 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNF: Functional Network Fingerprint for Large Language Models
Jan 30, 2026The development of large language models (LLMs) is costly and has significant commercial value. Consequently, preventing unauthorized appropriation of open-source LLMs and protecting developers' intellectual property rights have become critical challenges. In this work, we propose the Functional Network Fingerprint (FNF), a training-free, sample-efficient method for detecting whether a suspect LLM is derived from a victim model, based on the consistency between their functional network activity. We demonstrate that models that share a common origin, even with differences in scale or architecture, exhibit highly consistent patterns of neuronal activity within their functional networks across diverse input samples. In contrast, models trained independently on distinct data or with different objectives fail to preserve such activity alignment. Unlike conventional approaches, our method requires only a few samples for verification, preserves model utility, and remains robust to common model modifications (such as fine-tuning, pruning, and parameter permutation), as well as to comparisons across diverse architectures and dimensionalities. FNF thus provides model owners and third parties with a simple, non-invasive, and effective tool for protecting LLM intellectual property. The code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
Pruning Large Language Models by Identifying and Preserving Functional Networks
Aug 07, 2025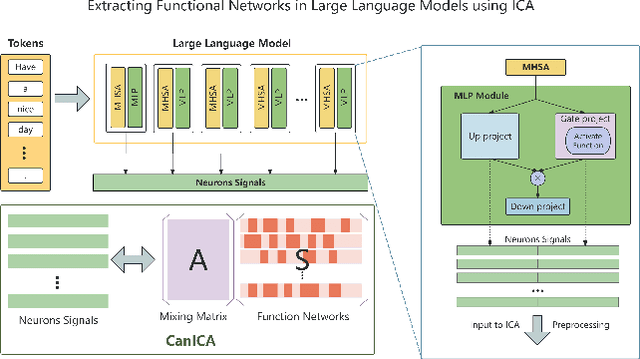
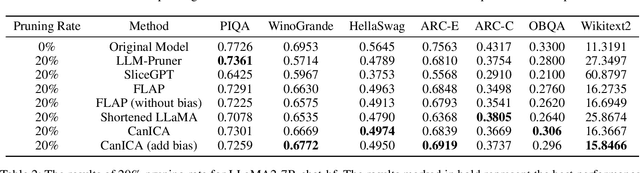

Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.
LCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
Efficient Trajectory Generation in 3D Environments with Multi-Level Map Construction
Nov 13, 2024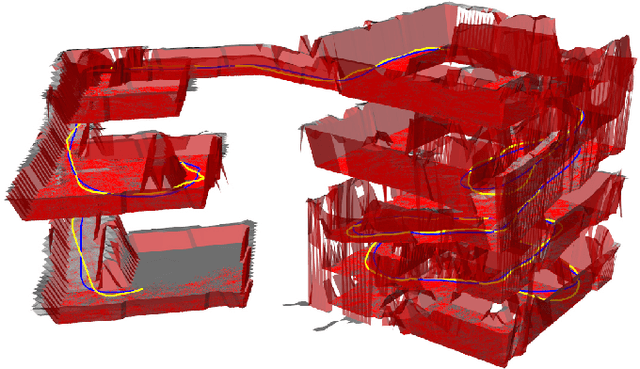

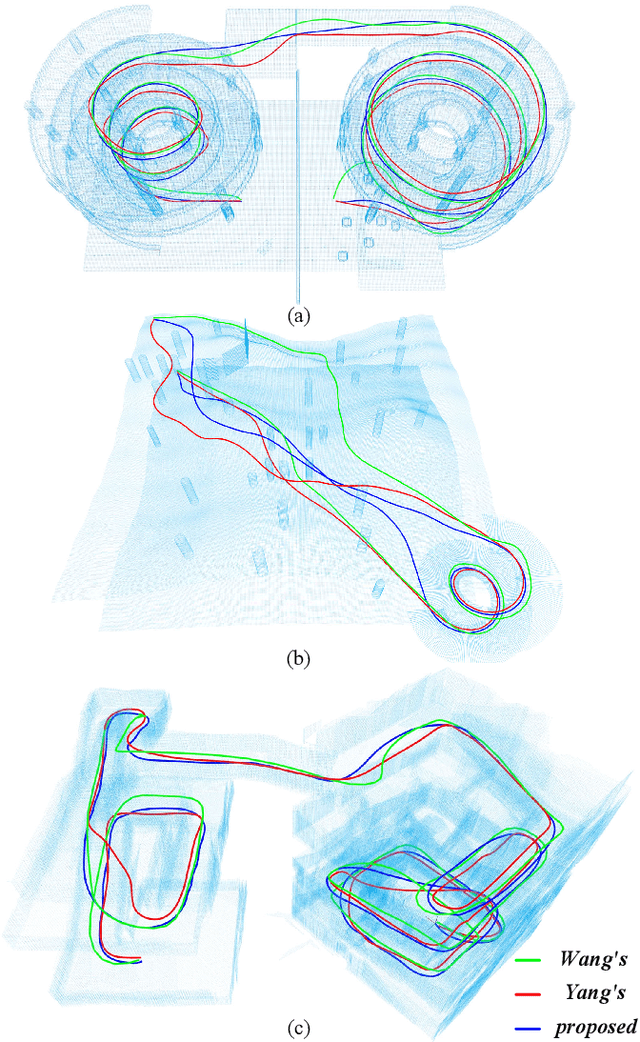
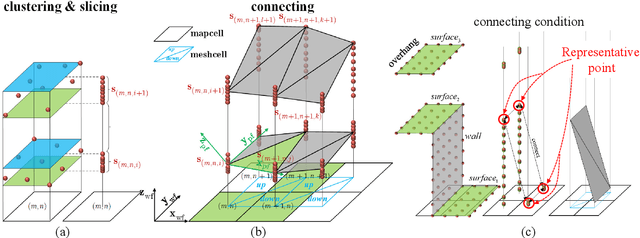
