 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeLM: A Well-Read Pre-trained Language Model for Chinese
Oct 12, 2022
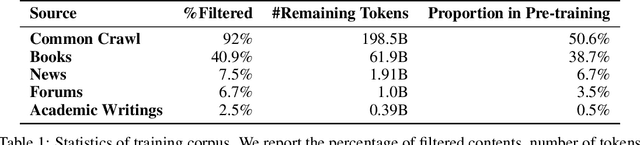
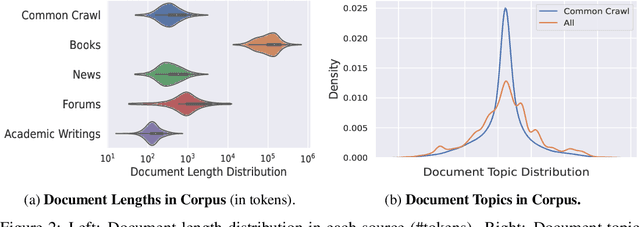

Large Language Models pre-trained with self-supervised learning have demonstrated impressive zero-shot generalization capabilities on a wide spectrum of tasks. In this work, we present WeLM: a well-read pre-trained language model for Chinese that is able to seamlessly perform different types of tasks with zero or few-shot demonstrations. WeLM is trained with 10B parameters by "reading" a curated high-quality corpus covering a wide range of topics. We show that WeLM is equipped with broad knowledge on various domains and languages. On 18 monolingual (Chinese) tasks, WeLM can significantly outperform existing pre-trained models with similar sizes and match the performance of models up to 25 times larger. WeLM also exhibits strong capabilities in multi-lingual and code-switching understanding, outperforming existing multilingual language models pre-trained on 30 languages. Furthermore, We collected human-written prompts for a large set of supervised datasets in Chinese and fine-tuned WeLM with multi-prompted training. The resulting model can attain strong generalization on unseen types of tasks and outperform the unsupervised WeLM in zero-shot learning. Finally, we demonstrate that WeLM has basic skills at explaining and calibrating the decisions from itself, which can be promising directions for future research. Our models can be applied from https://welm.weixin.qq.com/docs/api/.
A Robust and Domain-Adaptive Approach for Low-Resource Named Entity Recognition
Jan 02, 2021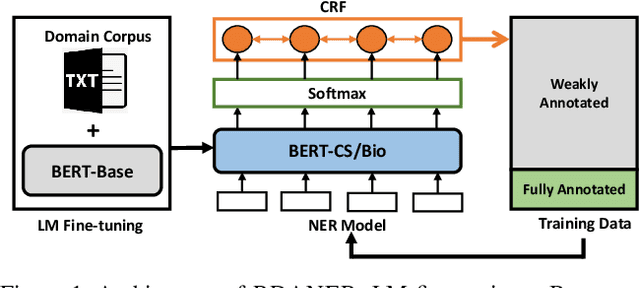
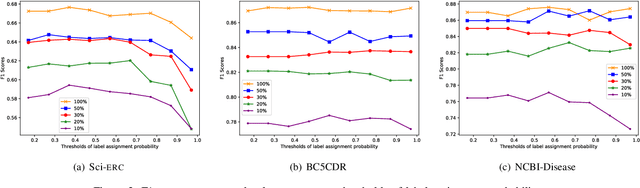

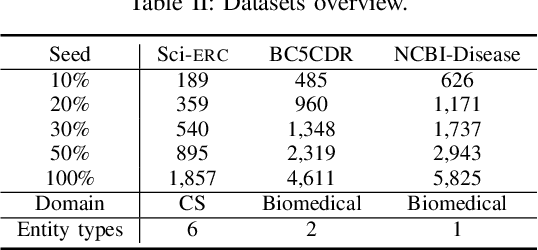
Recently, it has attracted much attention to build reliable named entity recognition (NER) systems using limited annotated data. Nearly all existing works heavily rely on domain-specific resources, such as external lexicons and knowledge bases. However, such domain-specific resources are often not available, meanwhile it's difficult and expensive to construct the resources, which has become a key obstacle to wider adoption. To tackle the problem, in this work, we propose a novel robust and domain-adaptive approach RDANER for low-resource NER, which only uses cheap and easily obtainable resources. Extensive experiments on three benchmark datasets demonstrate that our approach achieves the best performance when only using cheap and easily obtainable resources, and delivers competitive results against state-of-the-art methods which use difficultly obtainable domainspecific resources. All our code and corpora can be found on https://github.com/houking-can/RDANER.
* Best Student Paper of 2020 IEEE International Conference on Knowledge Graph (ICKG)
Complicated Table Structure Recognition
Aug 28, 2019
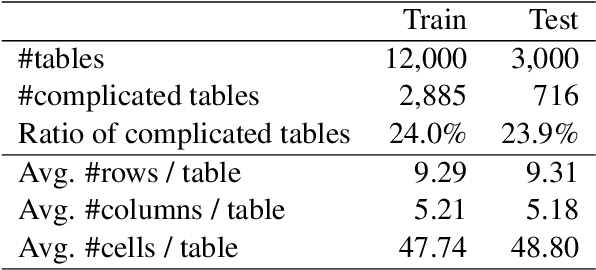
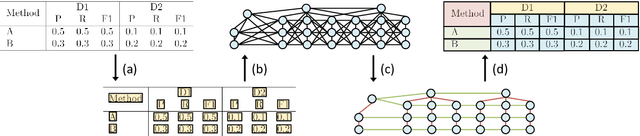
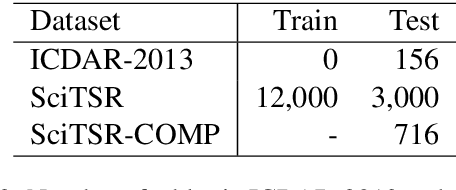
The task of table structure recognition aims to recognize the internal structure of a table, which is a key step to make machines understand tables. Currently, there are lots of studies on this task for different file formats such as ASCII text and HTML. It also attracts lots of attention to recognize the table structures in PDF files. However, it is hard for the existing methods to accurately recognize the structure of complicated tables in PDF files. The complicated tables contain spanning cells which occupy at least two columns or rows. To address the issue, we propose a novel graph neural network for recognizing the table structure in PDF files, named GraphTSR. Specifically, it takes table cells as input, and then recognizes the table structures by predicting relations among cells. Moreover, to evaluate the task better, we construct a large-scale table structure recognition dataset from scientific papers, named SciTSR, which contains 15,000 tables from PDF files and their corresponding structure labels. Extensive experiments demonstrate that our proposed model is highly effective for complicated tables and outperforms state-of-the-art baselines over a benchmark dataset and our new constructed dataset.