 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawback of Enforcing Equivariance and its Compensation via the Lens of Expressive Power
Dec 10, 2025Equivariant neural networks encode symmetry as an inductive bias and have achieved strong empirical performance in wide domains. However, their expressive power remains not well understood. Focusing on 2-layer ReLU networks, this paper investigates the impact of equivariance constraints on the expressivity of equivariant and layer-wise equivariant networks. By examining the boundary hyperplanes and the channel vectors of ReLU networks, we construct an example showing that equivariance constraints could strictly limit expressive power. However, we demonstrate that this drawback can be compensated via enlarging the model size. Furthermore, we show that despite a larger model size, the resulting architecture could still correspond to a hypothesis space with lower complexity, implying superior generalizability for equivariant networks.
Enhancing Target-unspecific Tasks through a Features Matrix
May 07, 2025Recent developments in prompt learning of large vision-language models have significantly improved performance in target-specific tasks. However, these prompt optimizing methods often struggle to tackle the target-unspecific or generalizable tasks effectively. It may be attributed to the fact that overfitting training causes the model to forget its general knowledge having strong promotion on target-unspecific tasks. To alleviate this issue, we propose a novel Features Matrix (FM) regularization approach designed to enhance these models on target-unspecific tasks. Our method extracts and leverages general knowledge, shaping a Features Matrix (FM). Specifically, the FM captures the semantics of diverse inputs from a deep and fine perspective, preserving essential general knowledge, which mitigates the risk of overfitting. Representative evaluations demonstrate that: 1) the FM is compatible with existing frameworks as a generic and flexible module, and 2) the FM significantly showcases its effectiveness in enhancing target-unspecific tasks, achieving state-of-the-art performance.
* ICML 2025
Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs
Apr 15, 2025
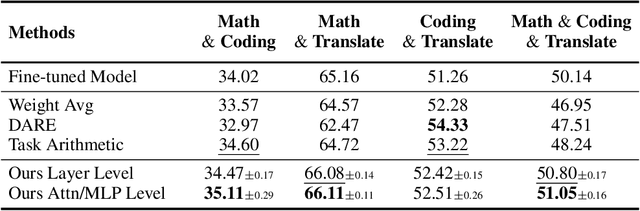

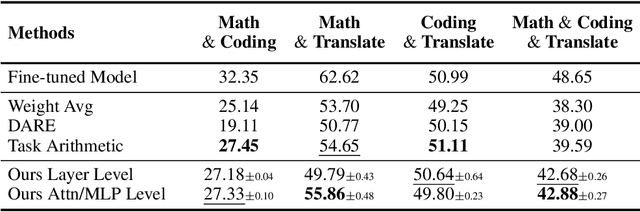
Task arithmetic is a straightforward yet highly effective strategy for model merging, enabling the resultant model to exhibit multi-task capabilities. Recent research indicates that models demonstrating linearity enhance the performance of task arithmetic. In contrast to existing methods that rely on the global linearization of the model, we argue that this linearity already exists within the model's submodules. In particular, we present a statistical analysis and show that submodules (e.g., layers, self-attentions, and MLPs) exhibit significantly higher linearity than the overall model. Based on these findings, we propose an innovative model merging strategy that independently merges these submodules. Especially, we derive a closed-form solution for optimal merging weights grounded in the linear properties of these submodules. Experimental results demonstrate that our method consistently outperforms the standard task arithmetic approach and other established baselines across different model scales and various tasks. This result highlights the benefits of leveraging the linearity of submodules and provides a new perspective for exploring solutions for effective and practical multi-task model merging.
A Theoretical Perspective: How to Prevent Model Collapse in Self-consuming Training Loops
Feb 26, 2025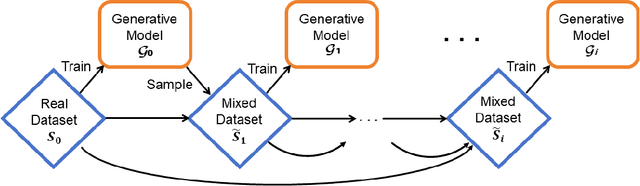
High-quality data is essential for training large generative models, yet the vast reservoir of real data available online has become nearly depleted. Consequently, models increasingly generate their own data for further training, forming Self-consuming Training Loops (STLs). However, the empirical results have been strikingly inconsistent: some models degrade or even collapse, while others successfully avoid these failures, leaving a significant gap in theoretical understanding to explain this discrepancy. This paper introduces the intriguing notion of recursive stability and presents the first theoretical generalization analysis, revealing how both model architecture and the proportion between real and synthetic data influence the success of STLs. We further extend this analysis to transformers in in-context learning, showing that even a constant-sized proportion of real data ensures convergence, while also providing insights into optimal synthetic data sizing.
