 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024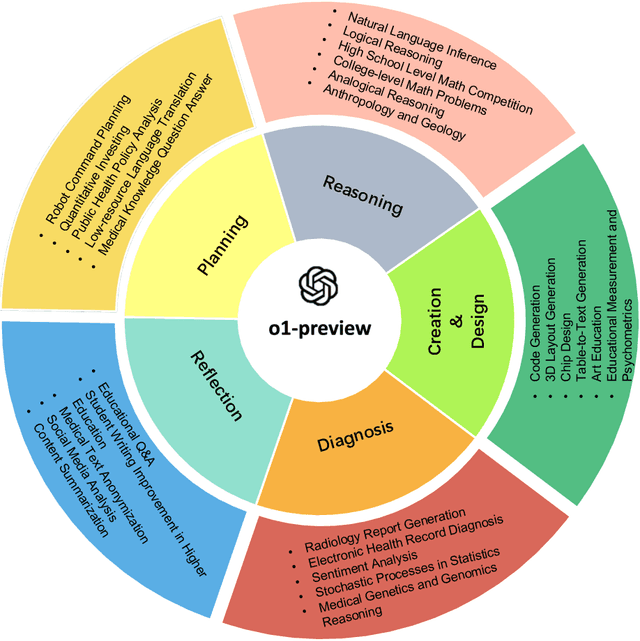


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
HARP: Human-Assisted Regrouping with Permutation Invariant Critic for Multi-Agent Reinforcement Learning
Sep 18, 2024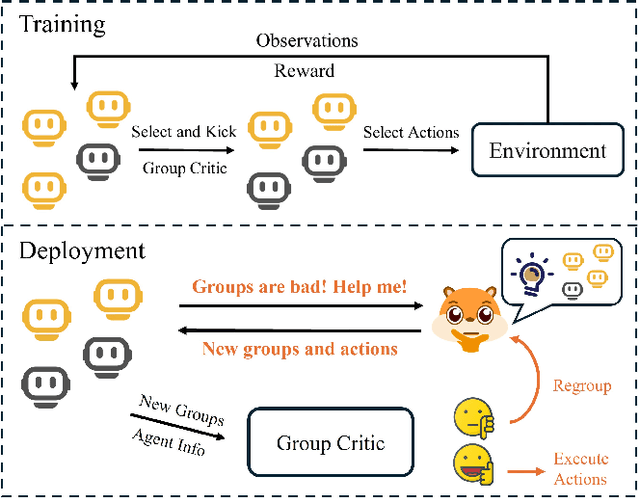
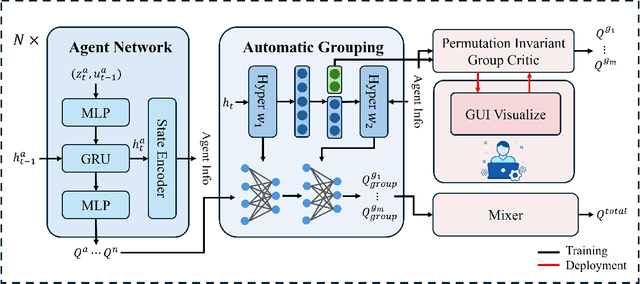
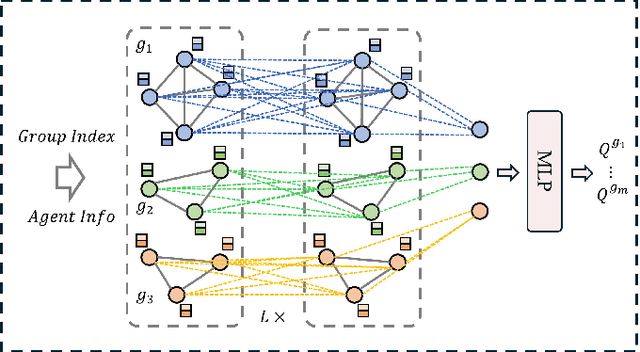

Human-in-the-loop reinforcement learning integrates human expertise to accelerate agent learning and provide critical guidance and feedback in complex fields. However, many existing approaches focus on single-agent tasks and require continuous human involvement during the training process, significantly increasing the human workload and limiting scalability. In this paper, we propose HARP (Human-Assisted Regrouping with Permutation Invariant Critic), a multi-agent reinforcement learning framework designed for group-oriented tasks. HARP integrates automatic agent regrouping with strategic human assistance during deployment, enabling and allowing non-experts to offer effective guidance with minimal intervention. During training, agents dynamically adjust their groupings to optimize collaborative task completion. When deployed, they actively seek human assistance and utilize the Permutation Invariant Group Critic to evaluate and refine human-proposed groupings, allowing non-expert users to contribute valuable suggestions. In multiple collaboration scenarios, our approach is able to leverage limited guidance from non-experts and enhance performance. The project can be found at https://github.com/huawen-hu/HARP.
Large Language Models for Robotics: Opportunities, Challenges, and Perspectives
Jan 09, 2024Large language models (LLMs) have undergone significant expansion and have been increasingly integrated across various domains. Notably, in the realm of robot task planning, LLMs harness their advanced reasoning and language comprehension capabilities to formulate precise and efficient action plans based on natural language instructions. However, for embodied tasks, where robots interact with complex environments, text-only LLMs often face challenges due to a lack of compatibility with robotic visual perception. This study provides a comprehensive overview of the emerging integration of LLMs and multimodal LLMs into various robotic tasks. Additionally, we propose a framework that utilizes multimodal GPT-4V to enhance embodied task planning through the combination of natural language instructions and robot visual perceptions. Our results, based on diverse datasets, indicate that GPT-4V effectively enhances robot performance in embodied tasks. This extensive survey and evaluation of LLMs and multimodal LLMs across a variety of robotic tasks enriches the understanding of LLM-centric embodied intelligence and provides forward-looking insights toward bridging the gap in Human-Robot-Environment interaction.
Prompt Engineering for Healthcare: Methodologies and Applications
Apr 28, 2023This review will introduce the latest advances in prompt engineering in the field of natural language processing (NLP) for the medical domain. First, we will provide a brief overview of the development of prompt engineering and emphasize its significant contributions to healthcare NLP applications such as question-answering systems, text summarization, and machine translation. With the continuous improvement of general large language models, the importance of prompt engineering in the healthcare domain is becoming increasingly prominent. The aim of this article is to provide useful resources and bridges for healthcare NLP researchers to better explore the application of prompt engineering in this field. We hope that this review can provide new ideas and inspire ample possibilities for research and application in medical NLP.