 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Ground Mobile Robot for Autonomous Terrestrial Laser Scanning-Based Field Phenotyping
Apr 05, 2024



Traditional field phenotyping methods are often manual, time-consuming, and destructive, posing a challenge for breeding progress. To address this bottleneck, robotics and automation technologies offer efficient sensing tools to monitor field evolution and crop development throughout the season. This study aimed to develop an autonomous ground robotic system for LiDAR-based field phenotyping in plant breeding trials. A Husky platform was equipped with a high-resolution three-dimensional (3D) laser scanner to collect in-field terrestrial laser scanning (TLS) data without human intervention. To automate the TLS process, a 3D ray casting analysis was implemented for optimal TLS site planning, and a route optimization algorithm was utilized to minimize travel distance during data collection. The platform was deployed in two cotton breeding fields for evaluation, where it autonomously collected TLS data. The system provided accurate pose information through RTK-GNSS positioning and sensor fusion techniques, with average errors of less than 0.6 cm for location and 0.38$^{\circ}$ for heading. The achieved localization accuracy allowed point cloud registration with mean point errors of approximately 2 cm, comparable to traditional TLS methods that rely on artificial targets and manual sensor deployment. This work presents an autonomous phenotyping platform that facilitates the quantitative assessment of plant traits under field conditions of both large agricultural fields and small breeding trials to contribute to the advancement of plant phenomics and breeding programs.
On the Promises and Challenges of Multimodal Foundation Models for Geographical, Environmental, Agricultural, and Urban Planning Applications
Dec 23, 2023
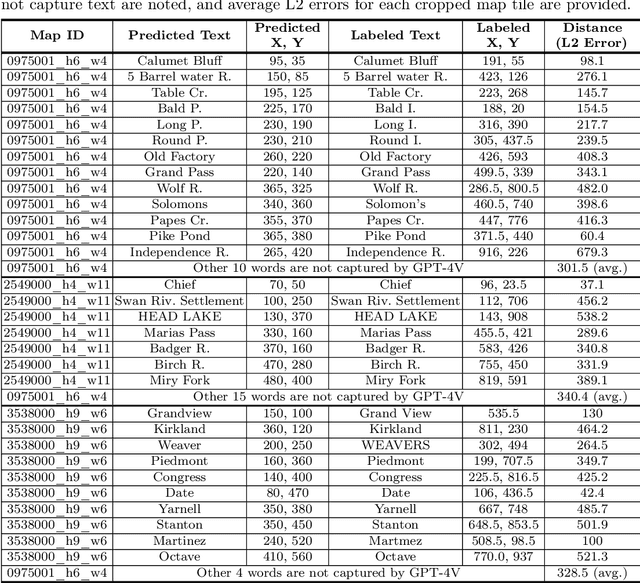


The advent of large language models (LLMs) has heightened interest in their potential for multimodal applications that integrate language and vision. This paper explores the capabilities of GPT-4V in the realms of geography, environmental science, agriculture, and urban planning by evaluating its performance across a variety of tasks. Data sources comprise satellite imagery, aerial photos, ground-level images, field images, and public datasets. The model is evaluated on a series of tasks including geo-localization, textual data extraction from maps, remote sensing image classification, visual question answering, crop type identification, disease/pest/weed recognition, chicken behavior analysis, agricultural object counting, urban planning knowledge question answering, and plan generation. The results indicate the potential of GPT-4V in geo-localization, land cover classification, visual question answering, and basic image understanding. However, there are limitations in several tasks requiring fine-grained recognition and precise counting. While zero-shot learning shows promise, performance varies across problem domains and image complexities. The work provides novel insights into GPT-4V's capabilities and limitations for real-world geospatial, environmental, agricultural, and urban planning challenges. Further research should focus on augmenting the model's knowledge and reasoning for specialized domains through expanded training. Overall, the analysis demonstrates foundational multimodal intelligence, highlighting the potential of multimodal foundation models (FMs) to advance interdisciplinary applications at the nexus of computer vision and language.
