 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Similarity Paradigm Through Textual Regularization Without Forgetting
Feb 20, 2025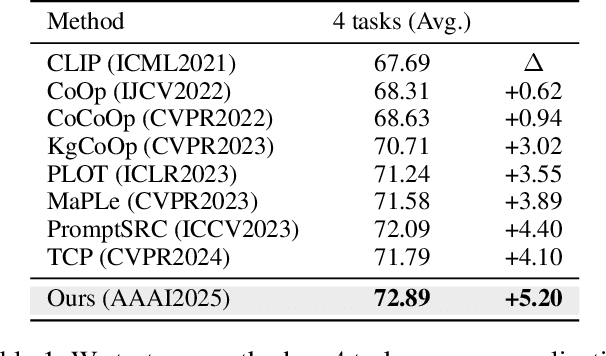
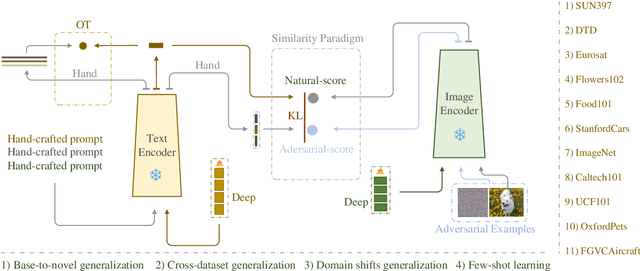
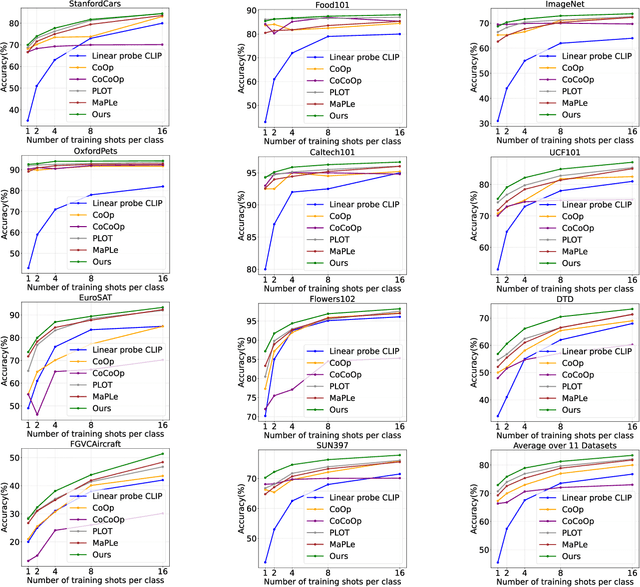
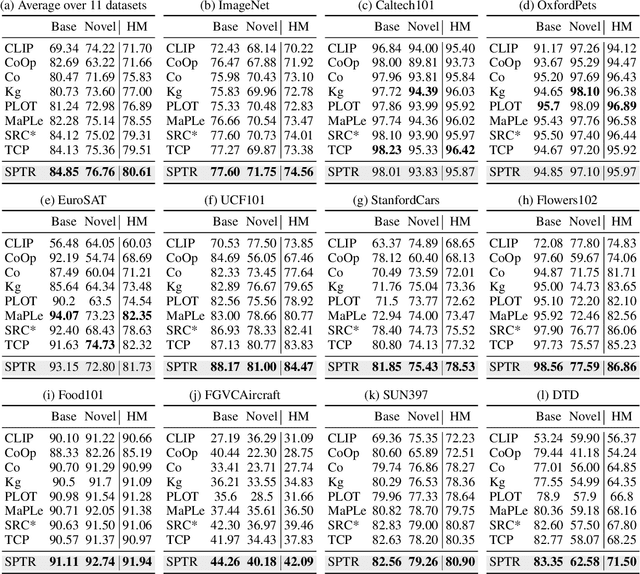
Prompt learning has emerged as a promising method for adapting pre-trained visual-language models (VLMs) to a range of downstream tasks. While optimizing the context can be effective for improving performance on specific tasks, it can often lead to poor generalization performance on unseen classes or datasets sampled from different distributions. It may be attributed to the fact that textual prompts tend to overfit downstream data distributions, leading to the forgetting of generalized knowledge derived from hand-crafted prompts. In this paper, we propose a novel method called Similarity Paradigm with Textual Regularization (SPTR) for prompt learning without forgetting. SPTR is a two-pronged design based on hand-crafted prompts that is an inseparable framework. 1) To avoid forgetting general textual knowledge, we introduce the optimal transport as a textual regularization to finely ensure approximation with hand-crafted features and tuning textual features. 2) In order to continuously unleash the general ability of multiple hand-crafted prompts, we propose a similarity paradigm for natural alignment score and adversarial alignment score to improve model robustness for generalization. Both modules share a common objective in addressing generalization issues, aiming to maximize the generalization capability derived from multiple hand-crafted prompts. Four representative tasks (i.e., non-generalization few-shot learning, base-to-novel generalization, cross-dataset generalization, domain generalization) across 11 datasets demonstrate that SPTR outperforms existing prompt learning methods.
FusionLLM: A Decentralized LLM Training System on Geo-distributed GPUs with Adaptive Compression
Oct 16, 2024