A Similarity Paradigm Through Textual Regularization Without Forgetting
Feb 20, 2025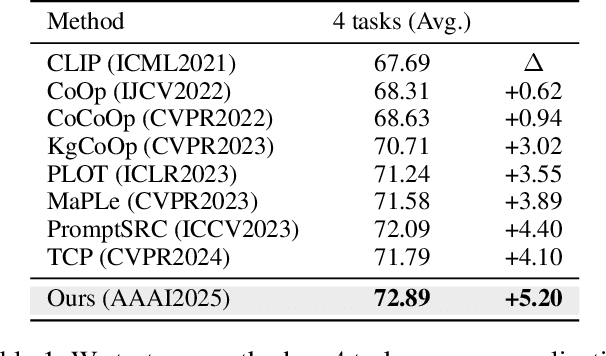
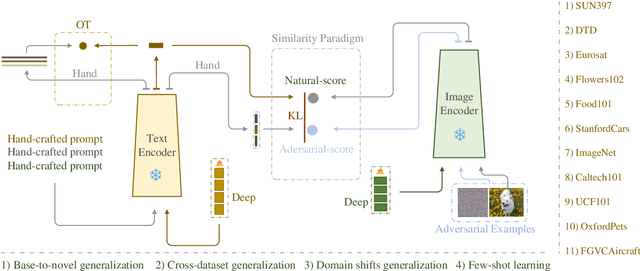
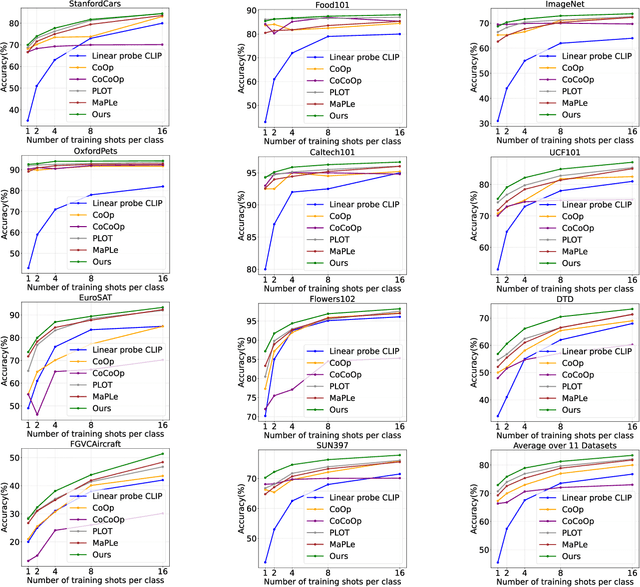
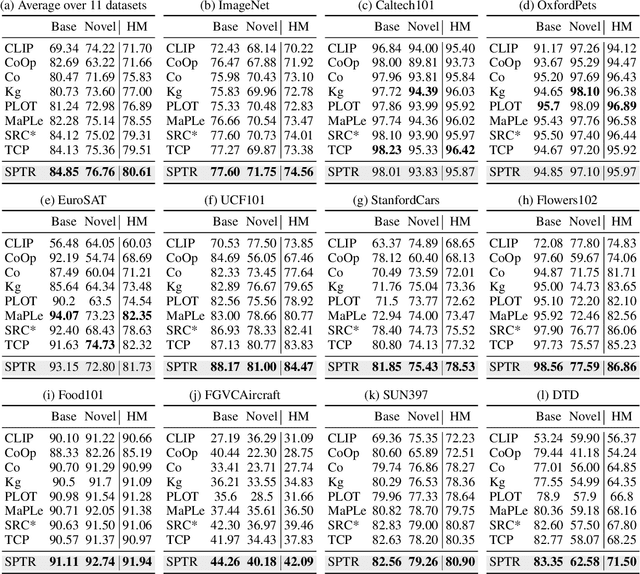
Prompt learning has emerged as a promising method for adapting pre-trained visual-language models (VLMs) to a range of downstream tasks. While optimizing the context can be effective for improving performance on specific tasks, it can often lead to poor generalization performance on unseen classes or datasets sampled from different distributions. It may be attributed to the fact that textual prompts tend to overfit downstream data distributions, leading to the forgetting of generalized knowledge derived from hand-crafted prompts. In this paper, we propose a novel method called Similarity Paradigm with Textual Regularization (SPTR) for prompt learning without forgetting. SPTR is a two-pronged design based on hand-crafted prompts that is an inseparable framework. 1) To avoid forgetting general textual knowledge, we introduce the optimal transport as a textual regularization to finely ensure approximation with hand-crafted features and tuning textual features. 2) In order to continuously unleash the general ability of multiple hand-crafted prompts, we propose a similarity paradigm for natural alignment score and adversarial alignment score to improve model robustness for generalization. Both modules share a common objective in addressing generalization issues, aiming to maximize the generalization capability derived from multiple hand-crafted prompts. Four representative tasks (i.e., non-generalization few-shot learning, base-to-novel generalization, cross-dataset generalization, domain generalization) across 11 datasets demonstrate that SPTR outperforms existing prompt learning methods.
