 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAAC: A gate into Trustable Audio Affective Computing
Mar 26, 2026With the emergence of AI techniques for depression diagnosis, the conflict between high demand and limited supply for depression screening has been significantly alleviated. Among various modal data, audio-based depression diagnosis has received increasing attention from both academia and industry since audio is the most common carrier of emotion transmission. Unfortunately, audio data also contains User-sensitive Identity Information (ID), which is extremely vulnerable and may be maliciously used during the smart diagnosis process. Among previous methods, the clarification between depression features and sensitive features has always serve as a barrier. It is also critical to the problem for introducing a safe encryption methodology that only encrypts the sensitive features and a powerful classifier that can correctly diagnose the depression. To track these challenges, by leveraging adversarial loss-based Subspace Decomposition, we propose a first practical framework \name presented for Trustable Audio Affective Computing, to perform automated depression detection through audio within a trustable environment. The key enablers of TAAC are Differentiating Features Subspace Decompositor (DFSD), Flexible Noise Encryptor (FNE) and Staged Training Paradigm, used for decomposition, ID encryption and performance enhancement, respectively. Extensive experiments with existing encryption methods demonstrate our framework's preeminent performance in depression detection, ID reservation and audio reconstruction. Meanwhile, the experiments across various setting demonstrates our model's stability under different encryption strengths. Thus proving our framework's excellence in Confidentiality, Accuracy, Traceability, and Adjustability.
FNF: Functional Network Fingerprint for Large Language Models
Jan 30, 2026The development of large language models (LLMs) is costly and has significant commercial value. Consequently, preventing unauthorized appropriation of open-source LLMs and protecting developers' intellectual property rights have become critical challenges. In this work, we propose the Functional Network Fingerprint (FNF), a training-free, sample-efficient method for detecting whether a suspect LLM is derived from a victim model, based on the consistency between their functional network activity. We demonstrate that models that share a common origin, even with differences in scale or architecture, exhibit highly consistent patterns of neuronal activity within their functional networks across diverse input samples. In contrast, models trained independently on distinct data or with different objectives fail to preserve such activity alignment. Unlike conventional approaches, our method requires only a few samples for verification, preserves model utility, and remains robust to common model modifications (such as fine-tuning, pruning, and parameter permutation), as well as to comparisons across diverse architectures and dimensionalities. FNF thus provides model owners and third parties with a simple, non-invasive, and effective tool for protecting LLM intellectual property. The code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
