 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025



The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
PipeDiT: Accelerating Diffusion Transformers in Video Generation with Task Pipelining and Model Decoupling
Nov 15, 2025Video generation has been advancing rapidly, and diffusion transformer (DiT) based models have demonstrated remark- able capabilities. However, their practical deployment is of- ten hindered by slow inference speeds and high memory con- sumption. In this paper, we propose a novel pipelining frame- work named PipeDiT to accelerate video generation, which is equipped with three main innovations. First, we design a pipelining algorithm (PipeSP) for sequence parallelism (SP) to enable the computation of latent generation and commu- nication among multiple GPUs to be pipelined, thus reduc- ing inference latency. Second, we propose DeDiVAE to de- couple the diffusion module and the variational autoencoder (VAE) module into two GPU groups, whose executions can also be pipelined to reduce memory consumption and infer- ence latency. Third, to better utilize the GPU resources in the VAE group, we propose an attention co-processing (Aco) method to further reduce the overall video generation latency. We integrate our PipeDiT into both OpenSoraPlan and Hun- yuanVideo, two state-of-the-art open-source video generation frameworks, and conduct extensive experiments on two 8- GPU systems. Experimental results show that, under many common resolution and timestep configurations, our PipeDiT achieves 1.06x to 4.02x speedups over OpenSoraPlan and HunyuanVideo.
FSMoE: A Flexible and Scalable Training System for Sparse Mixture-of-Experts Models
Jan 18, 2025



Recent large language models (LLMs) have tended to leverage sparsity to reduce computations, employing the sparsely activated mixture-of-experts (MoE) technique. MoE introduces four modules, including token routing, token communication, expert computation, and expert parallelism, that impact model quality and training efficiency. To enable versatile usage of MoE models, we introduce FSMoE, a flexible training system optimizing task scheduling with three novel techniques: 1) Unified abstraction and online profiling of MoE modules for task scheduling across various MoE implementations. 2) Co-scheduling intra-node and inter-node communications with computations to minimize communication overheads. 3) To support near-optimal task scheduling, we design an adaptive gradient partitioning method for gradient aggregation and a schedule to adaptively pipeline communications and computations. We conduct extensive experiments with configured MoE layers and real-world MoE models on two GPU clusters. Experimental results show that 1) our FSMoE supports four popular types of MoE routing functions and is more efficient than existing implementations (with up to a 1.42$\times$ speedup), and 2) FSMoE outperforms the state-of-the-art MoE training systems (DeepSpeed-MoE and Tutel) by 1.18$\times$-1.22$\times$ on 1458 MoE layers and 1.19$\times$-3.01$\times$ on real-world MoE models based on GPT-2 and Mixtral using a popular routing function.
ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
Oct 23, 2024



Sparse Mixture of Experts (MoE) models, while outperforming dense Large Language Models (LLMs) in terms of performance, face significant deployment challenges during inference due to their high memory demands. Existing offloading techniques, which involve swapping activated and idle experts between the GPU and CPU, often suffer from rigid expert caching mechanisms. These mechanisms fail to adapt to dynamic routing, leading to inefficient cache utilization, or incur prohibitive costs for prediction training. To tackle these inference-specific challenges, we introduce ExpertFlow, a comprehensive system specifically designed to enhance inference efficiency by accommodating flexible routing and enabling efficient expert scheduling between CPU and GPU. This reduces overhead and boosts system performance. Central to our approach is a predictive routing path-based offloading mechanism that utilizes a lightweight predictor to accurately forecast routing paths before computation begins. This proactive strategy allows for real-time error correction in expert caching, significantly increasing cache hit ratios and reducing the frequency of expert transfers, thereby minimizing I/O overhead. Additionally, we implement a dynamic token scheduling strategy that optimizes MoE inference by rearranging input tokens across different batches. This method not only reduces the number of activated experts per batch but also improves computational efficiency. Our extensive experiments demonstrate that ExpertFlow achieves up to 93.72\% GPU memory savings and enhances inference speed by 2 to 10 times compared to baseline methods, highlighting its effectiveness and utility as a robust solution for resource-constrained inference scenarios.
FusionLLM: A Decentralized LLM Training System on Geo-distributed GPUs with Adaptive Compression
Oct 16, 2024



