 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Visual Semantics of Artificial Neural Networks and Human Brain Function via Synchronized Activations
Jun 22, 2022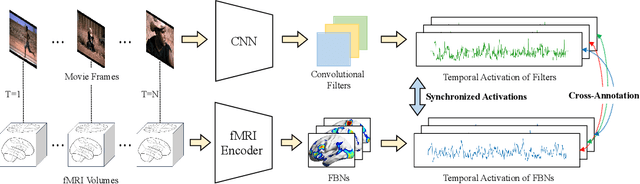



Artificial neural networks (ANNs), originally inspired by biological neural networks (BNNs), have achieved remarkable successes in many tasks such as visual representation learning. However, whether there exists semantic correlations/connections between the visual representations in ANNs and those in BNNs remains largely unexplored due to both the lack of an effective tool to link and couple two different domains, and the lack of a general and effective framework of representing the visual semantics in BNNs such as human functional brain networks (FBNs). To answer this question, we propose a novel computational framework, Synchronized Activations (Sync-ACT), to couple the visual representation spaces and semantics between ANNs and BNNs in human brain based on naturalistic functional magnetic resonance imaging (nfMRI) data. With this approach, we are able to semantically annotate the neurons in ANNs with biologically meaningful description derived from human brain imaging for the first time. We evaluated the Sync-ACT framework on two publicly available movie-watching nfMRI datasets. The experiments demonstrate a) the significant correlation and similarity of the semantics between the visual representations in FBNs and those in a variety of convolutional neural networks (CNNs) models; b) the close relationship between CNN's visual representation similarity to BNNs and its performance in image classification tasks. Overall, our study introduces a general and effective paradigm to couple the ANNs and BNNs and provides novel insights for future studies such as brain-inspired artificial intelligence.
Rectify ViT Shortcut Learning by Visual Saliency
Jun 17, 2022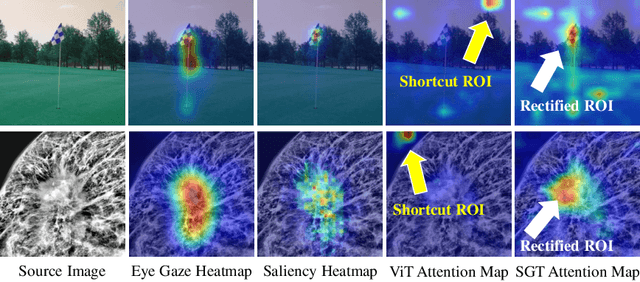

