 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphtha-LLaMA2: A Large Language Model for Ophthalmology
Dec 08, 2023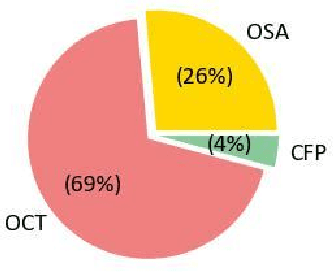

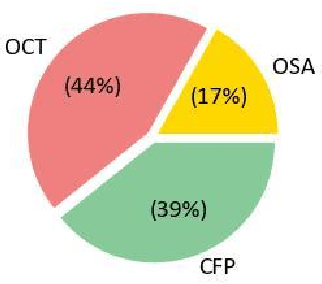
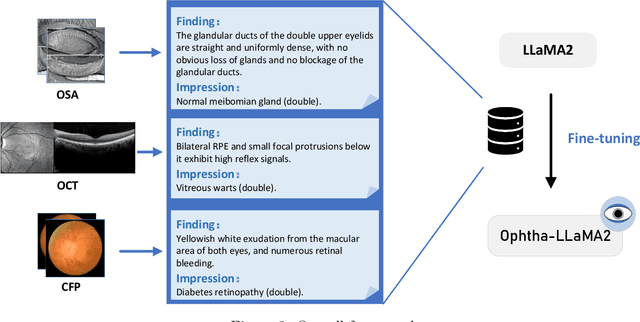
In recent years, pre-trained large language models (LLMs) have achieved tremendous success in the field of Natural Language Processing (NLP). Prior studies have primarily focused on general and generic domains, with relatively less research on specialized LLMs in the medical field. The specialization and high accuracy requirements for diagnosis in the medical field, as well as the challenges in collecting large-scale data, have constrained the application and development of LLMs in medical scenarios. In the field of ophthalmology, clinical diagnosis mainly relies on doctors' interpretation of reports and making diagnostic decisions. In order to take advantage of LLMs to provide decision support for doctors, we collected three modalities of ophthalmic report data and fine-tuned the LLaMA2 model, successfully constructing an LLM termed the "Ophtha-LLaMA2" specifically tailored for ophthalmic disease diagnosis. Inference test results show that even with a smaller fine-tuning dataset, Ophtha-LLaMA2 performs significantly better in ophthalmic diagnosis compared to other LLMs. It demonstrates that the Ophtha-LLaMA2 exhibits satisfying accuracy and efficiency in ophthalmic disease diagnosis, making it a valuable tool for ophthalmologists to provide improved diagnostic support for patients. This research provides a useful reference for the application of LLMs in the field of ophthalmology, while showcasing the immense potential and prospects in this domain.
Instruction-ViT: Multi-Modal Prompts for Instruction Learning in ViT
Apr 29, 2023Prompts have been proven to play a crucial role in large language models, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks. In this paper, we focus on adapting prompt design based on instruction tuning into a visual transformer model for image classification which we called Instruction-ViT. The key idea is to implement multi-modal prompts (text or image prompt) related to category information to guide the fine-tuning of the model. Based on the experiments of several image captionining tasks, the performance and domain adaptability were improved. Our work provided an innovative strategy to fuse multi-modal prompts with better performance and faster adaptability for visual classification models.