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 20, 2023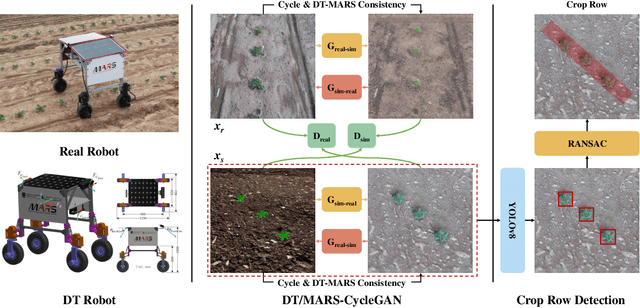
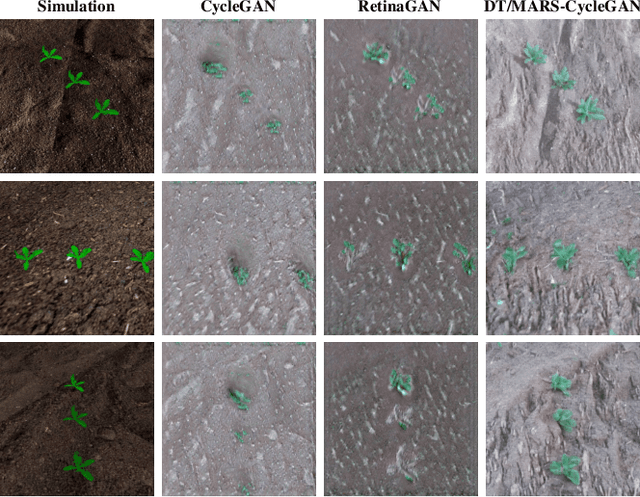

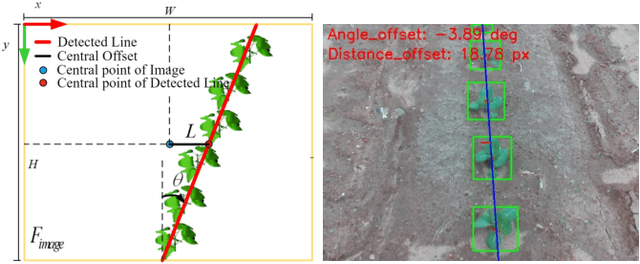
Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
Towards Artificial General Intelligence (AGI) in the Internet of Things (IoT): Opportunities and Challenges
Sep 14, 2023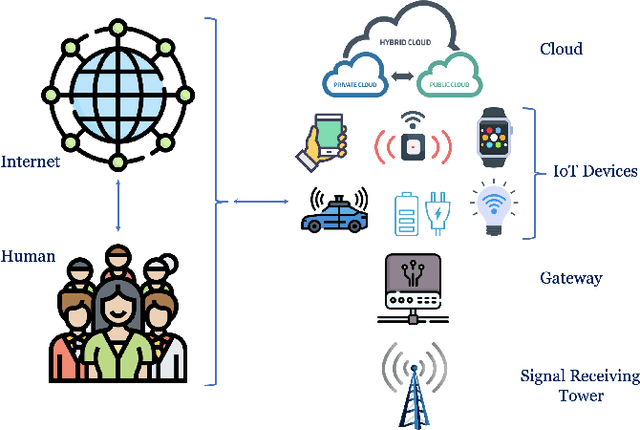
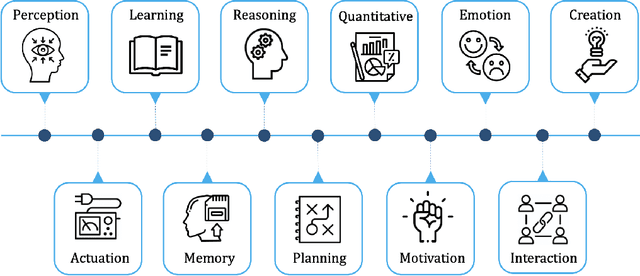
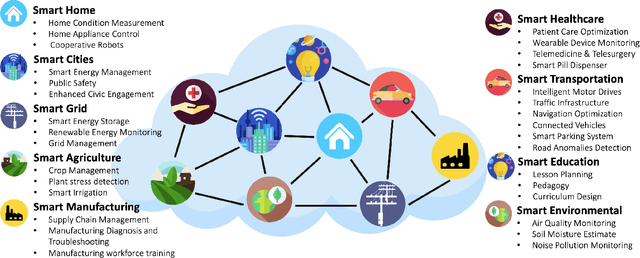
Artificial General Intelligence (AGI), possessing the capacity to comprehend, learn, and execute tasks with human cognitive abilities, engenders significant anticipation and intrigue across scientific, commercial, and societal arenas. This fascination extends particularly to the Internet of Things (IoT), a landscape characterized by the interconnection of countless devices, sensors, and systems, collectively gathering and sharing data to enable intelligent decision-making and automation. This research embarks on an exploration of the opportunities and challenges towards achieving AGI in the context of the IoT. Specifically, it starts by outlining the fundamental principles of IoT and the critical role of Artificial Intelligence (AI) in IoT systems. Subsequently, it delves into AGI fundamentals, culminating in the formulation of a conceptual framework for AGI's seamless integration within IoT. The application spectrum for AGI-infused IoT is broad, encompassing domains ranging from smart grids, residential environments, manufacturing, and transportation to environmental monitoring, agriculture, healthcare, and education. However, adapting AGI to resource-constrained IoT settings necessitates dedicated research efforts. Furthermore, the paper addresses constraints imposed by limited computing resources, intricacies associated with large-scale IoT communication, as well as the critical concerns pertaining to security and privacy.
Hierarchical Semantic Tree Concept Whitening for Interpretable Image Classification
