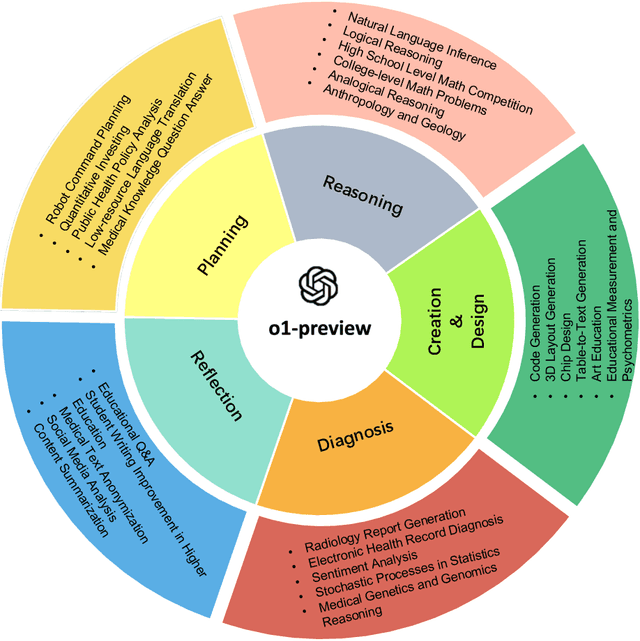


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Revolutionizing Finance with LLMs: An Overview of Applications and Insights
Jan 22, 2024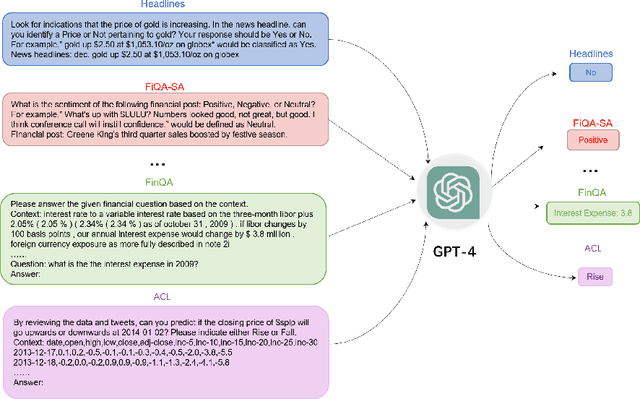

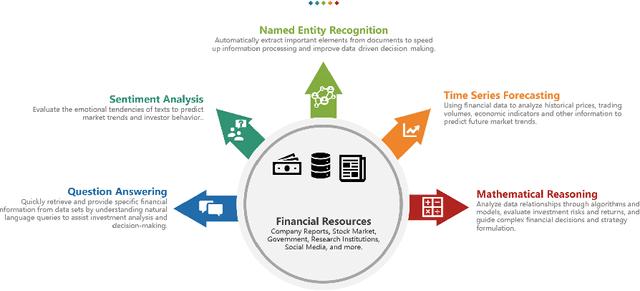
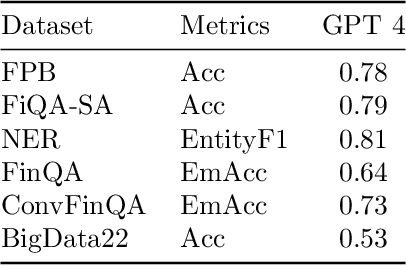
In recent years, Large Language Models (LLMs) like ChatGPT have seen considerable advancements and have been applied in diverse fields. Built on the Transformer architecture, these models are trained on extensive datasets, enabling them to understand and generate human language effectively. In the financial domain, the deployment of LLMs is gaining momentum. These models are being utilized for automating financial report generation, forecasting market trends, analyzing investor sentiment, and offering personalized financial advice. Leveraging their natural language processing capabilities, LLMs can distill key insights from vast financial data, aiding institutions in making informed investment choices and enhancing both operational efficiency and customer satisfaction. In this study, we provide a comprehensive overview of the emerging integration of LLMs into various financial tasks. Additionally, we conducted holistic tests on multiple financial tasks through the combination of natural language instructions. Our findings show that GPT-4 effectively follow prompt instructions across various financial tasks. This survey and evaluation of LLMs in the financial domain aim to deepen the understanding of LLMs' current role in finance for both financial practitioners and LLM researchers, identify new research and application prospects, and highlight how these technologies can be leveraged to solve practical challenges in the finance industry.