To alleviate hardware scarcity in training large deep neural networks (DNNs), particularly large language models (LLMs), we present FusionLLM, a decentralized training system designed and implemented for training DNNs using geo-distributed GPUs across different computing clusters or individual devices. Decentralized training faces significant challenges regarding system design and efficiency, including: 1) the need for remote automatic differentiation (RAD), 2) support for flexible model definitions and heterogeneous software, 3) heterogeneous hardware leading to low resource utilization or the straggler problem, and 4) slow network communication. To address these challenges, in the system design, we represent the model as a directed acyclic graph of operators (OP-DAG). Each node in the DAG represents the operator in the DNNs, while the edge represents the data dependency between operators. Based on this design, 1) users are allowed to customize any DNN without caring low-level operator implementation; 2) we enable the task scheduling with the more fine-grained sub-tasks, offering more optimization space; 3) a DAG runtime executor can implement RAD withour requiring the consistent low-level ML framework versions. To enhance system efficiency, we implement a workload estimator and design an OP-Fence scheduler to cluster devices with similar bandwidths together and partition the DAG to increase throughput. Additionally, we propose an AdaTopK compressor to adaptively compress intermediate activations and gradients at the slowest communication links. To evaluate the convergence and efficiency of our system and algorithms, we train ResNet-101 and GPT-2 on three real-world testbeds using 48 GPUs connected with 8 Mbps~10 Gbps networks. Experimental results demonstrate that our system and method can achieve 1.45 - 9.39x speedup compared to baseline methods while ensuring convergence.
FusionAI: Decentralized Training and Deploying LLMs with Massive Consumer-Level GPUs
Sep 03, 2023



The rapid growth of memory and computation requirements of large language models (LLMs) has outpaced the development of hardware, hindering people who lack large-scale high-end GPUs from training or deploying LLMs. However, consumer-level GPUs, which constitute a larger market share, are typically overlooked in LLM due to their weaker computing performance, smaller storage capacity, and lower communication bandwidth. Additionally, users may have privacy concerns when interacting with remote LLMs. In this paper, we envision a decentralized system unlocking the potential vast untapped consumer-level GPUs in pre-training, inference and fine-tuning of LLMs with privacy protection. However, this system faces critical challenges, including limited CPU and GPU memory, low network bandwidth, the variability of peer and device heterogeneity. To address these challenges, our system design incorporates: 1) a broker with backup pool to implement dynamic join and quit of computing providers; 2) task scheduling with hardware performance to improve system efficiency; 3) abstracting ML procedures into directed acyclic graphs (DAGs) to achieve model and task universality; 4) abstracting intermediate represention and execution planes to ensure compatibility of various devices and deep learning (DL) frameworks. Our performance analysis demonstrates that 50 RTX 3080 GPUs can achieve throughputs comparable to those of 4 H100 GPUs, which are significantly more expensive.
Federated Domain Generalization: A Survey
Jun 02, 2023