To alleviate hardware scarcity in training large deep neural networks (DNNs), particularly large language models (LLMs), we present FusionLLM, a decentralized training system designed and implemented for training DNNs using geo-distributed GPUs across different computing clusters or individual devices. Decentralized training faces significant challenges regarding system design and efficiency, including: 1) the need for remote automatic differentiation (RAD), 2) support for flexible model definitions and heterogeneous software, 3) heterogeneous hardware leading to low resource utilization or the straggler problem, and 4) slow network communication. To address these challenges, in the system design, we represent the model as a directed acyclic graph of operators (OP-DAG). Each node in the DAG represents the operator in the DNNs, while the edge represents the data dependency between operators. Based on this design, 1) users are allowed to customize any DNN without caring low-level operator implementation; 2) we enable the task scheduling with the more fine-grained sub-tasks, offering more optimization space; 3) a DAG runtime executor can implement RAD withour requiring the consistent low-level ML framework versions. To enhance system efficiency, we implement a workload estimator and design an OP-Fence scheduler to cluster devices with similar bandwidths together and partition the DAG to increase throughput. Additionally, we propose an AdaTopK compressor to adaptively compress intermediate activations and gradients at the slowest communication links. To evaluate the convergence and efficiency of our system and algorithms, we train ResNet-101 and GPT-2 on three real-world testbeds using 48 GPUs connected with 8 Mbps~10 Gbps networks. Experimental results demonstrate that our system and method can achieve 1.45 - 9.39x speedup compared to baseline methods while ensuring convergence.
Bandwidth-Aware and Overlap-Weighted Compression for Communication-Efficient Federated Learning
Aug 27, 2024
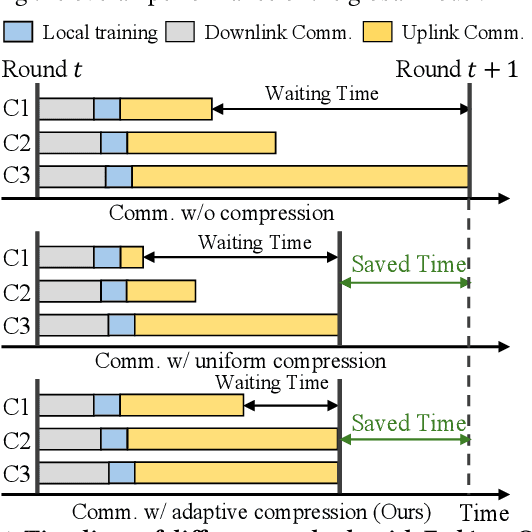

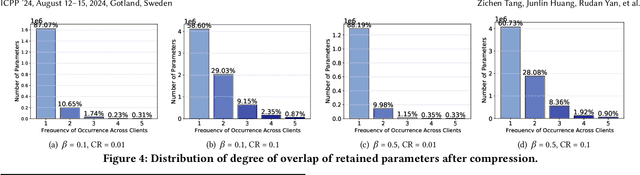
Current data compression methods, such as sparsification in Federated Averaging (FedAvg), effectively enhance the communication efficiency of Federated Learning (FL). However, these methods encounter challenges such as the straggler problem and diminished model performance due to heterogeneous bandwidth and non-IID (Independently and Identically Distributed) data. To address these issues, we introduce a bandwidth-aware compression framework for FL, aimed at improving communication efficiency while mitigating the problems associated with non-IID data. First, our strategy dynamically adjusts compression ratios according to bandwidth, enabling clients to upload their models at a close pace, thus exploiting the otherwise wasted time to transmit more data. Second, we identify the non-overlapped pattern of retained parameters after compression, which results in diminished client update signals due to uniformly averaged weights. Based on this finding, we propose a parameter mask to adjust the client-averaging coefficients at the parameter level, thereby more closely approximating the original updates, and improving the training convergence under heterogeneous environments. Our evaluations reveal that our method significantly boosts model accuracy, with a maximum improvement of 13% over the uncompressed FedAvg. Moreover, it achieves a $3.37\times$ speedup in reaching the target accuracy compared to FedAvg with a Top-K compressor, demonstrating its effectiveness in accelerating convergence with compression. The integration of common compression techniques into our framework further establishes its potential as a versatile foundation for future cross-device, communication-efficient FL research, addressing critical challenges in FL and advancing the field of distributed machine learning.
Parm: Efficient Training of Large Sparsely-Activated Models with Dedicated Schedules
Jun 30, 2024Sparsely-activated Mixture-of-Expert (MoE) layers have found practical applications in enlarging the model size of large-scale foundation models, with only a sub-linear increase in computation demands. Despite the wide adoption of hybrid parallel paradigms like model parallelism, expert parallelism, and expert-sharding parallelism (i.e., MP+EP+ESP) to support MoE model training on GPU clusters, the training efficiency is hindered by communication costs introduced by these parallel paradigms. To address this limitation, we propose Parm, a system that accelerates MP+EP+ESP training by designing two dedicated schedules for placing communication tasks. The proposed schedules eliminate redundant computations and communications and enable overlaps between intra-node and inter-node communications, ultimately reducing the overall training time. As the two schedules are not mutually exclusive, we provide comprehensive theoretical analyses and derive an automatic and accurate solution to determine which schedule should be applied in different scenarios. Experimental results on an 8-GPU server and a 32-GPU cluster demonstrate that Parm outperforms the state-of-the-art MoE training system, DeepSpeed-MoE, achieving 1.13$\times$ to 5.77$\times$ speedup on 1296 manually configured MoE layers and approximately 3$\times$ improvement on two real-world MoE models based on BERT and GPT-2.
FedImpro: Measuring and Improving Client Update in Federated Learning
Feb 10, 2024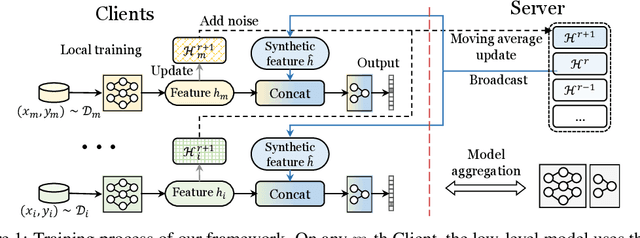
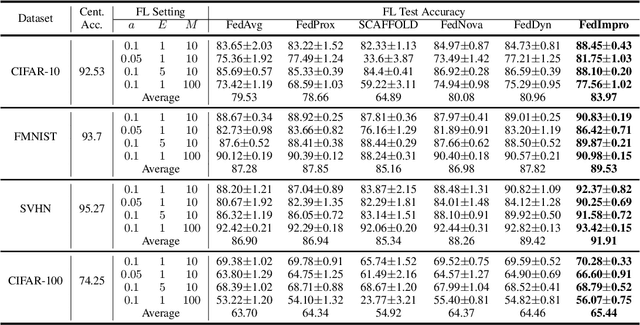