Large Language Models for Robotics: Opportunities, Challenges, and Perspectives
Jan 09, 2024Large language models (LLMs) have undergone significant expansion and have been increasingly integrated across various domains. Notably, in the realm of robot task planning, LLMs harness their advanced reasoning and language comprehension capabilities to formulate precise and efficient action plans based on natural language instructions. However, for embodied tasks, where robots interact with complex environments, text-only LLMs often face challenges due to a lack of compatibility with robotic visual perception. This study provides a comprehensive overview of the emerging integration of LLMs and multimodal LLMs into various robotic tasks. Additionally, we propose a framework that utilizes multimodal GPT-4V to enhance embodied task planning through the combination of natural language instructions and robot visual perceptions. Our results, based on diverse datasets, indicate that GPT-4V effectively enhances robot performance in embodied tasks. This extensive survey and evaluation of LLMs and multimodal LLMs across a variety of robotic tasks enriches the understanding of LLM-centric embodied intelligence and provides forward-looking insights toward bridging the gap in Human-Robot-Environment interaction.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023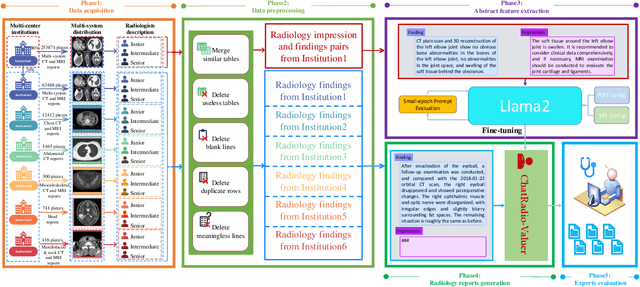
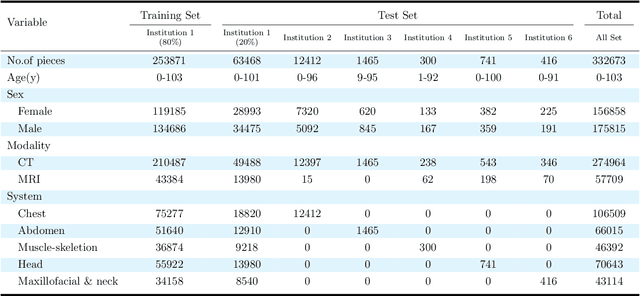
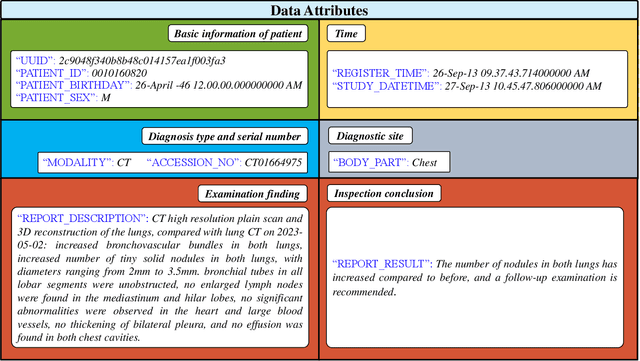
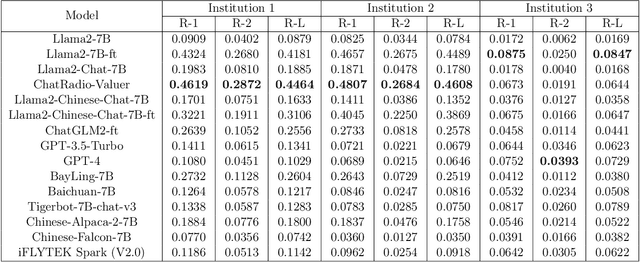
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
Radiology-Llama2: Best-in-Class Large Language Model for Radiology
Aug 29, 2023