Machine learning typically relies on the assumption that training and testing distributions are identical and that data is centrally stored for training and testing. However, in real-world scenarios, distributions may differ significantly and data is often distributed across different devices, organizations, or edge nodes. Consequently, it is imperative to develop models that can effectively generalize to unseen distributions where data is distributed across different domains. In response to this challenge, there has been a surge of interest in federated domain generalization (FDG) in recent years. FDG combines the strengths of federated learning (FL) and domain generalization (DG) techniques to enable multiple source domains to collaboratively learn a model capable of directly generalizing to unseen domains while preserving data privacy. However, generalizing the federated model under domain shifts is a technically challenging problem that has received scant attention in the research area so far. This paper presents the first survey of recent advances in this area. Initially, we discuss the development process from traditional machine learning to domain adaptation and domain generalization, leading to FDG as well as provide the corresponding formal definition. Then, we categorize recent methodologies into four classes: federated domain alignment, data manipulation, learning strategies, and aggregation optimization, and present suitable algorithms in detail for each category. Next, we introduce commonly used datasets, applications, evaluations, and benchmarks. Finally, we conclude this survey by providing some potential research topics for the future.
CD$^2$: Fine-grained 3D Mesh Reconstruction with Twice Chamfer Distance
Jun 01, 2022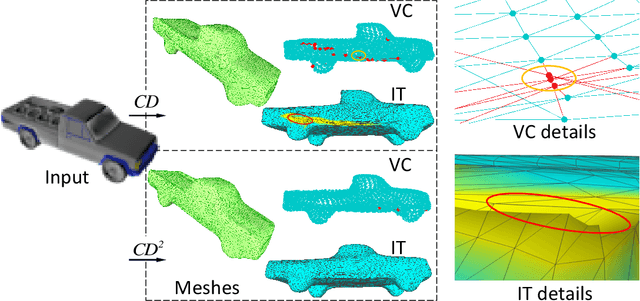



Monocular 3D reconstruction is to reconstruct the shape of object and its other detailed information from a single RGB image. In 3D reconstruction, polygon mesh is the most prevalent expression form obtained from deep learning models, with detailed surface information and low computational cost. However, some state-of-the-art works fail to generate well-structured meshes, these meshes have two severe problems which we call Vertices Clustering and Illegal Twist. By delving into the mesh deformation procedure, we pinpoint the inadequate usage of Chamfer Distance(CD) metric in deep learning model. In this paper, we initially demonstrate the problems resulting from CD with visual examples and quantitative analyses. To solve these problems, we propose a fine-grained reconstruction method CD$^2$ with Chamfer distance adopted twice to perform a plausible and adaptive deformation. Extensive experiments on two 3D datasets and the comparison of our newly proposed mesh quality metrics demonstrate that our CD$^2$ outperforms others by generating better-structured meshes.
A Comprehensive Survey of Incentive Mechanism for Federated Learning
Jun 27, 2021