Coupling Visual Semantics of Artificial Neural Networks and Human Brain Function via Synchronized Activations
Jun 22, 2022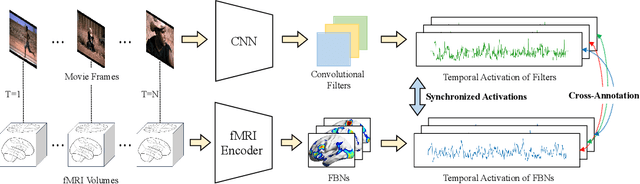



Artificial neural networks (ANNs), originally inspired by biological neural networks (BNNs), have achieved remarkable successes in many tasks such as visual representation learning. However, whether there exists semantic correlations/connections between the visual representations in ANNs and those in BNNs remains largely unexplored due to both the lack of an effective tool to link and couple two different domains, and the lack of a general and effective framework of representing the visual semantics in BNNs such as human functional brain networks (FBNs). To answer this question, we propose a novel computational framework, Synchronized Activations (Sync-ACT), to couple the visual representation spaces and semantics between ANNs and BNNs in human brain based on naturalistic functional magnetic resonance imaging (nfMRI) data. With this approach, we are able to semantically annotate the neurons in ANNs with biologically meaningful description derived from human brain imaging for the first time. We evaluated the Sync-ACT framework on two publicly available movie-watching nfMRI datasets. The experiments demonstrate a) the significant correlation and similarity of the semantics between the visual representations in FBNs and those in a variety of convolutional neural networks (CNNs) models; b) the close relationship between CNN's visual representation similarity to BNNs and its performance in image classification tasks. Overall, our study introduces a general and effective paradigm to couple the ANNs and BNNs and provides novel insights for future studies such as brain-inspired artificial intelligence.
Eye-gaze-guided Vision Transformer for Rectifying Shortcut Learning
May 25, 2022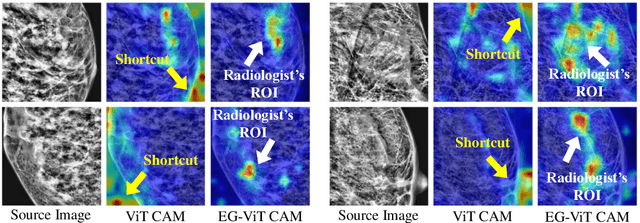
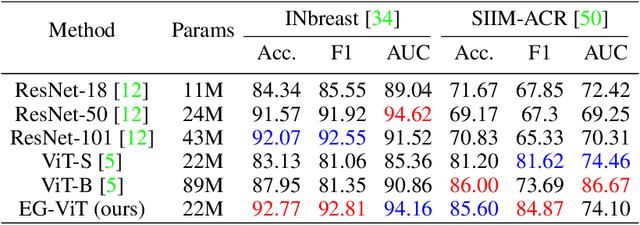
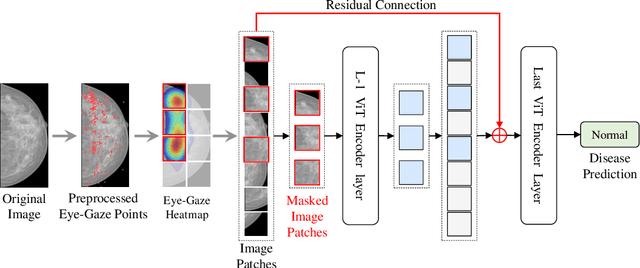
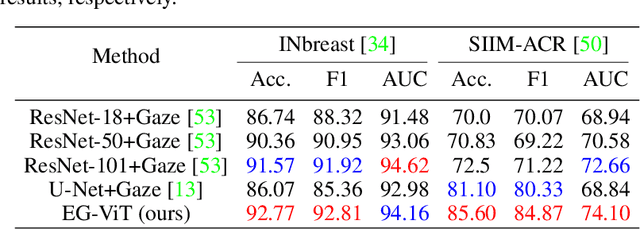
Learning harmful shortcuts such as spurious correlations and biases prevents deep neural networks from learning the meaningful and useful representations, thus jeopardizing the generalizability and interpretability of the learned representation. The situation becomes even more serious in medical imaging, where the clinical data (e.g., MR images with pathology) are limited and scarce while the reliability, generalizability and transparency of the learned model are highly required. To address this problem, we propose to infuse human experts' intelligence and domain knowledge into the training of deep neural networks. The core idea is that we infuse the visual attention information from expert radiologists to proactively guide the deep model to focus on regions with potential pathology and avoid being trapped in learning harmful shortcuts. To do so, we propose a novel eye-gaze-guided vision transformer (EG-ViT) for diagnosis with limited medical image data. We mask the input image patches that are out of the radiologists' interest and add an additional residual connection in the last encoder layer of EG-ViT to maintain the correlations of all patches. The experiments on two public datasets of INbreast and SIIM-ACR demonstrate our EG-ViT model can effectively learn/transfer experts' domain knowledge and achieve much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the EG-ViT model's interpretability. In general, EG-ViT takes the advantages of both human expert's prior knowledge and the power of deep neural networks. This work opens new avenues for advancing current artificial intelligence paradigms by infusing human intelligence.