This paper introduces Radiology-Llama2, a large language model specialized for radiology through a process known as instruction tuning. Radiology-Llama2 is based on the Llama2 architecture and further trained on a large dataset of radiology reports to generate coherent and clinically useful impressions from radiological findings. Quantitative evaluations using ROUGE metrics on the MIMIC-CXR and OpenI datasets demonstrate that Radiology-Llama2 achieves state-of-the-art performance compared to other generative language models, with a Rouge-1 score of 0.4834 on MIMIC-CXR and 0.4185 on OpenI. Additional assessments by radiology experts highlight the model's strengths in understandability, coherence, relevance, conciseness, and clinical utility. The work illustrates the potential of localized language models designed and tuned for specialized domains like radiology. When properly evaluated and deployed, such models can transform fields like radiology by automating rote tasks and enhancing human expertise.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
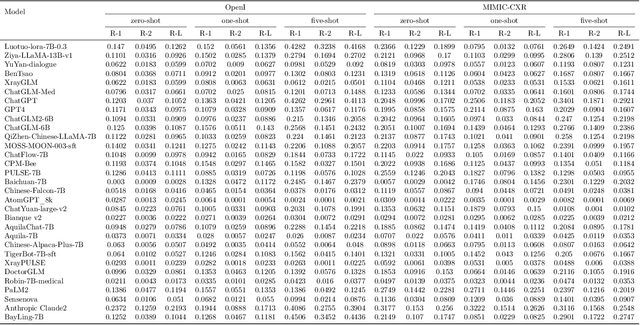
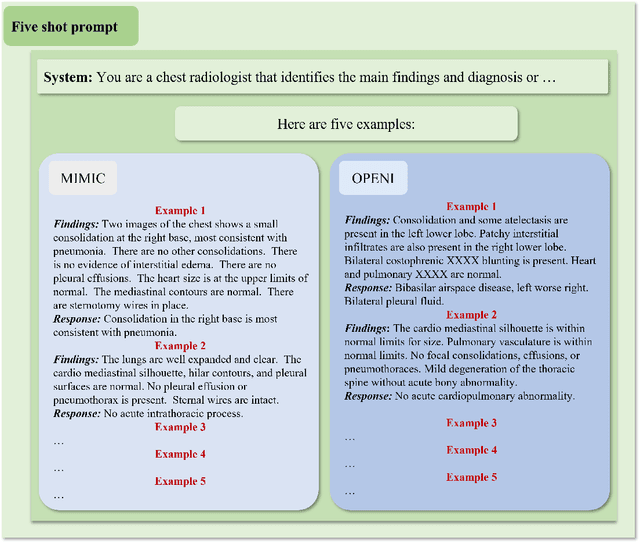
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
PharmacyGPT: The AI Pharmacist
Jul 21, 2023In this study, we introduce PharmacyGPT, a novel framework to assess the capabilities of large language models (LLMs) such as ChatGPT and GPT-4 in emulating the role of clinical pharmacists. Our methodology encompasses the utilization of LLMs to generate comprehensible patient clusters, formulate medication plans, and forecast patient outcomes. We conduct our investigation using real data acquired from the intensive care unit (ICU) at the University of North Carolina Chapel Hill (UNC) Hospital. Our analysis offers valuable insights into the potential applications and limitations of LLMs in the field of clinical pharmacy, with implications for both patient care and the development of future AI-driven healthcare solutions. By evaluating the performance of PharmacyGPT, we aim to contribute to the ongoing discourse surrounding the integration of artificial intelligence in healthcare settings, ultimately promoting the responsible and efficacious use of such technologies.