Pruning Large Language Models by Identifying and Preserving Functional Networks
Aug 07, 2025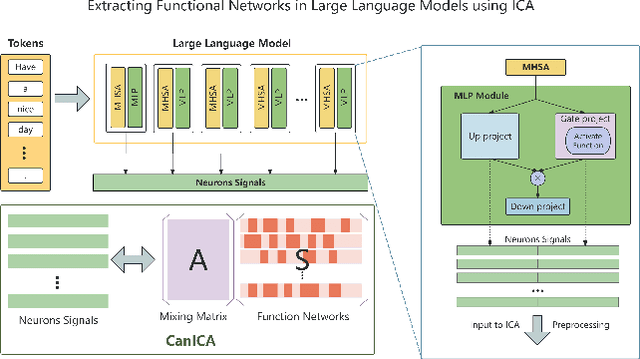
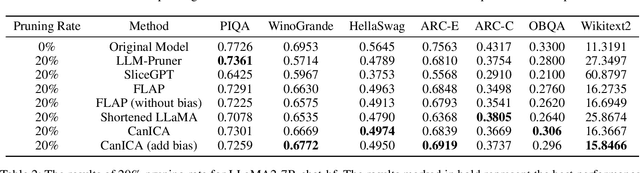
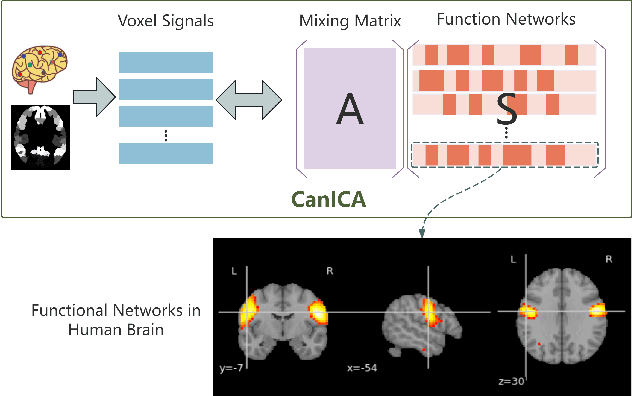

Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
LinBridge: A Learnable Framework for Interpreting Nonlinear Neural Encoding Models
Oct 26, 2024



Neural encoding of artificial neural networks (ANNs) links their computational representations to brain responses, offering insights into how the brain processes information. Current studies mostly use linear encoding models for clarity, even though brain responses are often nonlinear. This has sparked interest in developing nonlinear encoding models that are still interpretable. To address this problem, we propose LinBridge, a learnable and flexible framework based on Jacobian analysis for interpreting nonlinear encoding models. LinBridge posits that the nonlinear mapping between ANN representations and neural responses can be factorized into a linear inherent component that approximates the complex nonlinear relationship, and a mapping bias that captures sample-selective nonlinearity. The Jacobian matrix, which reflects output change rates relative to input, enables the analysis of sample-selective mapping in nonlinear models. LinBridge employs a self-supervised learning strategy to extract both the linear inherent component and nonlinear mapping biases from the Jacobian matrices of the test set, allowing it to adapt effectively to various nonlinear encoding models. We validate the LinBridge framework in the scenario of neural visual encoding, using computational visual representations from CLIP-ViT to predict brain activity recorded via functional magnetic resonance imaging (fMRI). Our experimental results demonstrate that: 1) the linear inherent component extracted by LinBridge accurately reflects the complex mappings of nonlinear neural encoding models; 2) the sample-selective mapping bias elucidates the variability of nonlinearity across different levels of the visual processing hierarchy. This study presents a novel tool for interpreting nonlinear neural encoding models and offers fresh evidence about hierarchical nonlinearity distribution in the visual cortex.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024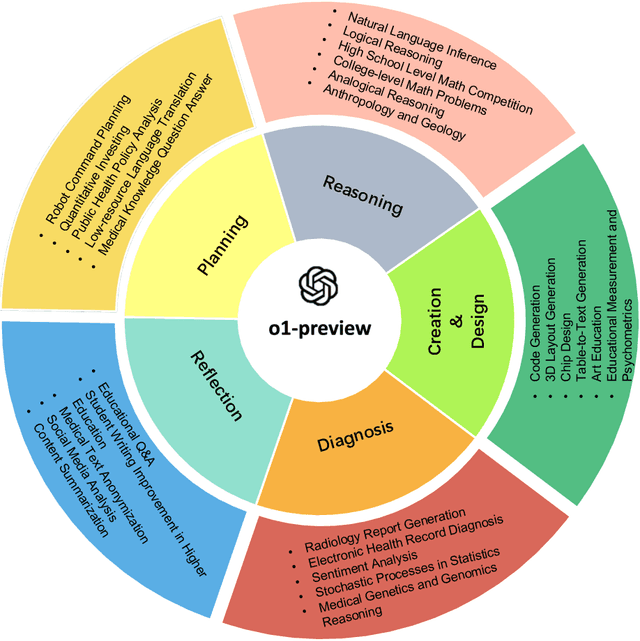

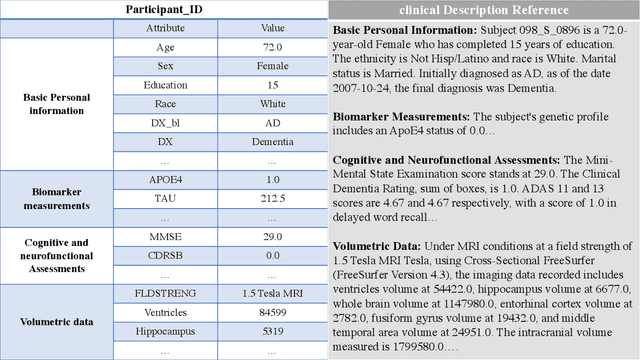

This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.