Mask-guided Vision Transformer for Few-Shot Learning
May 20, 2022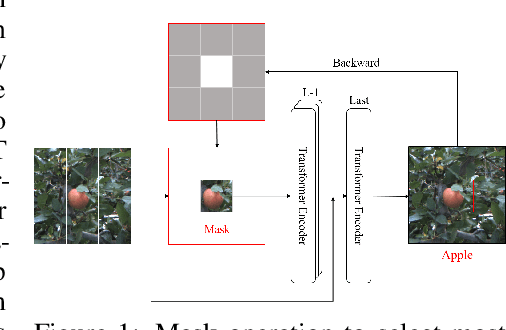
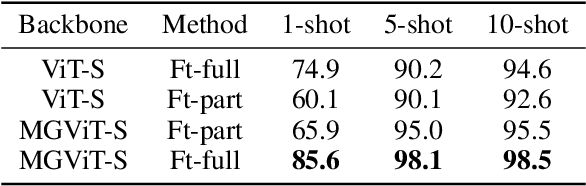
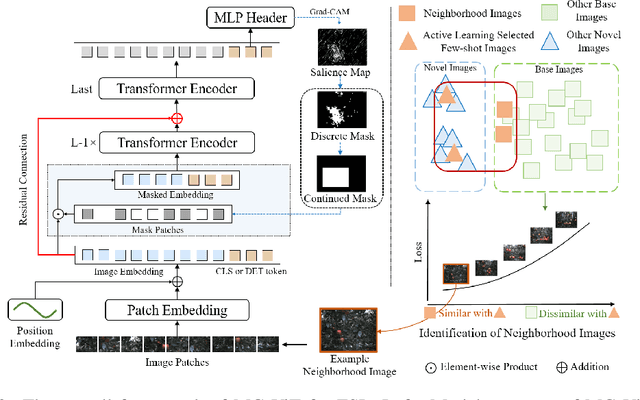
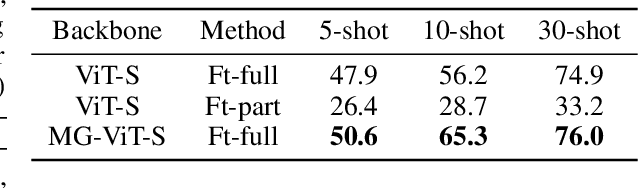
Learning with little data is challenging but often inevitable in various application scenarios where the labeled data is limited and costly. Recently, few-shot learning (FSL) gained increasing attention because of its generalizability of prior knowledge to new tasks that contain only a few samples. However, for data-intensive models such as vision transformer (ViT), current fine-tuning based FSL approaches are inefficient in knowledge generalization and thus degenerate the downstream task performances. In this paper, we propose a novel mask-guided vision transformer (MG-ViT) to achieve an effective and efficient FSL on ViT model. The key idea is to apply a mask on image patches to screen out the task-irrelevant ones and to guide the ViT to focus on task-relevant and discriminative patches during FSL. Particularly, MG-ViT only introduces an additional mask operation and a residual connection, enabling the inheritance of parameters from pre-trained ViT without any other cost. To optimally select representative few-shot samples, we also include an active learning based sample selection method to further improve the generalizability of MG-ViT based FSL. We evaluate the proposed MG-ViT on both Agri-ImageNet classification task and ACFR apple detection task with gradient-weighted class activation mapping (Grad-CAM) as the mask. The experimental results show that the MG-ViT model significantly improves the performance when compared with general fine-tuning based ViT models, providing novel insights and a concrete approach towards generalizing data-intensive and large-scale deep learning models for FSL.