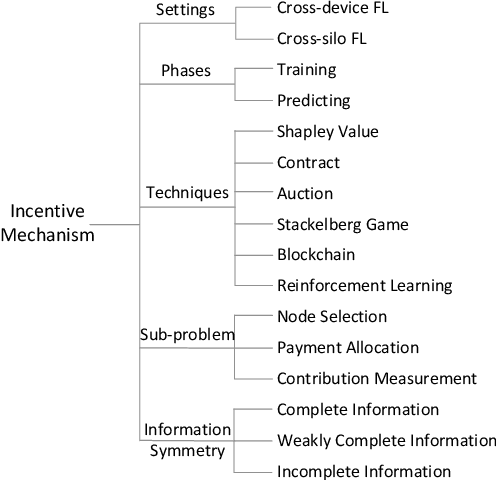

Federated learning utilizes various resources provided by participants to collaboratively train a global model, which potentially address the data privacy issue of machine learning. In such promising paradigm, the performance will be deteriorated without sufficient training data and other resources in the learning process. Thus, it is quite crucial to inspire more participants to contribute their valuable resources with some payments for federated learning. In this paper, we present a comprehensive survey of incentive schemes for federate learning. Specifically, we identify the incentive problem in federated learning and then provide a taxonomy for various schemes. Subsequently, we summarize the existing incentive mechanisms in terms of the main techniques, such as Stackelberg game, auction, contract theory, Shapley value, reinforcement learning, blockchain. By reviewing and comparing some impressive results, we figure out three directions for the future study.
FMore: An Incentive Scheme of Multi-dimensional Auction for Federated Learning in MEC
Feb 22, 2020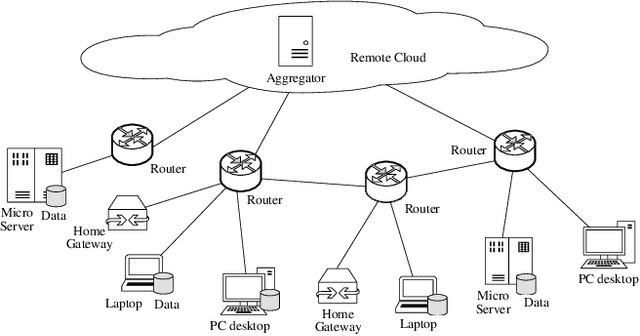
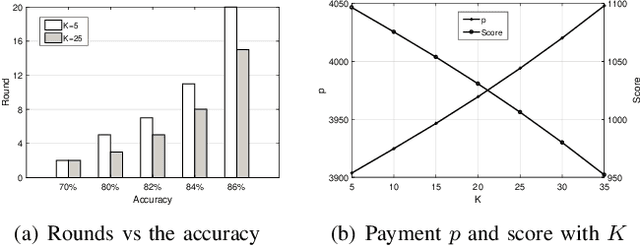
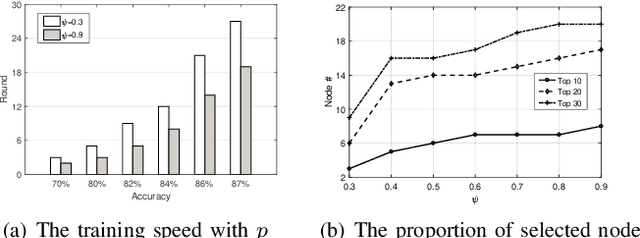

Promising federated learning coupled with Mobile Edge Computing (MEC) is considered as one of the most promising solutions to the AI-driven service provision. Plenty of studies focus on federated learning from the performance and security aspects, but they neglect the incentive mechanism. In MEC, edge nodes would not like to voluntarily participate in learning, and they differ in the provision of multi-dimensional resources, both of which might deteriorate the performance of federated learning. Also, lightweight schemes appeal to edge nodes in MEC. These features require the incentive mechanism to be well designed for MEC. In this paper, we present an incentive mechanism FMore with multi-dimensional procurement auction of K winners. Our proposal FMore not only is lightweight and incentive compatible, but also encourages more high-quality edge nodes with low cost to participate in learning and eventually improve the performance of federated learning. We also present theoretical results of Nash equilibrium strategy to edge nodes and employ the expected utility theory to provide guidance to the aggregator. Both extensive simulations and real-world experiments demonstrate that the proposed scheme can effectively reduce the training rounds and drastically improve the model accuracy for challenging AI tasks.