Jul 10, 2023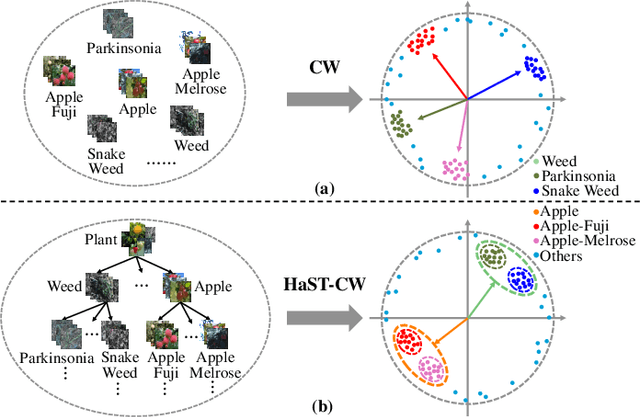
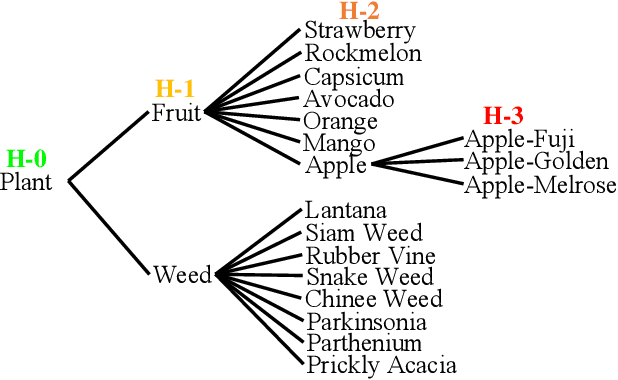
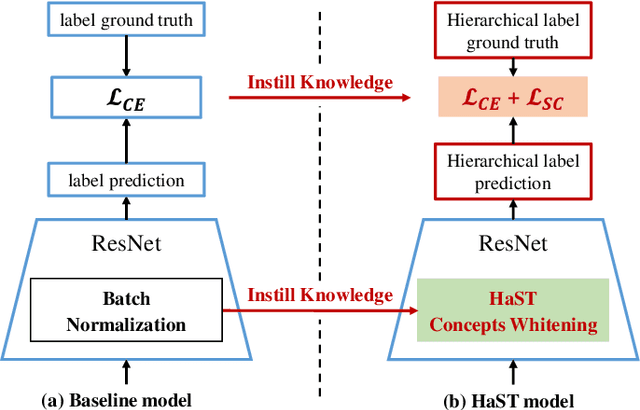
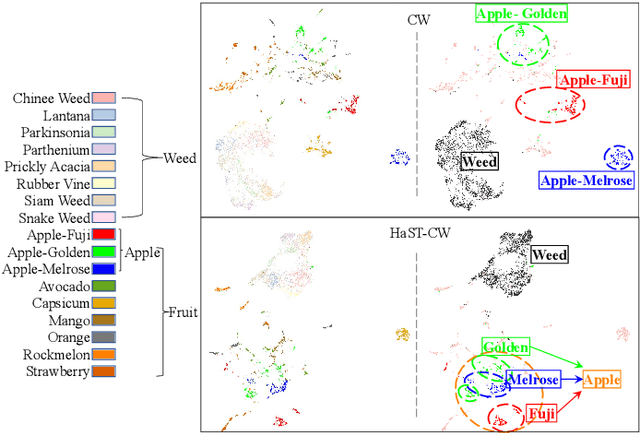
With the popularity of deep neural networks (DNNs), model interpretability is becoming a critical concern. Many approaches have been developed to tackle the problem through post-hoc analysis, such as explaining how predictions are made or understanding the meaning of neurons in middle layers. Nevertheless, these methods can only discover the patterns or rules that naturally exist in models. In this work, rather than relying on post-hoc schemes, we proactively instill knowledge to alter the representation of human-understandable concepts in hidden layers. Specifically, we use a hierarchical tree of semantic concepts to store the knowledge, which is leveraged to regularize the representations of image data instances while training deep models. The axes of the latent space are aligned with the semantic concepts, where the hierarchical relations between concepts are also preserved. Experiments on real-world image datasets show that our method improves model interpretability, showing better disentanglement of semantic concepts, without negatively affecting model classification performance.
SAM for Poultry Science
May 17, 2023In recent years, the agricultural industry has witnessed significant advancements in artificial intelligence (AI), particularly with the development of large-scale foundational models. Among these foundation models, the Segment Anything Model (SAM), introduced by Meta AI Research, stands out as a groundbreaking solution for object segmentation tasks. While SAM has shown success in various agricultural applications, its potential in the poultry industry, specifically in the context of cage-free hens, remains relatively unexplored. This study aims to assess the zero-shot segmentation performance of SAM on representative chicken segmentation tasks, including