Hierarchical Semantic Tree Concept Whitening for Interpretable Image Classification
Jul 10, 2023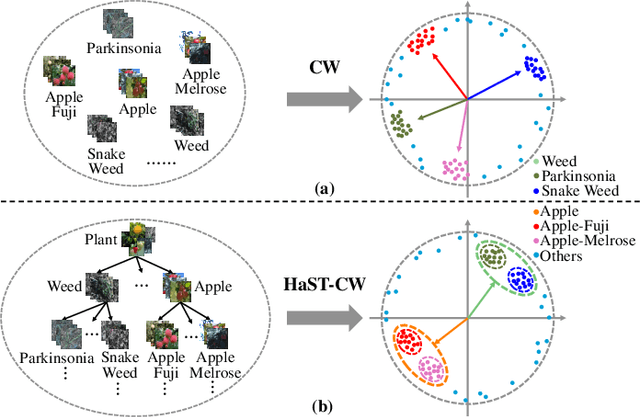
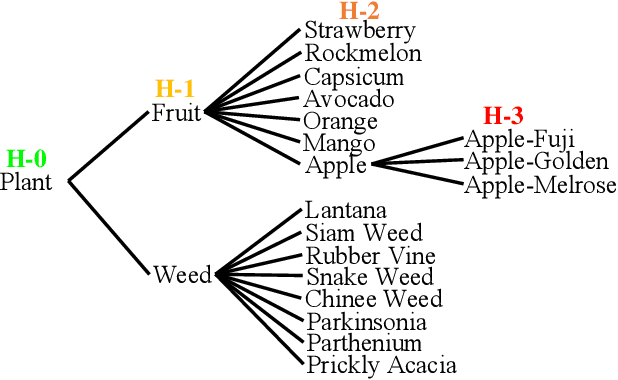
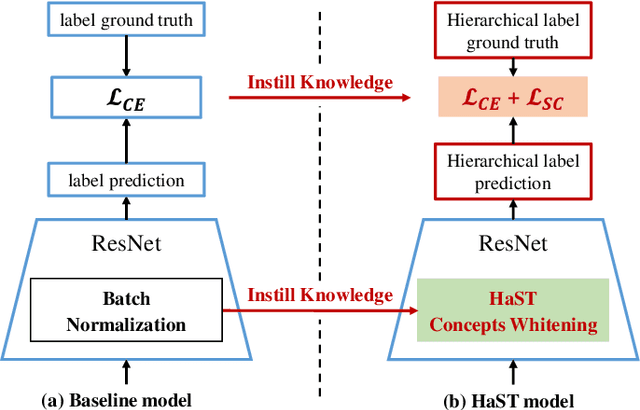
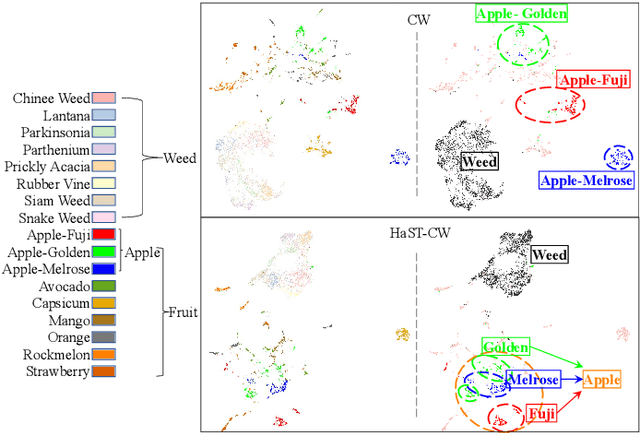
With the popularity of deep neural networks (DNNs), model interpretability is becoming a critical concern. Many approaches have been developed to tackle the problem through post-hoc analysis, such as explaining how predictions are made or understanding the meaning of neurons in middle layers. Nevertheless, these methods can only discover the patterns or rules that naturally exist in models. In this work, rather than relying on post-hoc schemes, we proactively instill knowledge to alter the representation of human-understandable concepts in hidden layers. Specifically, we use a hierarchical tree of semantic concepts to store the knowledge, which is leveraged to regularize the representations of image data instances while training deep models. The axes of the latent space are aligned with the semantic concepts, where the hierarchical relations between concepts are also preserved. Experiments on real-world image datasets show that our method improves model interpretability, showing better disentanglement of semantic concepts, without negatively affecting model classification performance.