We propose a robust and efficient framework to generate global trajectories for ground robots in complex 3D environments. The proposed method takes point cloud as input and efficiently constructs a multi-level map using triangular patches as the basic elements. A kinematic path search is adopted on the patches, where motion primitives on different patches combine to form the global min-time cost initial trajectory. We use a same-level expansion method to locate the nearest obstacle for each trajectory waypoint and construct an objective function with curvature, smoothness and obstacle terms for optimization. We evaluate the method on several complex 3D point cloud maps. Compared to existing methods, our method demonstrates higher robustness to point cloud noise, enabling the generation of high quality trajectory while maintaining high computational efficiency. Our code will be publicly available at https://github.com/ck-tian/MLMC-planner.
LOCAL: Learning with Orientation Matrix to Infer Causal Structure from Time Series Data
Oct 28, 2024


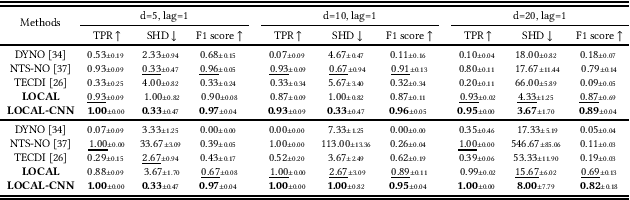
Discovering the underlying Directed Acyclic Graph (DAG) from time series observational data is highly challenging due to the dynamic nature and complex nonlinear interactions between variables. Existing methods often struggle with inefficiency and the handling of high-dimensional data. To address these research gap, we propose LOCAL, a highly efficient, easy-to-implement, and constraint-free method for recovering dynamic causal structures. LOCAL is the first attempt to formulate a quasi-maximum likelihood-based score function for learning the dynamic DAG equivalent to the ground truth. On this basis, we propose two adaptive modules for enhancing the algebraic characterization of acyclicity with new capabilities: Asymptotic Causal Mask Learning (ACML) and Dynamic Graph Parameter Learning (DGPL). ACML generates causal masks using learnable priority vectors and the Gumbel-Sigmoid function, ensuring the creation of DAGs while optimizing computational efficiency. DGPL transforms causal learning into decomposed matrix products, capturing the dynamic causal structure of high-dimensional data and enhancing interpretability. Extensive experiments on synthetic and real-world datasets demonstrate that LOCAL significantly outperforms existing methods, and highlight LOCAL's potential as a robust and efficient method for dynamic causal discovery. Our code will be available soon.
