 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024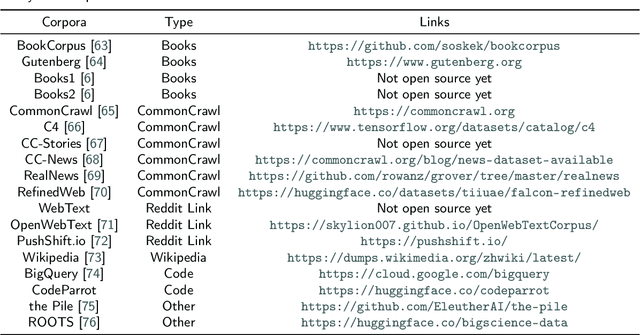
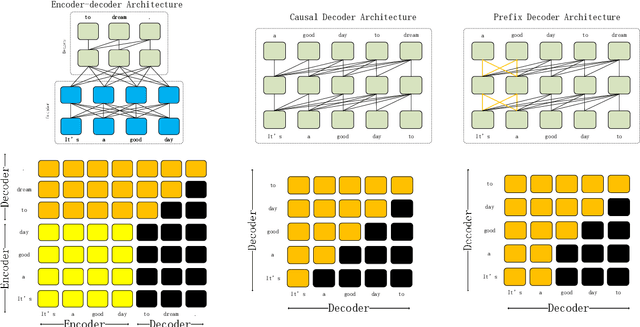
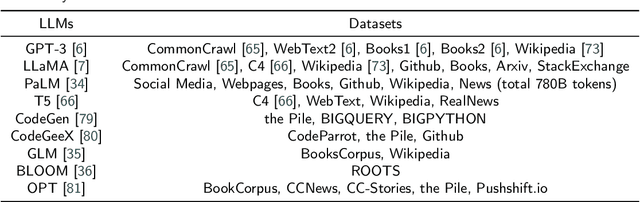
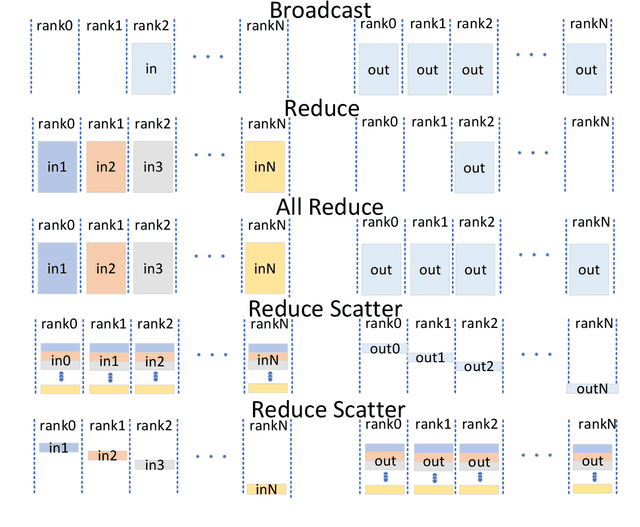
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
Summary of ChatGPT/GPT-4 Research and Perspective Towards the Future of Large Language Models
Apr 08, 2023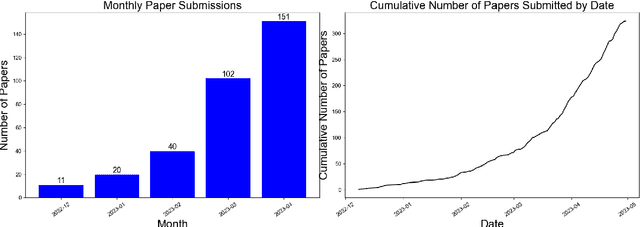


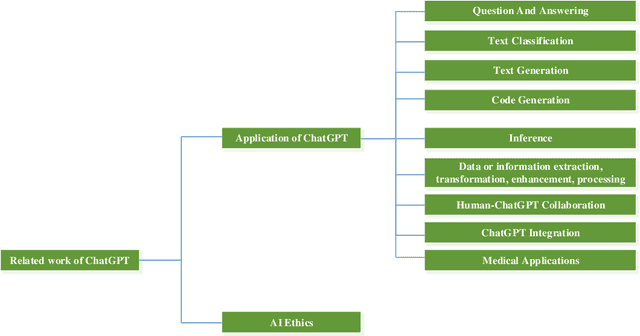
This paper presents a comprehensive survey of ChatGPT and GPT-4, state-of-the-art large language models (LLM) from the GPT series, and their prospective applications across diverse domains. Indeed, key innovations such as large-scale pre-training that captures knowledge across the entire world wide web, instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) have played significant roles in enhancing LLMs' adaptability and performance. We performed an in-depth analysis of 194 relevant papers on arXiv, encompassing trend analysis, word cloud representation, and distribution analysis across various application domains. The findings reveal a significant and increasing interest in ChatGPT/GPT-4 research, predominantly centered on direct natural language processing applications, while also demonstrating considerable potential in areas ranging from education and history to mathematics, medicine, and physics. This study endeavors to furnish insights into ChatGPT's capabilities, potential implications, ethical concerns, and offer direction for future advancements in this field.