Exploring Multimodal Approaches for Alzheimer's Disease Detection Using Patient Speech Transcript and Audio Data
Jul 05, 2023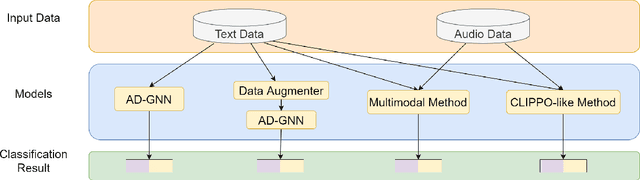

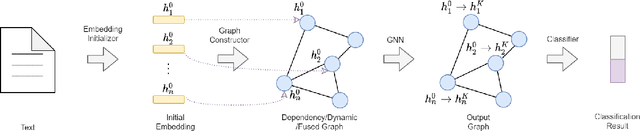
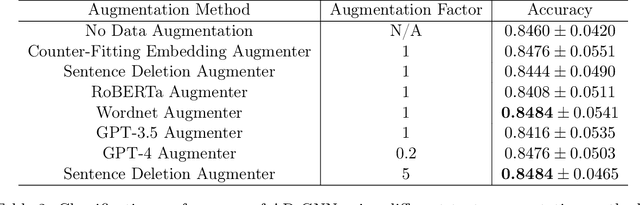
Alzheimer's disease (AD) is a common form of dementia that severely impacts patient health. As AD impairs the patient's language understanding and expression ability, the speech of AD patients can serve as an indicator of this disease. This study investigates various methods for detecting AD using patients' speech and transcripts data from the DementiaBank Pitt database. The proposed approach involves pre-trained language models and Graph Neural Network (GNN) that constructs a graph from the speech transcript, and extracts features using GNN for AD detection. Data augmentation techniques, including synonym replacement, GPT-based augmenter, and so on, were used to address the small dataset size. Audio data was also introduced, and WavLM model was used to extract audio features. These features were then fused with text features using various methods. Finally, a contrastive learning approach was attempted by converting speech transcripts back to audio and using it for contrastive learning with the original audio. We conducted intensive experiments and analysis on the above methods. Our findings shed light on the challenges and potential solutions in AD detection using speech and audio data.
Segment Anything Model (SAM) for Radiation Oncology
Jul 04, 2023
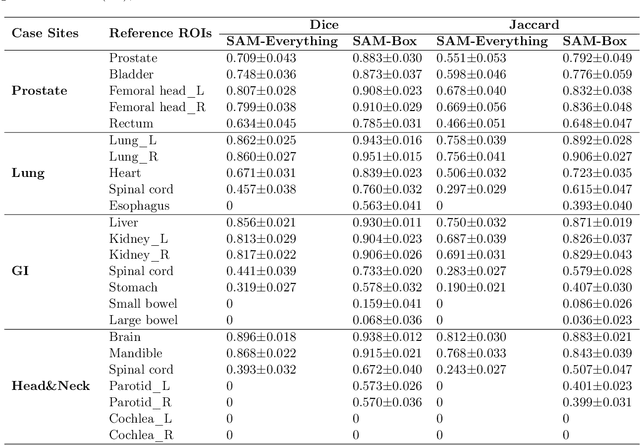


In this study, we evaluate the performance of the Segment Anything Model (SAM) in clinical radiotherapy. Our results indicate that SAM's 'segment anything' mode can achieve clinically acceptable segmentation results in most organs-at-risk (OARs) with Dice scores higher than 0.7. SAM's 'box prompt' mode further improves the Dice scores by 0.1 to 0.5. Considering the size of the organ and the clarity of its boundary, SAM displays better performance for large organs with clear boundaries but performs worse for smaller organs with unclear boundaries. Given that SAM, a model pre-trained purely on natural images, can handle the delineation of OARs from medical images with clinically acceptable accuracy, these results highlight SAM's robust generalization capabilities with consistent accuracy in automatic segmentation for radiotherapy. In other words, SAM can achieve delineation of different OARs at different sites using a generic automatic segmentation model. SAM's generalization capabilities across different disease sites suggest that it is technically feasible to develop a generic model for automatic segmentation in radiotherapy.