LinBridge: A Learnable Framework for Interpreting Nonlinear Neural Encoding Models
Oct 26, 2024



Neural encoding of artificial neural networks (ANNs) links their computational representations to brain responses, offering insights into how the brain processes information. Current studies mostly use linear encoding models for clarity, even though brain responses are often nonlinear. This has sparked interest in developing nonlinear encoding models that are still interpretable. To address this problem, we propose LinBridge, a learnable and flexible framework based on Jacobian analysis for interpreting nonlinear encoding models. LinBridge posits that the nonlinear mapping between ANN representations and neural responses can be factorized into a linear inherent component that approximates the complex nonlinear relationship, and a mapping bias that captures sample-selective nonlinearity. The Jacobian matrix, which reflects output change rates relative to input, enables the analysis of sample-selective mapping in nonlinear models. LinBridge employs a self-supervised learning strategy to extract both the linear inherent component and nonlinear mapping biases from the Jacobian matrices of the test set, allowing it to adapt effectively to various nonlinear encoding models. We validate the LinBridge framework in the scenario of neural visual encoding, using computational visual representations from CLIP-ViT to predict brain activity recorded via functional magnetic resonance imaging (fMRI). Our experimental results demonstrate that: 1) the linear inherent component extracted by LinBridge accurately reflects the complex mappings of nonlinear neural encoding models; 2) the sample-selective mapping bias elucidates the variability of nonlinearity across different levels of the visual processing hierarchy. This study presents a novel tool for interpreting nonlinear neural encoding models and offers fresh evidence about hierarchical nonlinearity distribution in the visual cortex.
Understanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024
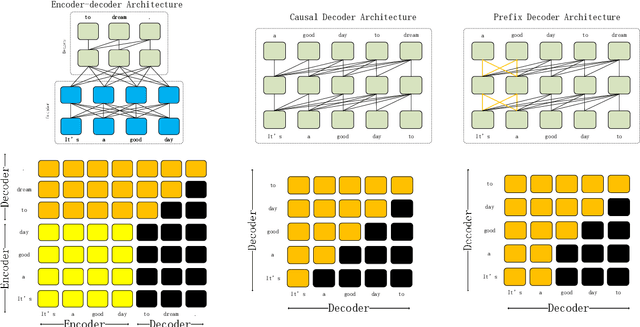
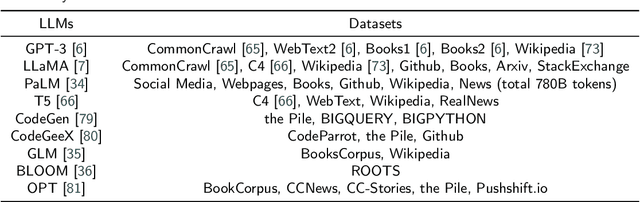
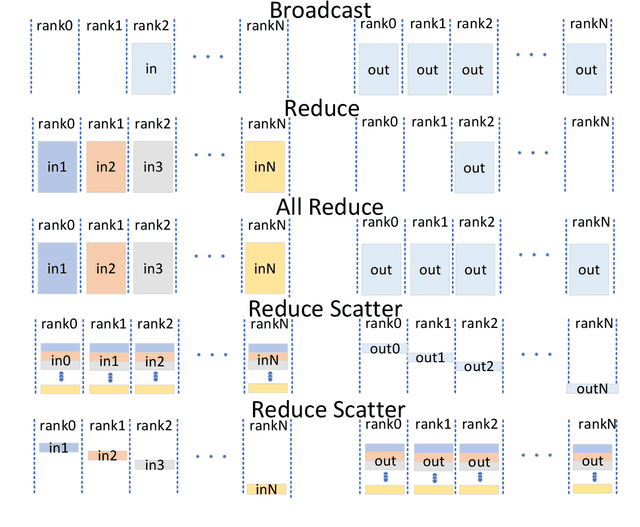
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.