 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
C4D: 4D Made from 3D through Dual Correspondences
Oct 16, 2025Recovering 4D from monocular video, which jointly estimates dynamic geometry and camera poses, is an inevitably challenging problem. While recent pointmap-based 3D reconstruction methods (e.g., DUSt3R) have made great progress in reconstructing static scenes, directly applying them to dynamic scenes leads to inaccurate results. This discrepancy arises because moving objects violate multi-view geometric constraints, disrupting the reconstruction. To address this, we introduce C4D, a framework that leverages temporal Correspondences to extend existing 3D reconstruction formulation to 4D. Specifically, apart from predicting pointmaps, C4D captures two types of correspondences: short-term optical flow and long-term point tracking. We train a dynamic-aware point tracker that provides additional mobility information, facilitating the estimation of motion masks to separate moving elements from the static background, thus offering more reliable guidance for dynamic scenes. Furthermore, we introduce a set of dynamic scene optimization objectives to recover per-frame 3D geometry and camera parameters. Simultaneously, the correspondences lift 2D trajectories into smooth 3D trajectories, enabling fully integrated 4D reconstruction. Experiments show that our framework achieves complete 4D recovery and demonstrates strong performance across multiple downstream tasks, including depth estimation, camera pose estimation, and point tracking. Project Page: https://littlepure2333.github.io/C4D
WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
Oct 08, 2025Wrist-view observations are crucial for VLA models as they capture fine-grained hand-object interactions that directly enhance manipulation performance. Yet large-scale datasets rarely include such recordings, resulting in a substantial gap between abundant anchor views and scarce wrist views. Existing world models cannot bridge this gap, as they require a wrist-view first frame and thus fail to generate wrist-view videos from anchor views alone. Amid this gap, recent visual geometry models such as VGGT emerge with geometric and cross-view priors that make it possible to address extreme viewpoint shifts. Inspired by these insights, we propose WristWorld, the first 4D world model that generates wrist-view videos solely from anchor views. WristWorld operates in two stages: (i) Reconstruction, which extends VGGT and incorporates our Spatial Projection Consistency (SPC) Loss to estimate geometrically consistent wrist-view poses and 4D point clouds; (ii) Generation, which employs our video generation model to synthesize temporally coherent wrist-view videos from the reconstructed perspective. Experiments on Droid, Calvin, and Franka Panda demonstrate state-of-the-art video generation with superior spatial consistency, while also improving VLA performance, raising the average task completion length on Calvin by 3.81% and closing 42.4% of the anchor-wrist view gap.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
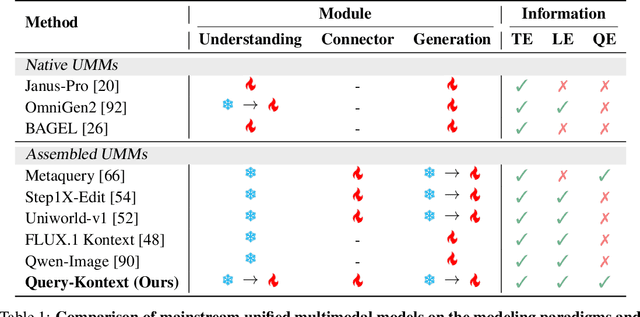
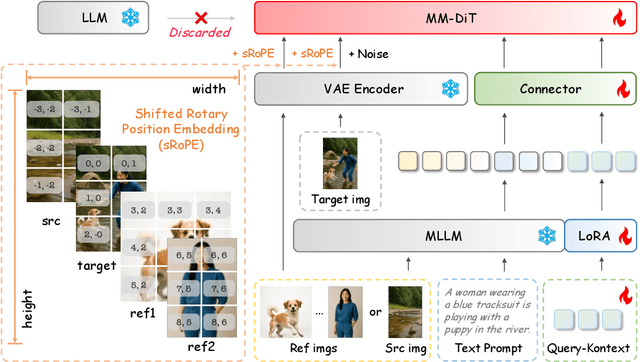
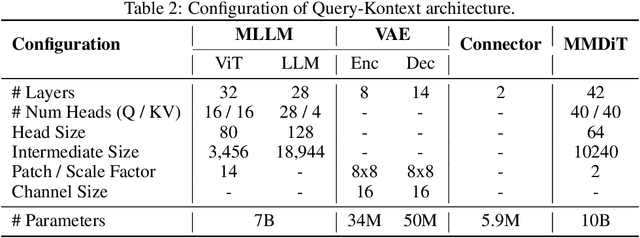
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Test3R: Learning to Reconstruct 3D at Test Time
Jun 16, 2025Dense matching methods like DUSt3R regress pairwise pointmaps for 3D reconstruction. However, the reliance on pairwise prediction and the limited generalization capability inherently restrict the global geometric consistency. In this work, we introduce Test3R, a surprisingly simple test-time learning technique that significantly boosts geometric accuracy. Using image triplets ($I_1,I_2,I_3$), Test3R generates reconstructions from pairs ($I_1,I_2$) and ($I_1,I_3$). The core idea is to optimize the network at test time via a self-supervised objective: maximizing the geometric consistency between these two reconstructions relative to the common image $I_1$. This ensures the model produces cross-pair consistent outputs, regardless of the inputs. Extensive experiments demonstrate that our technique significantly outperforms previous state-of-the-art methods on the 3D reconstruction and multi-view depth estimation tasks. Moreover, it is universally applicable and nearly cost-free, making it easily applied to other models and implemented with minimal test-time training overhead and parameter footprint. Code is available at https://github.com/nopQAQ/Test3R.
PE3R: Perception-Efficient 3D Reconstruction
Mar 10, 2025