Surgical Triplet Recognition via Diffusion Model
Jun 19, 2024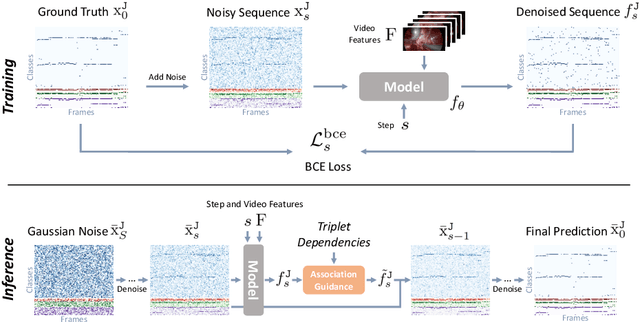
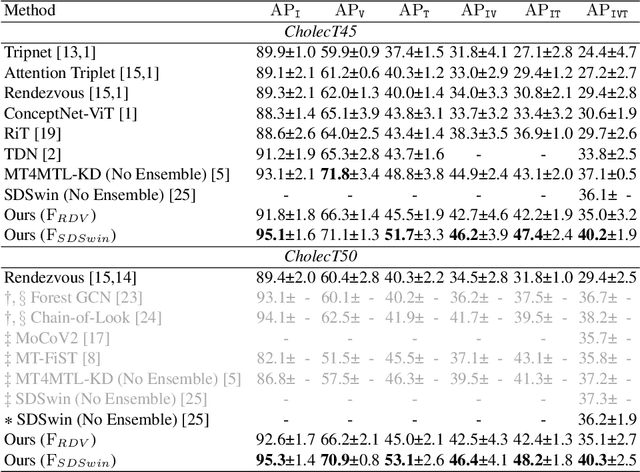
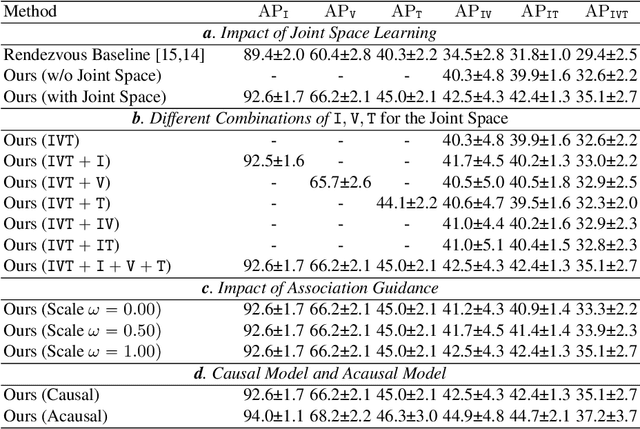

Surgical triplet recognition is an essential building block to enable next-generation context-aware operating rooms. The goal is to identify the combinations of instruments, verbs, and targets presented in surgical video frames. In this paper, we propose DiffTriplet, a new generative framework for surgical triplet recognition employing the diffusion model, which predicts surgical triplets via iterative denoising. To handle the challenge of triplet association, two unique designs are proposed in our diffusion framework, i.e., association learning and association guidance. During training, we optimize the model in the joint space of triplets and individual components to capture the dependencies among them. At inference, we integrate association constraints