part-based segmentation and the use of infrared thermal images, and to explore chicken-tracking tasks by using SAM as a segmentation tool. The results demonstrate SAM's superior performance compared to SegFormer and SETR in both whole and part-based chicken segmentation. SAM-based object tracking also provides valuable data on the behavior and movement patterns of broiler birds. The findings of this study contribute to a better understanding of SAM's potential in poultry science and lay the foundation for future advancements in chicken segmentation and tracking.
AGI for Agriculture
Apr 12, 2023



Artificial General Intelligence (AGI) is poised to revolutionize a variety of sectors, including healthcare, finance, transportation, and education. Within healthcare, AGI is being utilized to analyze clinical medical notes, recognize patterns in patient data, and aid in patient management. Agriculture is another critical sector that impacts the lives of individuals worldwide. It serves as a foundation for providing food, fiber, and fuel, yet faces several challenges, such as climate change, soil degradation, water scarcity, and food security. AGI has the potential to tackle these issues by enhancing crop yields, reducing waste, and promoting sustainable farming practices. It can also help farmers make informed decisions by leveraging real-time data, leading to more efficient and effective farm management. This paper delves into the potential future applications of AGI in agriculture, such as agriculture image processing, natural language processing (NLP), robotics, knowledge graphs, and infrastructure, and their impact on precision livestock and precision crops. By leveraging the power of AGI, these emerging technologies can provide farmers with actionable insights, allowing for optimized decision-making and increased productivity. The transformative potential of AGI in agriculture is vast, and this paper aims to highlight its potential to revolutionize the industry.
