 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNF: Functional Network Fingerprint for Large Language Models
Jan 30, 2026The development of large language models (LLMs) is costly and has significant commercial value. Consequently, preventing unauthorized appropriation of open-source LLMs and protecting developers' intellectual property rights have become critical challenges. In this work, we propose the Functional Network Fingerprint (FNF), a training-free, sample-efficient method for detecting whether a suspect LLM is derived from a victim model, based on the consistency between their functional network activity. We demonstrate that models that share a common origin, even with differences in scale or architecture, exhibit highly consistent patterns of neuronal activity within their functional networks across diverse input samples. In contrast, models trained independently on distinct data or with different objectives fail to preserve such activity alignment. Unlike conventional approaches, our method requires only a few samples for verification, preserves model utility, and remains robust to common model modifications (such as fine-tuning, pruning, and parameter permutation), as well as to comparisons across diverse architectures and dimensionalities. FNF thus provides model owners and third parties with a simple, non-invasive, and effective tool for protecting LLM intellectual property. The code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
Jan 05, 2026Visual generation is dominated by three paradigms: AutoRegressive (AR), diffusion, and Visual AutoRegressive (VAR) models. Unlike AR and diffusion, VARs operate on heterogeneous input structures across their generation steps, which creates severe asynchronous policy conflicts. This issue becomes particularly acute in reinforcement learning (RL) scenarios, leading to unstable training and suboptimal alignment. To resolve this, we propose a novel framework to enhance Group Relative Policy Optimization (GRPO) by explicitly managing these conflicts. Our method integrates three synergistic components: 1) a stabilizing intermediate reward to guide early-stage generation; 2) a dynamic time-step reweighting scheme for precise credit assignment; and 3) a novel mask propagation algorithm, derived from principles of Reward Feedback Learning (ReFL), designed to isolate optimization effects both spatially and temporally. Our approach demonstrates significant improvements in sample quality and objective alignment over the vanilla GRPO baseline, enabling robust and effective optimization for VAR models.
Pruning Large Language Models by Identifying and Preserving Functional Networks
Aug 07, 2025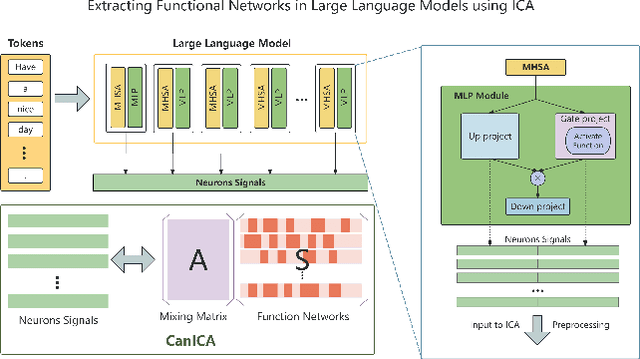
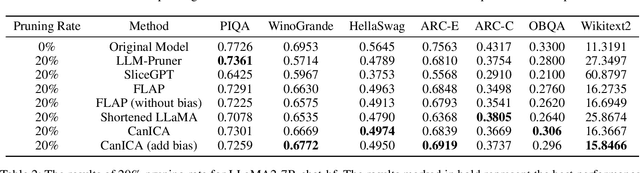
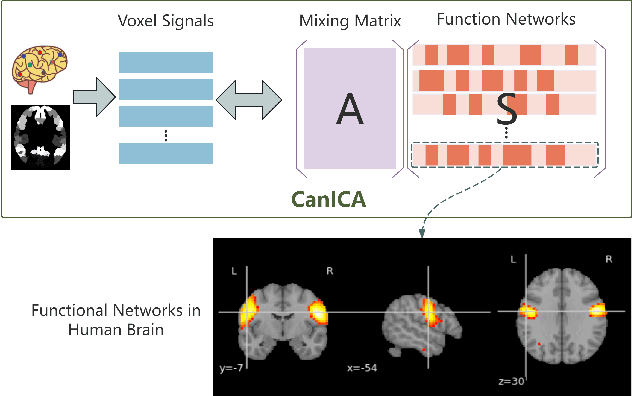

Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
DetailFlow: 1D Coarse-to-Fine Autoregressive Image Generation via Next-Detail Prediction
May 27, 2025This paper presents DetailFlow, a coarse-to-fine 1D autoregressive (AR) image generation method that models images through a novel next-detail prediction strategy. By learning a resolution-aware token sequence supervised with progressively degraded images, DetailFlow enables the generation process to start from the global structure and incrementally refine details. This coarse-to-fine 1D token sequence aligns well with the autoregressive inference mechanism, providing a more natural and efficient way for the AR model to generate complex visual content. Our compact 1D AR model achieves high-quality image synthesis with significantly fewer tokens than previous approaches, i.e. VAR/VQGAN. We further propose a parallel inference mechanism with self-correction that accelerates generation speed by approximately 8x while reducing accumulation sampling error inherent in teacher-forcing supervision. On the ImageNet 256x256 benchmark, our method achieves 2.96 gFID with 128 tokens, outperforming VAR (3.3 FID) and FlexVAR (3.05 FID), which both require 680 tokens in their AR models. Moreover, due to the significantly reduced token count and parallel inference mechanism, our method runs nearly 2x faster inference speed compared to VAR and FlexVAR. Extensive experimental results demonstrate DetailFlow's superior generation quality and efficiency compared to existing state-of-the-art methods.
Opportunities and Challenges of Large Language Models for Low-Resource Languages in Humanities Research
Dec 09, 2024Low-resource languages serve as invaluable repositories of human history, embodying cultural evolution and intellectual diversity. Despite their significance, these languages face critical challenges, including data scarcity and technological limitations, which hinder their comprehensive study and preservation. Recent advancements in large language models (LLMs) offer transformative opportunities for addressing these challenges, enabling innovative methodologies in linguistic, historical, and cultural research. This study systematically evaluates the applications of LLMs in low-resource language research, encompassing linguistic variation, historical documentation, cultural expressions, and literary analysis. By analyzing technical frameworks, current methodologies, and ethical considerations, this paper identifies key challenges such as data accessibility, model adaptability, and cultural sensitivity. Given the cultural, historical, and linguistic richness inherent in low-resource languages, this work emphasizes interdisciplinary collaboration and the development of customized models as promising avenues for advancing research in this domain. By underscoring the potential of integrating artificial intelligence with the humanities to preserve and study humanity's linguistic and cultural heritage, this study fosters global efforts towards safeguarding intellectual diversity.
TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
Dec 04, 2024



