 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest3R: Learning to Reconstruct 3D at Test Time
Jun 16, 2025Dense matching methods like DUSt3R regress pairwise pointmaps for 3D reconstruction. However, the reliance on pairwise prediction and the limited generalization capability inherently restrict the global geometric consistency. In this work, we introduce Test3R, a surprisingly simple test-time learning technique that significantly boosts geometric accuracy. Using image triplets ($I_1,I_2,I_3$), Test3R generates reconstructions from pairs ($I_1,I_2$) and ($I_1,I_3$). The core idea is to optimize the network at test time via a self-supervised objective: maximizing the geometric consistency between these two reconstructions relative to the common image $I_1$. This ensures the model produces cross-pair consistent outputs, regardless of the inputs. Extensive experiments demonstrate that our technique significantly outperforms previous state-of-the-art methods on the 3D reconstruction and multi-view depth estimation tasks. Moreover, it is universally applicable and nearly cost-free, making it easily applied to other models and implemented with minimal test-time training overhead and parameter footprint. Code is available at https://github.com/nopQAQ/Test3R.
1000+ FPS 4D Gaussian Splatting for Dynamic Scene Rendering
Mar 20, 2025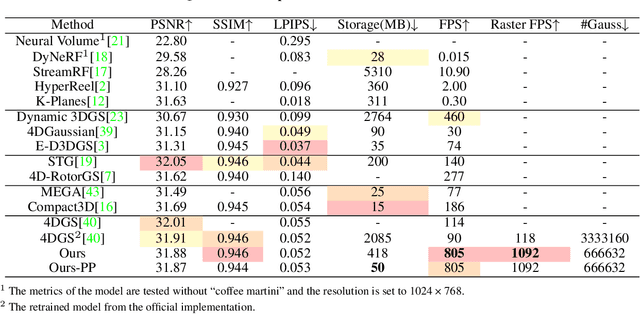
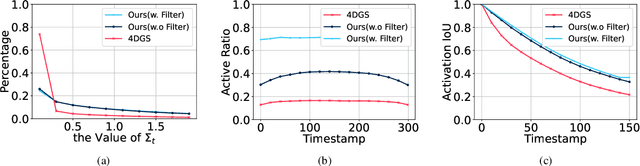
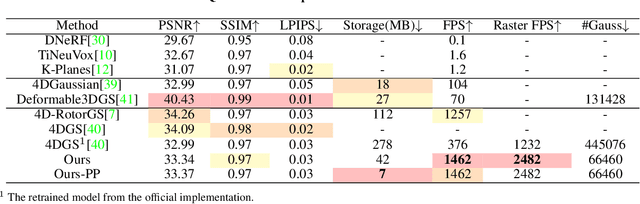

4D Gaussian Splatting (4DGS) has recently gained considerable attention as a method for reconstructing dynamic scenes. Despite achieving superior quality, 4DGS typically requires substantial storage and suffers from slow rendering speed. In this work, we delve into these issues and identify two key sources of temporal redundancy. (Q1) \textbf{Short-Lifespan Gaussians}: 4DGS uses a large portion of Gaussians with short temporal span to represent scene dynamics, leading to an excessive number of Gaussians. (Q2) \textbf{Inactive Gaussians}: When rendering, only a small subset of Gaussians contributes to each frame. Despite this, all Gaussians are processed during rasterization, resulting in redundant computation overhead. To address these redundancies, we present \textbf{4DGS-1K}, which runs at over 1000 FPS on modern GPUs. For Q1, we introduce the Spatial-Temporal Variation Score, a new pruning criterion that effectively removes short-lifespan Gaussians while encouraging 4DGS to capture scene dynamics using Gaussians with longer temporal spans. For Q2, we store a mask for active Gaussians across consecutive frames, significantly reducing redundant computations in rendering. Compared to vanilla 4DGS, our method achieves a $41\times$ reduction in storage and $9\times$ faster rasterization speed on complex dynamic scenes, while maintaining comparable visual quality. Please see our project page at https://4DGS-1K.github.io.
Seeing World Dynamics in a Nutshell
Feb 05, 2025