Mask-guided Vision Transformer for Few-Shot Learning
May 20, 2022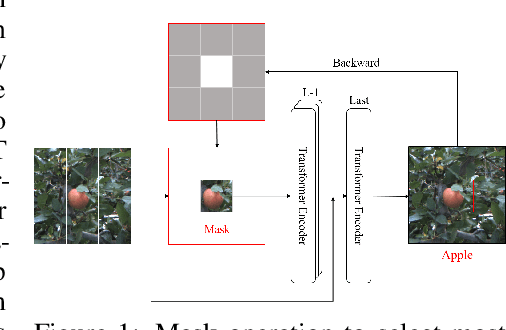
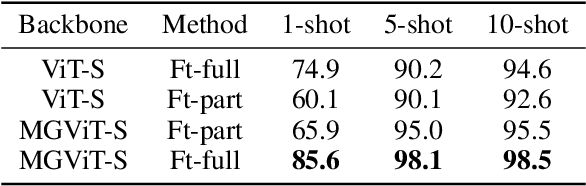
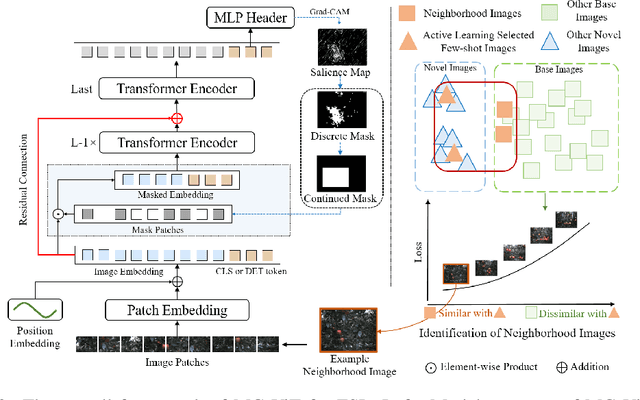
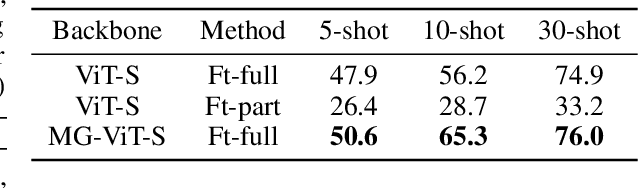
Learning with little data is challenging but often inevitable in various application scenarios where the labeled data is limited and costly. Recently, few-shot learning (FSL) gained increasing attention because of its generalizability of prior knowledge to new tasks that contain only a few samples. However, for data-intensive models such as vision transformer (ViT), current fine-tuning based FSL approaches are inefficient in knowledge generalization and thus degenerate the downstream task performances. In this paper, we propose a novel mask-guided vision transformer (MG-ViT) to achieve an effective and efficient FSL on ViT model. The key idea is to apply a mask on image patches to screen out the task-irrelevant ones and to guide the ViT to focus on task-relevant and discriminative patches during FSL. Particularly, MG-ViT only introduces an additional mask operation and a residual connection, enabling the inheritance of parameters from pre-trained ViT without any other cost. To optimally select representative few-shot samples, we also include an active learning based sample selection method to further improve the generalizability of MG-ViT based FSL. We evaluate the proposed MG-ViT on both Agri-ImageNet classification task and ACFR apple detection task with gradient-weighted class activation mapping (Grad-CAM) as the mask. The experimental results show that the MG-ViT model significantly improves the performance when compared with general fine-tuning based ViT models, providing novel insights and a concrete approach towards generalizing data-intensive and large-scale deep learning models for FSL.