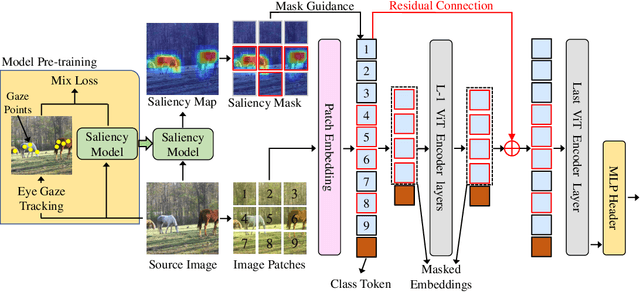

Shortcut learning is common but harmful to deep learning models, leading to degenerated feature representations and consequently jeopardizing the model's generalizability and interpretability. However, shortcut learning in the widely used Vision Transformer framework is largely unknown. Meanwhile, introducing domain-specific knowledge is a major approach to rectifying the shortcuts, which are predominated by background related factors. For example, in the medical imaging field, eye-gaze data from radiologists is an effective human visual prior knowledge that has the great potential to guide the deep learning models to focus on meaningful foreground regions of interest. However, obtaining eye-gaze data is time-consuming, labor-intensive and sometimes even not practical. In this work, we propose a novel and effective saliency-guided vision transformer (SGT) model to rectify shortcut learning in ViT with the absence of eye-gaze data. Specifically, a computational visual saliency model is adopted to predict saliency maps for input image samples. Then, the saliency maps are used to distil the most informative image patches. In the proposed SGT, the self-attention among image patches focus only on the distilled informative ones. Considering this distill operation may lead to global information lost, we further introduce, in the last encoder layer, a residual connection that captures the self-attention across all the image patches. The experiment results on four independent public datasets show that our SGT framework can effectively learn and leverage human prior knowledge without eye gaze data and achieves much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the interpretability of the ViT model, demonstrating the promise of transferring human prior knowledge derived visual saliency in rectifying shortcut learning
Mask-guided Vision Transformer for Few-Shot Learning
May 20, 2022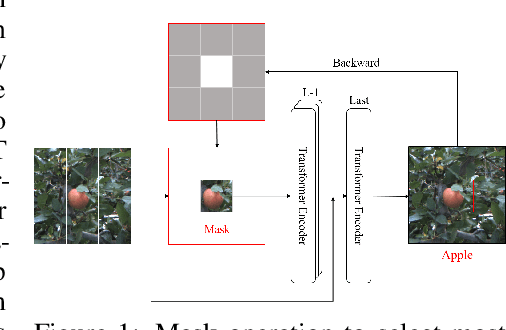
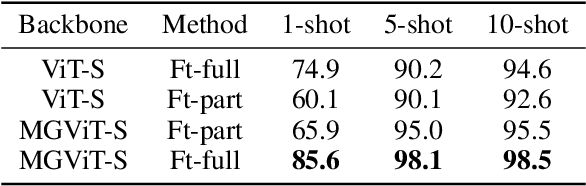
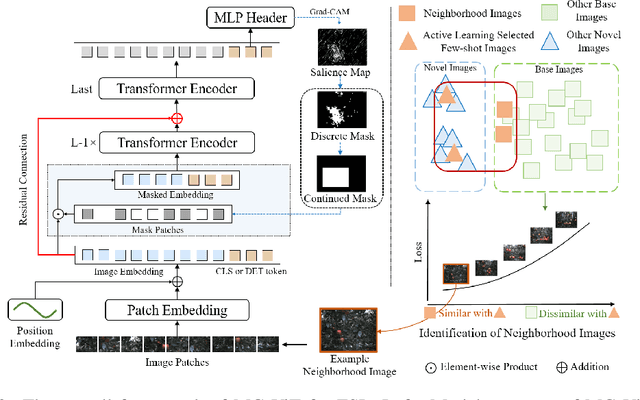
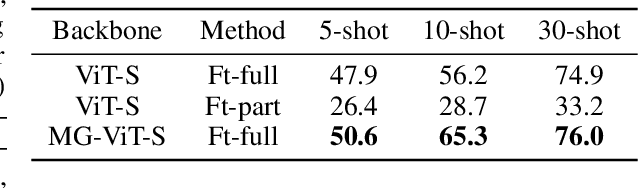
Learning with little data is challenging but often inevitable in various application scenarios where the labeled data is limited and costly. Recently, few-shot learning (FSL) gained increasing attention because of its generalizability of prior knowledge to new tasks that contain only a few samples. However, for data-intensive models such as vision transformer (ViT), current fine-tuning based FSL approaches are inefficient in knowledge generalization and thus degenerate the downstream task performances. In this paper, we propose a novel mask-guided vision transformer (MG-ViT) to achieve an effective and efficient FSL on ViT model. The key idea is to apply a mask on image patches to screen out the task-irrelevant ones and to guide the ViT to focus on task-relevant and discriminative patches during FSL. Particularly, MG-ViT only introduces an additional mask operation and a residual connection, enabling the inheritance of parameters from pre-trained ViT without any other cost. To optimally select representative few-shot samples, we also include an active learning based sample selection method to further improve the generalizability of MG-ViT based FSL. We evaluate the proposed MG-ViT on both Agri-ImageNet classification task and ACFR apple detection task with gradient-weighted class activation mapping (Grad-CAM) as the mask. The experimental results show that the MG-ViT model significantly improves the performance when compared with general fine-tuning based ViT models, providing novel insights and a concrete approach towards generalizing data-intensive and large-scale deep learning models for FSL.