HRP: High-Rank Preheating for Superior LoRA Initialization
Feb 11, 2025This paper studies the crucial impact of initialization on the convergence properties of Low-Rank Adaptation (LoRA). We theoretically demonstrate that random initialization, a widely used schema, will likely lead LoRA to random low-rank results, rather than the best low-rank result. While this issue can be mitigated by adjusting initialization towards a well-informed direction, it relies on prior knowledge of the target, which is typically unknown in real-world scenarios. To approximate this well-informed initial direction, we propose High-Rank Preheating (HRP), which fine-tunes high-rank LoRA for a few steps and uses the singular value decomposition of the preheated result as a superior initialization. HRP initialization is theory-supported to combine the convergence strengths of high-rank LoRA and the generalization strengths of low-rank LoRA. Extensive experiments demonstrate that HRP significantly enhances LoRA's effectiveness across various models and tasks, achieving performance comparable to full-parameter fine-tuning and outperforming other initialization strategies.
Detecting Discrepancies Between AI-Generated and Natural Images Using Uncertainty
Dec 08, 2024



In this work, we propose a novel approach for detecting AI-generated images by leveraging predictive uncertainty to mitigate misuse and associated risks. The motivation arises from the fundamental assumption regarding the distributional discrepancy between natural and AI-generated images. The feasibility of distinguishing natural images from AI-generated ones is grounded in the distribution discrepancy between them. Predictive uncertainty offers an effective approach for capturing distribution shifts, thereby providing insights into detecting AI-generated images. Namely, as the distribution shift between training and testing data increases, model performance typically degrades, often accompanied by increased predictive uncertainty. Therefore, we propose to employ predictive uncertainty to reflect the discrepancies between AI-generated and natural images. In this context, the challenge lies in ensuring that the model has been trained over sufficient natural images to avoid the risk of determining the distribution of natural images as that of generated images. We propose to leverage large-scale pre-trained models to calculate the uncertainty as the score for detecting AI-generated images. This leads to a simple yet effective method for detecting AI-generated images using large-scale vision models: images that induce high uncertainty are identified as AI-generated. Comprehensive experiments across multiple benchmarks demonstrate the effectiveness of our method.
Interpreting and Improving Large Language Models in Arithmetic Calculation
Sep 03, 2024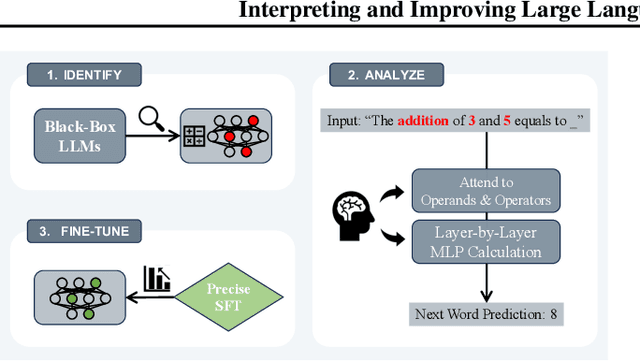
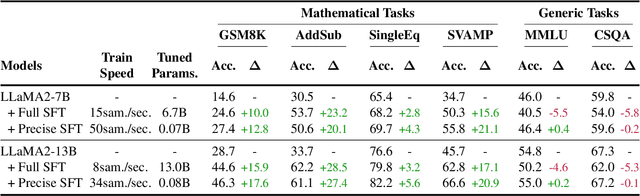
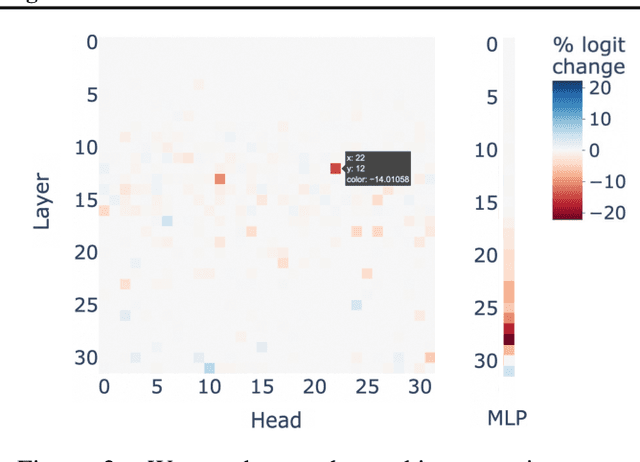
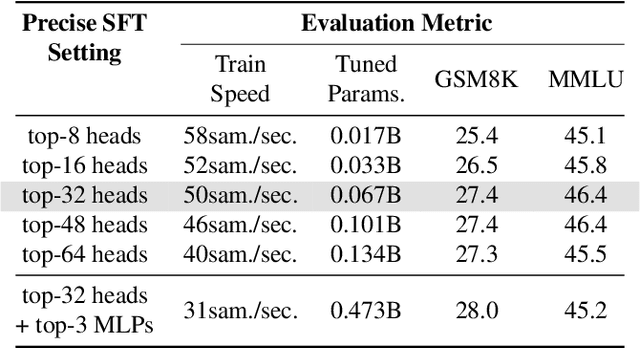
Large language models (LLMs) have demonstrated remarkable potential across numerous applications and have shown an emergent ability to tackle complex reasoning tasks, such as mathematical computations. However, even for the simplest arithmetic calculations, the intrinsic mechanisms behind LLMs remain mysterious, making it challenging to ensure reliability. In this work, we delve into uncovering a specific mechanism by which LLMs execute calculations. Through comprehensive experiments, we find that LLMs frequently involve a small fraction (< 5%) of attention heads, which play a pivotal role