 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNF: Functional Network Fingerprint for Large Language Models
Jan 30, 2026The development of large language models (LLMs) is costly and has significant commercial value. Consequently, preventing unauthorized appropriation of open-source LLMs and protecting developers' intellectual property rights have become critical challenges. In this work, we propose the Functional Network Fingerprint (FNF), a training-free, sample-efficient method for detecting whether a suspect LLM is derived from a victim model, based on the consistency between their functional network activity. We demonstrate that models that share a common origin, even with differences in scale or architecture, exhibit highly consistent patterns of neuronal activity within their functional networks across diverse input samples. In contrast, models trained independently on distinct data or with different objectives fail to preserve such activity alignment. Unlike conventional approaches, our method requires only a few samples for verification, preserves model utility, and remains robust to common model modifications (such as fine-tuning, pruning, and parameter permutation), as well as to comparisons across diverse architectures and dimensionalities. FNF thus provides model owners and third parties with a simple, non-invasive, and effective tool for protecting LLM intellectual property. The code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
Pruning Large Language Models by Identifying and Preserving Functional Networks
Aug 07, 2025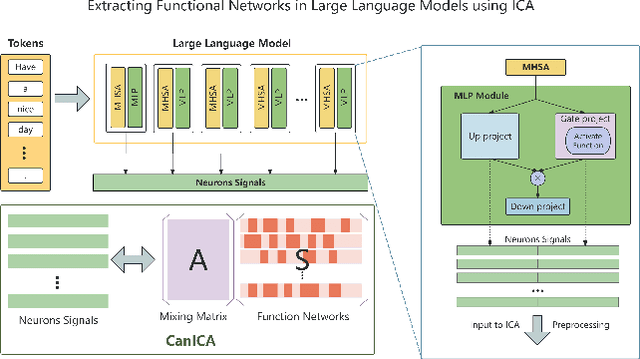
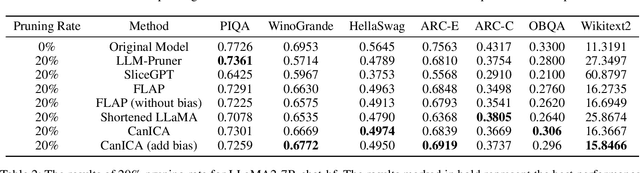
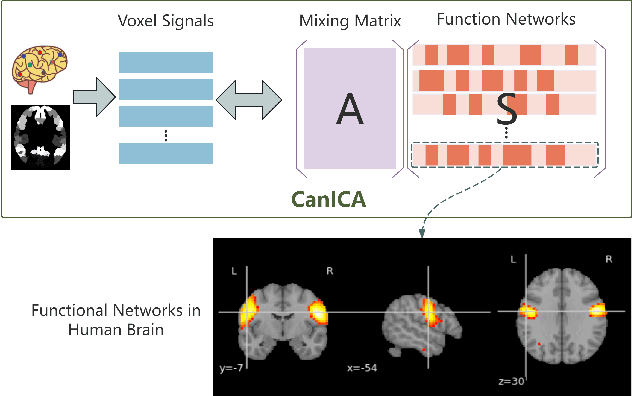

Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024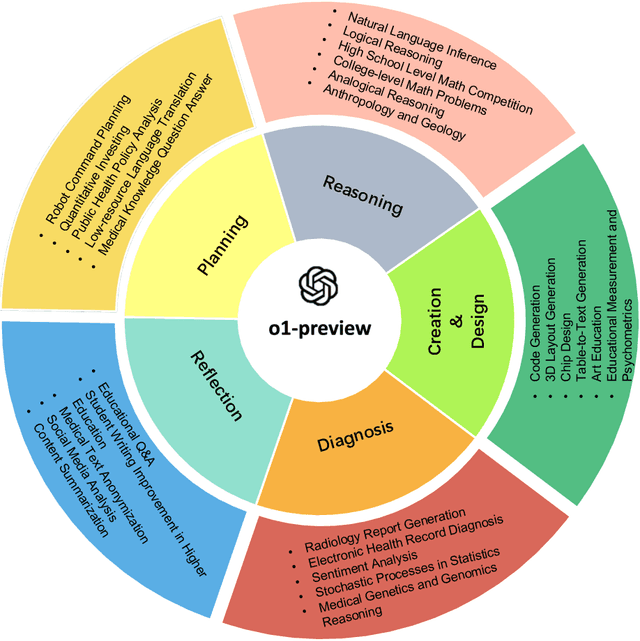


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.