into each update of the iterative denoising process, which refines the triplet prediction using the information of individual components. Experiments on the CholecT45 and CholecT50 datasets show the superiority of the proposed method in achieving a new state-of-the-art performance for surgical triplet recognition. Our codes will be released.
Understanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024
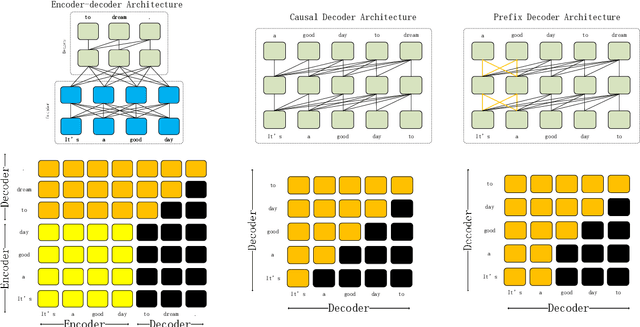
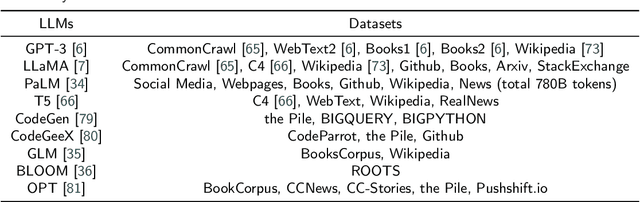
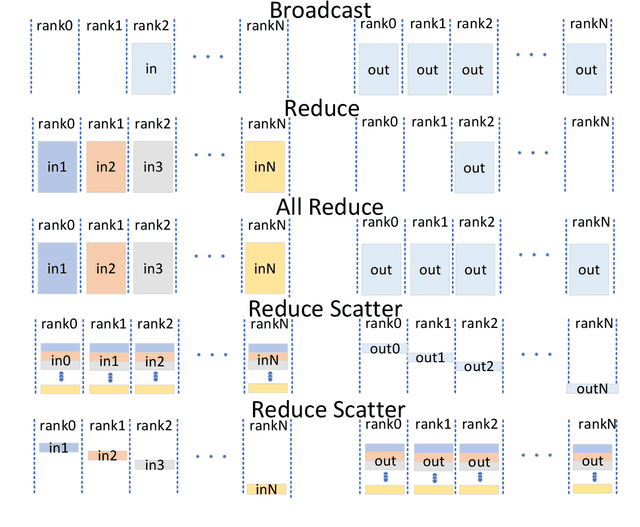
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023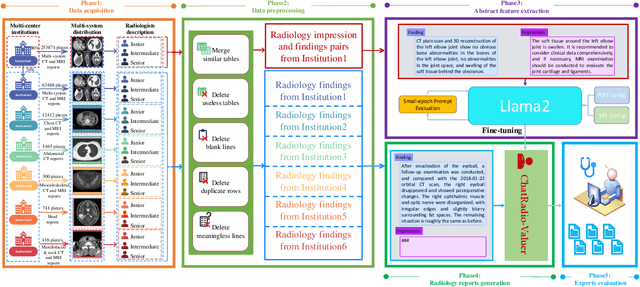
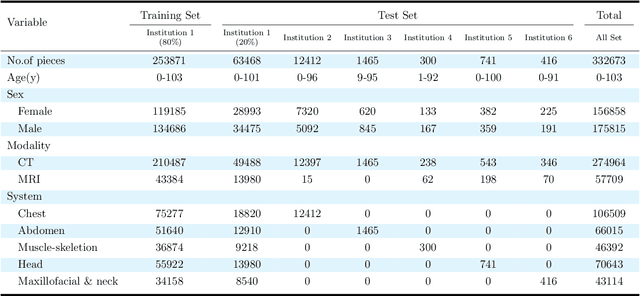
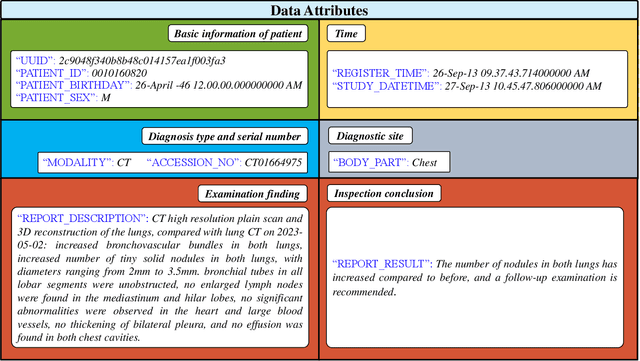
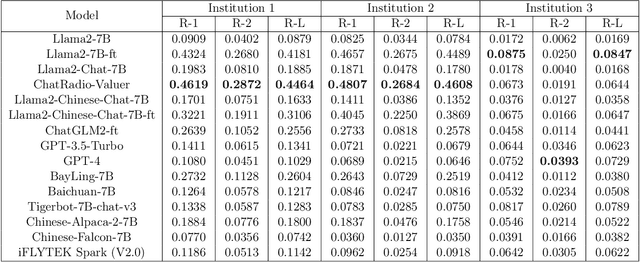
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
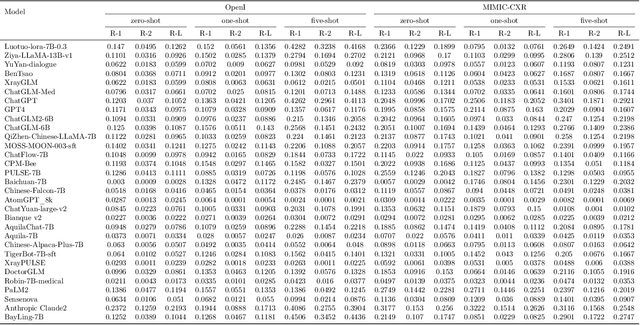
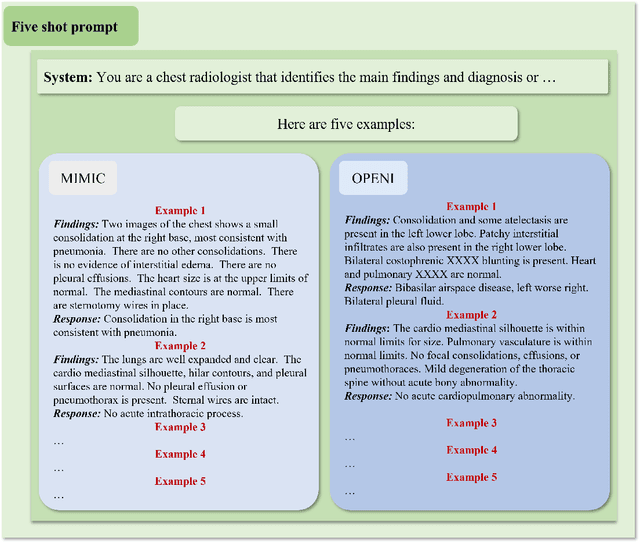
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.