We consider the problem of efficiently representing casually captured monocular videos in a spatially- and temporally-coherent manner. While existing approaches predominantly rely on 2D/2.5D techniques treating videos as collections of spatiotemporal pixels, they struggle with complex motions, occlusions, and geometric consistency due to absence of temporal coherence and explicit 3D structure. Drawing inspiration from monocular video as a projection of the dynamic 3D world, we explore representing videos in their intrinsic 3D form through continuous flows of Gaussian primitives in space-time. In this paper, we propose NutWorld, a novel framework that efficiently transforms monocular videos into dynamic 3D Gaussian representations in a single forward pass. At its core, NutWorld introduces a structured spatial-temporal aligned Gaussian (STAG) representation, enabling optimization-free scene modeling with effective depth and flow regularization. Through comprehensive experiments, we demonstrate that NutWorld achieves high-fidelity video reconstruction quality while enabling various downstream applications in real-time. Demos and code will be available at https://github.com/Nut-World/NutWorld.
Poison-splat: Computation Cost Attack on 3D Gaussian Splatting
Oct 10, 2024



3D Gaussian splatting (3DGS), known for its groundbreaking performance and efficiency, has become a dominant 3D representation and brought progress to many 3D vision tasks. However, in this work, we reveal a significant security vulnerability that has been largely overlooked in 3DGS: the computation cost of training 3DGS could be maliciously tampered by poisoning the input data. By developing an attack named Poison-splat, we reveal a novel attack surface where the adversary can poison the input images to drastically increase the computation memory and time needed for 3DGS training, pushing the algorithm towards its worst computation complexity. In extreme cases, the attack can even consume all allocable memory, leading to a Denial-of-Service (DoS) that disrupts servers, resulting in practical damages to real-world 3DGS service vendors. Such a computation cost attack is achieved by addressing a bi-level optimization problem through three tailored strategies: attack objective approximation, proxy model rendering, and optional constrained optimization. These strategies not only ensure the effectiveness of our attack but also make it difficult to defend with simple defensive measures. We hope the revelation of this novel attack surface can spark attention to this crucial yet overlooked vulnerability of 3DGS systems.
Vista3D: Unravel the 3D Darkside of a Single Image
Sep 18, 2024We embark on the age-old quest: unveiling the hidden dimensions of objects from mere glimpses of their visible parts. To address this, we present Vista3D, a framework that realizes swift and consistent 3D generation within a mere 5 minutes. At the heart of Vista3D lies a two-phase approach: the coarse phase and the fine phase. In the coarse phase, we rapidly generate initial geometry with Gaussian Splatting from a single image. In the fine phase, we extract a Signed Distance Function (SDF) directly from learned Gaussian Splatting, optimizing it with a differentiable isosurface representation. Furthermore, it elevates the quality of generation by using a disentangled representation with two independent implicit functions to capture both visible and obscured aspects of objects. Additionally, it harmonizes gradients from 2D diffusion prior with 3D-aware diffusion priors by angular diffusion prior composition. Through extensive evaluation, we demonstrate that Vista3D effectively sustains a balance between the consistency and diversity of the generated 3D objects. Demos and code will be available at https://github.com/florinshen/Vista3D.
FlashSplat: 2D to 3D Gaussian Splatting Segmentation Solved Optimally
Sep 12, 2024This study addresses the challenge of accurately segmenting 3D Gaussian Splatting from 2D masks. Conventional methods often rely on iterative gradient descent to assign each Gaussian a unique label, leading to lengthy optimization and sub-optimal solutions. Instead, we propose a straightforward yet globally optimal solver for 3D-GS segmentation. The core insight of our method is that, with a reconstructed 3D-GS scene, the rendering of the 2D masks is essentially a linear function with respect to the labels of each Gaussian. As such, the optimal label assignment can be solved via linear programming in closed form. This solution capitalizes on the alpha blending characteristic of the splatting process for single step optimization. By incorporating the background bias in our objective function, our method shows superior robustness in 3D segmentation against noises. Remarkably, our optimization completes within 30 seconds, about 50$\times$ faster than the best existing methods. Extensive experiments demonstrate the efficiency and robustness of our method in segmenting various scenes, and its superior performance in downstream tasks such as object removal and inpainting. Demos and code will be available at https://github.com/florinshen/FlashSplat.
MVGamba: Unify 3D Content Generation as State Space Sequence Modeling
Jun 10, 2024



