 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
May 31, 2026With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
DragGaussian: Enabling Drag-style Manipulation on 3D Gaussian Representation
May 09, 2024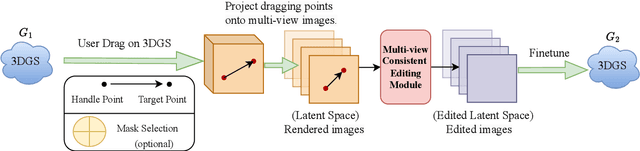
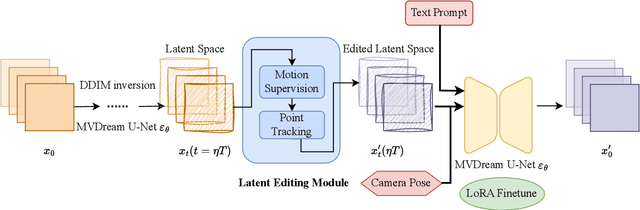
User-friendly 3D object editing is a challenging task that has attracted significant attention recently. The limitations of direct 3D object editing without 2D prior knowledge have prompted increased attention towards utilizing 2D generative models for 3D editing. While existing methods like Instruct NeRF-to-NeRF offer a solution, they often lack user-friendliness, particularly due to semantic guided editing. In the realm of 3D representation, 3D Gaussian Splatting emerges as a promising approach for its efficiency and natural explicit property, facilitating precise editing tasks. Building upon these insights, we propose DragGaussian, a 3D object drag-editing framework based on 3D Gaussian Splatting, leveraging diffusion models for interactive image editing with open-vocabulary input. This framework enables users to perform drag-based editing on pre-trained 3D Gaussian object models, producing modified 2D images through multi-view consistent editing. Our contributions include the introduction of a new task, the development of DragGaussian for interactive point-based 3D editing, and comprehensive validation of its effectiveness through qualitative and quantitative experiments.
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
May 25, 2023



Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2\% for zero-shot classification on OBJ\_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6\% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.