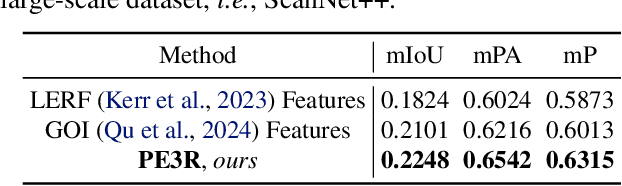
Recent advancements in 2D-to-3D perception have significantly improved the understanding of 3D scenes from 2D images. However, existing methods face critical challenges, including limited generalization across scenes, suboptimal perception accuracy, and slow reconstruction speeds. To address these limitations, we propose Perception-Efficient 3D Reconstruction (PE3R), a novel framework designed to enhance both accuracy and efficiency. PE3R employs a feed-forward architecture to enable rapid 3D semantic field reconstruction. The framework demonstrates robust zero-shot generalization across diverse scenes and objects while significantly improving reconstruction speed. Extensive experiments on 2D-to-3D open-vocabulary segmentation and 3D reconstruction validate the effectiveness and versatility of PE3R. The framework achieves a minimum 9-fold speedup in 3D semantic field reconstruction, along with substantial gains in perception accuracy and reconstruction precision, setting new benchmarks in the field. The code is publicly available at: https://github.com/hujiecpp/PE3R.
GFlow: Recovering 4D World from Monocular Video
May 28, 2024
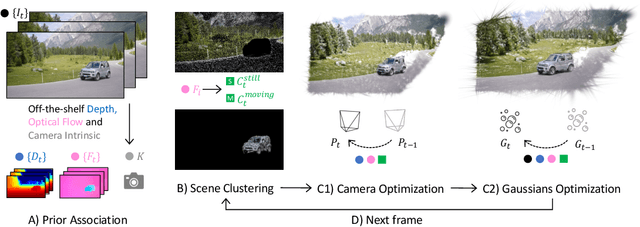


Reconstructing 4D scenes from video inputs is a crucial yet challenging task. Conventional methods usually rely on the assumptions of multi-view video inputs, known camera parameters, or static scenes, all of which are typically absent under in-the-wild scenarios. In this paper, we relax all these constraints and tackle a highly ambitious but practical task, which we termed as AnyV4D: we assume only one monocular video is available without any camera parameters as input, and we aim to recover the dynamic 4D world alongside the camera poses. To this end, we introduce GFlow, a new framework that utilizes only 2D priors (depth and optical flow) to lift a video (3D) to a 4D explicit representation, entailing a flow of Gaussian splatting through space and time. GFlow first clusters the scene into still and moving parts, then applies a sequential optimization process that optimizes camera poses and the dynamics of 3D Gaussian points based on 2D priors and scene clustering, ensuring fidelity among neighboring points and smooth movement across frames. Since dynamic scenes always introduce new content, we also propose a new pixel-wise densification strategy for Gaussian points to integrate new visual content. Moreover, GFlow transcends the boundaries of mere 4D reconstruction; it also enables tracking of any points across frames without the need for prior training and segments moving objects from the scene in an unsupervised way. Additionally, the camera poses of each frame can be derived from GFlow, allowing for rendering novel views of a video scene through changing camera pose. By employing the explicit representation, we may readily conduct scene-level or object-level editing as desired, underscoring its versatility and power. Visit our project website at: https://littlepure2333.github.io/GFlow
MindBridge: A Cross-Subject Brain Decoding Framework
Apr 11, 2024



Brain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models. In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific models. Furthermore, with limited data for a new subject, we achieve a high level of decoding accuracy, surpassing that of subject-specific models. This advancement in cross-subject brain decoding suggests promising directions for wider applications in neuroscience and indicates potential for more efficient utilization of limited fMRI data in real-world scenarios. Project page: https://littlepure2333.github.io/MindBridge
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023



Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/
SwiftAvatar: Efficient Auto-Creation of Parameterized Stylized Character on Arbitrary Avatar Engines
Jan 19, 2023The creation of a parameterized stylized character involves careful selection of numerous parameters, also known as the "avatar vectors" that can be interpreted by the avatar engine. Existing unsupervised avatar vector estimation methods that auto-create avatars for users, however, often fail to work because of the domain gap between realistic faces and stylized avatar images. To this end, we propose SwiftAvatar, a novel avatar auto-creation framework that is evidently superior to previous works. SwiftAvatar introduces dual-domain generators to create pairs of realistic faces and avatar images using shared latent codes. The latent codes can then be bridged with the avatar vectors as pairs, by performing GAN inversion on the avatar images rendered from the engine using avatar vectors. Through this way, we are able to synthesize paired data in high-quality as many as possible, consisting of avatar vectors and their corresponding realistic faces. We also propose semantic augmentation to improve the diversity of synthesis. Finally, a light-weight avatar vector estimator is trained on the synthetic pairs to implement efficient auto-creation. Our experiments demonstrate the effectiveness and efficiency of SwiftAvatar on two different avatar engines. The superiority and advantageous flexibility of SwiftAvatar are also verified in both subjective and objective evaluations.