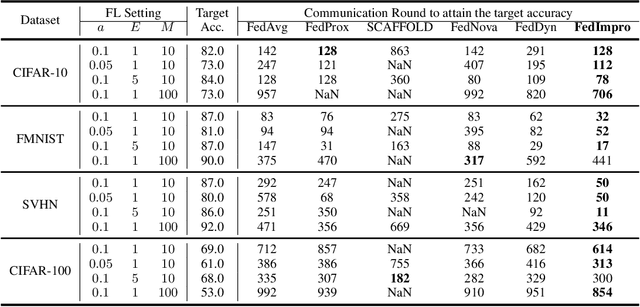
Federated Learning (FL) models often experience client drift caused by heterogeneous data, where the distribution of data differs across clients. To address this issue, advanced research primarily focuses on manipulating the existing gradients to achieve more consistent client models. In this paper, we present an alternative perspective on client drift and aim to mitigate it by generating improved local models. First, we analyze the generalization contribution of local training and conclude that this generalization contribution is bounded by the conditional Wasserstein distance between the data distribution of different clients. Then, we propose FedImpro, to construct similar conditional distributions for local training. Specifically, FedImpro decouples the model into high-level and low-level components, and trains the high-level portion on reconstructed feature distributions. This approach enhances the generalization contribution and reduces the dissimilarity of gradients in FL. Experimental results show that FedImpro can help FL defend against data heterogeneity and enhance the generalization performance of the model.
Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
Nov 07, 2023Large Language Models (LLMs) have seen great advance in both academia and industry, and their popularity results in numerous open-source frameworks and techniques in accelerating LLM pre-training, fine-tuning, and inference. Training and deploying LLMs are expensive as it requires considerable computing resources and memory, hence many efficient approaches have been developed for improving system pipelines as well as operators. However, the runtime performance can vary significantly across hardware and software stacks, which makes it difficult to choose the best configuration. In this work, we aim to benchmark the performance from both macro and micro perspectives. First, we benchmark the end-to-end performance of pre-training, fine-tuning, and serving LLMs in different sizes , i.e., 7, 13, and 70 billion parameters (7B, 13B, and 70B) on three 8-GPU platforms with and without individual optimization techniques, including ZeRO, quantization, recomputation, FlashAttention. Then, we dive deeper to provide a detailed runtime analysis of the sub-modules, including computing and communication operators in LLMs. For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs. For researchers, our in-depth module-wise analyses discover potential opportunities for future work to further optimize the runtime performance of LLMs.
FusionAI: Decentralized Training and Deploying LLMs with Massive Consumer-Level GPUs
Sep 03, 2023



The rapid growth of memory and computation requirements of large language models (LLMs) has outpaced the development of hardware, hindering people who lack large-scale high-end GPUs from training or deploying LLMs. However, consumer-level GPUs, which constitute a larger market share, are typically overlooked in LLM due to their weaker computing performance, smaller storage capacity, and lower communication bandwidth. Additionally, users may have privacy concerns when interacting with remote LLMs. In this paper, we envision a decentralized system unlocking the potential vast untapped consumer-level GPUs in pre-training, inference and fine-tuning of LLMs with privacy protection. However, this system faces critical challenges, including limited CPU and GPU memory, low network bandwidth, the variability of peer and device heterogeneity. To address these challenges, our system design incorporates: 1) a broker with backup pool to implement dynamic join and quit of computing providers; 2) task scheduling with hardware performance to improve system efficiency; 3) abstracting ML procedures into directed acyclic graphs (DAGs) to achieve model and task universality; 4) abstracting intermediate represention and execution planes to ensure compatibility of various devices and deep learning (DL) frameworks. Our performance analysis demonstrates that 50 RTX 3080 GPUs can achieve throughputs comparable to those of 4 H100 GPUs, which are significantly more expensive.