We present TokenFlow, a novel unified image tokenizer that bridges the long-standing gap between multimodal understanding and generation. Prior research attempt to employ a single reconstruction-targeted Vector Quantization (VQ) encoder for unifying these two tasks. We observe that understanding and generation require fundamentally different granularities of visual information. This leads to a critical trade-off, particularly compromising performance in multimodal understanding tasks. TokenFlow addresses this challenge through an innovative dual-codebook architecture that decouples semantic and pixel-level feature learning while maintaining their alignment via a shared mapping mechanism. This design enables direct access to both high-level semantic representations crucial for understanding tasks and fine-grained visual features essential for generation through shared indices. Our extensive experiments demonstrate TokenFlow's superiority across multiple dimensions. Leveraging TokenFlow, we demonstrate for the first time that discrete visual input can surpass LLaVA-1.5 13B in understanding performance, achieving a 7.2\% average improvement. For image reconstruction, we achieve a strong FID score of 0.63 at 384*384 resolution. Moreover, TokenFlow establishes state-of-the-art performance in autoregressive image generation with a GenEval score of 0.55 at 256*256 resolution, achieving comparable results to SDXL.
LinBridge: A Learnable Framework for Interpreting Nonlinear Neural Encoding Models
Oct 26, 2024



Neural encoding of artificial neural networks (ANNs) links their computational representations to brain responses, offering insights into how the brain processes information. Current studies mostly use linear encoding models for clarity, even though brain responses are often nonlinear. This has sparked interest in developing nonlinear encoding models that are still interpretable. To address this problem, we propose LinBridge, a learnable and flexible framework based on Jacobian analysis for interpreting nonlinear encoding models. LinBridge posits that the nonlinear mapping between ANN representations and neural responses can be factorized into a linear inherent component that approximates the complex nonlinear relationship, and a mapping bias that captures sample-selective nonlinearity. The Jacobian matrix, which reflects output change rates relative to input, enables the analysis of sample-selective mapping in nonlinear models. LinBridge employs a self-supervised learning strategy to extract both the linear inherent component and nonlinear mapping biases from the Jacobian matrices of the test set, allowing it to adapt effectively to various nonlinear encoding models. We validate the LinBridge framework in the scenario of neural visual encoding, using computational visual representations from CLIP-ViT to predict brain activity recorded via functional magnetic resonance imaging (fMRI). Our experimental results demonstrate that: 1) the linear inherent component extracted by LinBridge accurately reflects the complex mappings of nonlinear neural encoding models; 2) the sample-selective mapping bias elucidates the variability of nonlinearity across different levels of the visual processing hierarchy. This study presents a novel tool for interpreting nonlinear neural encoding models and offers fresh evidence about hierarchical nonlinearity distribution in the visual cortex.
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.
Investigation of the effectiveness of applying ChatGPT in Dialogic Teaching Using Electroencephalography
Apr 08, 2024



In recent years, the rapid development of artificial intelligence technology, especially the emergence of large language models (LLMs) such as ChatGPT, has presented significant prospects for application in the field of education. LLMs possess the capability to interpret knowledge, answer questions, and consider context, thus providing support for dialogic teaching to students. Therefore, an examination of the capacity of LLMs to effectively fulfill instructional roles, thereby facilitating student learning akin to human educators within dialogic teaching scenarios, is an exceptionally valuable research topic. This research recruited 34 undergraduate students as participants, who were randomly divided into two groups. The experimental group engaged in dialogic teaching using ChatGPT, while the control group interacted with human teachers. Both groups learned the histogram equalization unit in the information-related course "Digital Image Processing". The research findings show comparable scores between the two groups on the retention test. However, students who engaged in dialogue with ChatGPT exhibited lower performance on the transfer test. Electroencephalography data revealed that students who interacted with ChatGPT exhibited higher levels of cognitive activity, suggesting that ChatGPT could help students establish a knowledge foundation and stimulate cognitive activity. However, its strengths on promoting students. knowledge application and creativity were insignificant. Based upon the research findings, it is evident that ChatGPT cannot fully excel in fulfilling teaching tasks in the dialogue teaching in information related courses. Combining ChatGPT with traditional human teachers might be a more ideal approach. The synergistic use of both can provide students with more comprehensive learning support, thus contributing to enhancing the quality of teaching.