in focusing on operands and operators during calculation processes. Subsequently, the information from these operands is processed through multi-layer perceptrons (MLPs), progressively leading to the final solution. These pivotal heads/MLPs, though identified on a specific dataset, exhibit transferability across different datasets and even distinct tasks. This insight prompted us to investigate the potential benefits of selectively fine-tuning these essential heads/MLPs to boost the LLMs' computational performance. We empirically find that such precise tuning can yield notable enhancements on mathematical prowess, without compromising the performance on non-mathematical tasks. Our work serves as a preliminary exploration into the arithmetic calculation abilities inherent in LLMs, laying a solid foundation to reveal more intricate mathematical tasks.
From Yes-Men to Truth-Tellers: Addressing Sycophancy in Large Language Models with Pinpoint Tuning
Sep 03, 2024



Large Language Models (LLMs) tend to prioritize adherence to user prompts over providing veracious responses, leading to the sycophancy issue. When challenged by users, LLMs tend to admit mistakes and provide inaccurate responses even if they initially provided the correct answer. Recent works propose to employ supervised fine-tuning (SFT) to mitigate the sycophancy issue, while it typically leads to the degeneration of LLMs' general capability. To address the challenge, we propose a novel supervised pinpoint tuning (SPT), where the region-of-interest modules are tuned for a given objective. Specifically, SPT first reveals and verifies a small percentage (<5%) of the basic modules, which significantly affect a particular behavior of LLMs. i.e., sycophancy. Subsequently, SPT merely fine-tunes these identified modules while freezing the rest. To verify the effectiveness of the proposed SPT, we conduct comprehensive experiments, demonstrating that SPT significantly mitigates the sycophancy issue of LLMs (even better than SFT). Moreover, SPT introduces limited or even no side effects on the general capability of LLMs. Our results shed light on how to precisely, effectively, and efficiently explain and improve the targeted ability of LLMs.
Advancing Prompt Learning through an External Layer
Jul 29, 2024



Prompt learning represents a promising method for adapting pre-trained visual-language models (VLMs) to various downstream tasks by learning a set of text embeddings. One challenge inherent to these methods is the poor generalization performance due to the invalidity of the learned text embeddings for unseen tasks. A straightforward approach to bridge this gap is to freeze the text embeddings in prompts, which results in a lack of capacity to adapt VLMs for downstream tasks. To address this dilemma, we proposeto introduce an External Layer (EnLa) of text branch and learnable visual embeddings of the visual branch for adapting VLMs to downstream tasks. The learnable external layer is built upon valid embeddings of pre-trained CLIP. This design considers the balance of learning capabilities between the two branches. To align the textual and visual features, we propose a novel two-pronged approach: i) we introduce the optimal transport as the discrepancy metric to align the vision and text modalities, and ii) we introducea novel strengthening feature to enhance the interaction between these two modalities. Extensive experiments show that our method performs favorably well on 4 types of representative tasks across 11 datasets compared to the existing prompt learning methods.