Recent 3D large reconstruction models (LRMs) can generate high-quality 3D content in sub-seconds by integrating multi-view diffusion models with scalable multi-view reconstructors. Current works further leverage 3D Gaussian Splatting as 3D representation for improved visual quality and rendering efficiency. However, we observe that existing Gaussian reconstruction models often suffer from multi-view inconsistency and blurred textures. We attribute this to the compromise of multi-view information propagation in favor of adopting powerful yet computationally intensive architectures (\eg, Transformers). To address this issue, we introduce MVGamba, a general and lightweight Gaussian reconstruction model featuring a multi-view Gaussian reconstructor based on the RNN-like State Space Model (SSM). Our Gaussian reconstructor propagates causal context containing multi-view information for cross-view self-refinement while generating a long sequence of Gaussians for fine-detail modeling with linear complexity. With off-the-shelf multi-view diffusion models integrated, MVGamba unifies 3D generation tasks from a single image, sparse images, or text prompts. Extensive experiments demonstrate that MVGamba outperforms state-of-the-art baselines in all 3D content generation scenarios with approximately only $0.1\times$ of the model size.
GFlow: Recovering 4D World from Monocular Video
May 28, 2024
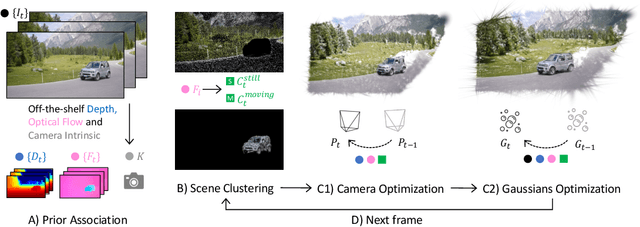


Reconstructing 4D scenes from video inputs is a crucial yet challenging task. Conventional methods usually rely on the assumptions of multi-view video inputs, known camera parameters, or static scenes, all of which are typically absent under in-the-wild scenarios. In this paper, we relax all these constraints and tackle a highly ambitious but practical task, which we termed as AnyV4D: we assume only one monocular video is available without any camera parameters as input, and we aim to recover the dynamic 4D world alongside the camera poses. To this end, we introduce GFlow, a new framework that utilizes only 2D priors (depth and optical flow) to lift a video (3D) to a 4D explicit representation, entailing a flow of Gaussian splatting through space and time. GFlow first clusters the scene into still and moving parts, then applies a sequential optimization process that optimizes camera poses and the dynamics of 3D Gaussian points based on 2D priors and scene clustering, ensuring fidelity among neighboring points and smooth movement across frames. Since dynamic scenes always introduce new content, we also propose a new pixel-wise densification strategy for Gaussian points to integrate new visual content. Moreover, GFlow transcends the boundaries of mere 4D reconstruction; it also enables tracking of any points across frames without the need for prior training and segments moving objects from the scene in an unsupervised way. Additionally, the camera poses of each frame can be derived from GFlow, allowing for rendering novel views of a video scene through changing camera pose. By employing the explicit representation, we may readily conduct scene-level or object-level editing as desired, underscoring its versatility and power. Visit our project website at: https://littlepure2333.github.io/GFlow
DragGaussian: Enabling Drag-style Manipulation on 3D Gaussian Representation
May 09, 2024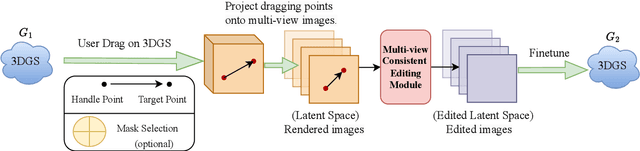
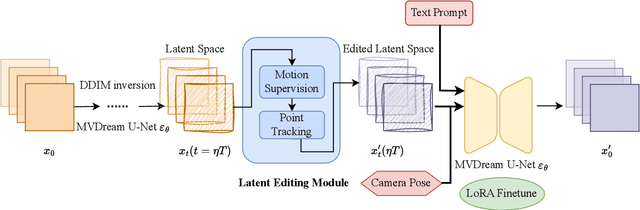
User-friendly 3D object editing is a challenging task that has attracted significant attention recently. The limitations of direct 3D object editing without 2D prior knowledge have prompted increased attention towards utilizing 2D generative models for 3D editing. While existing methods like Instruct NeRF-to-NeRF offer a solution, they often lack user-friendliness, particularly due to semantic guided editing. In the realm of 3D representation, 3D Gaussian Splatting emerges as a promising approach for its efficiency and natural explicit property, facilitating precise editing tasks. Building upon these insights, we propose DragGaussian, a 3D object drag-editing framework based on 3D Gaussian Splatting, leveraging diffusion models for interactive image editing with open-vocabulary input. This framework enables users to perform drag-based editing on pre-trained 3D Gaussian object models, producing modified 2D images through multi-view consistent editing. Our contributions include the introduction of a new task, the development of DragGaussian for interactive point-based 3D editing, and comprehensive validation of its effectiveness through qualitative and quantitative experiments.
Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
Mar 29, 2024



We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF). Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights: (1) 3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process; (2) Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians. Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset. Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 second on a single NVIDIA A100 GPU.