 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Robots Do the Chores: A Benchmark and Agent for Long-Horizon Household Task Execution
May 14, 2026Long-horizon household tasks demand robust high-level planning and sustained reasoning capabilities, which are largely overlooked by existing embodied AI benchmarks that emphasize short-horizon navigation or manipulation and rely on fixed task categories. We introduce LongAct, a benchmark designed to evaluate planning-level autonomy in long-horizon household tasks specified through free-form instructions. By abstracting away embodiment-specific low-level control, LongAct isolates high-level cognitive capabilities such as instruction understanding, dependency management, memory maintenance, and adaptive planning. We further propose HoloMind, a VLM-driven agent with a DAG-based long-horizon hierarchical planner, a Multimodal Spatial Memory for persistent world modeling, an Episodic Memory for experience reuse, and a global Critic for reflective supervision. Experiments with GPT-5 and Qwen3-VL models show that HoloMind substantially improves long-horizon performance while reducing reliance on model scale. Even top models achieve only 59% goal completion and 16% full-task success, underscoring the difficulty of LongAct and the need for stronger long-horizon planning in embodied agents.
Compander-Aligned Query Geometry for Quantized Zeroth-Order Optimization
May 11, 2026Low-bit forward evaluation is an attractive route to memory-efficient zeroth-order (ZO) adaptation: the optimizer needs only scalar losses, and the model can be queried near deployment precision. The obstacle is that a quantized ZO query is not a continuous finite difference followed by harmless storage rounding. The query chooses endpoints, the low-precision engine rounds them, and the loss difference is measured along the rounded chord. For nonuniform companding quantizers, this makes the codebook insufficient to predict ZO behavior: a fixed weight-space radius can collapse in dense cells, over-span sparse cells, or assign a rounded chord to an unrounded update direction. We identify the missing object as query geometry and model scalar nonuniform quantization as $Q = φ^{-1} \circ U \circ φ$. CAQ-ZO (Compander-Aligned Queries for Zeroth-Order Optimization) forms one-grid-step Rademacher stencils $z \pm Δr$ in $z = φ(x)$, maps endpoints back through $φ^{-1}$, and updates in $z$. Our theory proves the grid-span mismatch, decomposes endpoint-rounding estimator residuals, and gives stationarity bounds in which generic off-grid queries retain a $Δ^2/μ^2$ residual channel while CAQ-ZO makes the query-time residual exactly zero. Synthetic experiments isolate this channel, and matched NF4 Qwen/Llama fine-tuning shows that CAQ-ZO improves the trained NF4 baseline under the same quantizer and evaluation budget.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
May 25, 2023



Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2\% for zero-shot classification on OBJ\_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6\% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.
WeLM: A Well-Read Pre-trained Language Model for Chinese
Oct 12, 2022
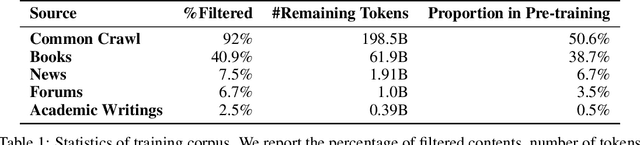
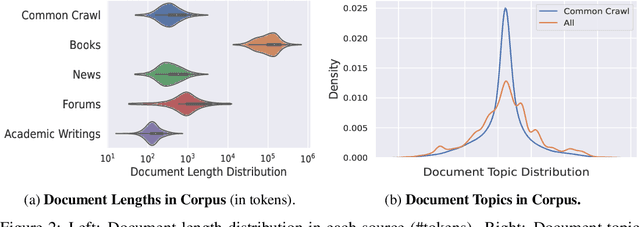

Large Language Models pre-trained with self-supervised learning have demonstrated impressive zero-shot generalization capabilities on a wide spectrum of tasks. In this work, we present WeLM: a well-read pre-trained language model for Chinese that is able to seamlessly perform different types of tasks with zero or few-shot demonstrations. WeLM is trained with 10B parameters by "reading" a curated high-quality corpus covering a wide range of topics. We show that WeLM is equipped with broad knowledge on various domains and languages. On 18 monolingual (Chinese) tasks, WeLM can significantly outperform existing pre-trained models with similar sizes and match the performance of models up to 25 times larger. WeLM also exhibits strong capabilities in multi-lingual and code-switching understanding, outperforming existing multilingual language models pre-trained on 30 languages. Furthermore, We collected human-written prompts for a large set of supervised datasets in Chinese and fine-tuned WeLM with multi-prompted training. The resulting model can attain strong generalization on unseen types of tasks and outperform the unsupervised WeLM in zero-shot learning. Finally, we demonstrate that WeLM has basic skills at explaining and calibrating the decisions from itself, which can be promising directions for future research. Our models can be applied from https://welm.weixin.qq.com/docs/api/.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020
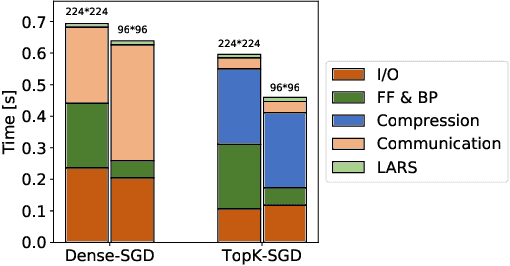
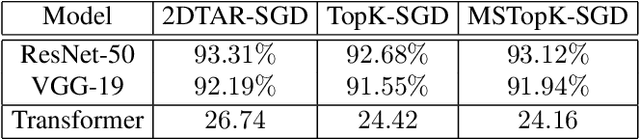
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.