 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Orchestration for Hierarchical Federated Learning Under a Communication Cost Budget
Dec 04, 2024Deploying a Hierarchical Federated Learning (HFL) pipeline across the computing continuum (CC) requires careful organization of participants into a hierarchical structure with intermediate aggregation nodes between FL clients and the global FL server. This is challenging to achieve due to (i) cost constraints, (ii) varying data distributions, and (iii) the volatile operating environment of the CC. In response to these challenges, we present a framework for the adaptive orchestration of HFL pipelines, designed to be reactive to client churn and infrastructure-level events, while balancing communication cost and ML model accuracy. Our mechanisms identify and react to events that cause HFL reconfiguration actions at runtime, building on multi-level monitoring information (model accuracy, resource availability, resource cost). Moreover, our framework introduces a generic methodology for estimating reconfiguration costs to continuously re-evaluate the quality of adaptation actions, while being extensible to optimize for various HFL performance criteria. By extending the Kubernetes ecosystem, our framework demonstrates the ability to react promptly and effectively to changes in the operating environment, making the best of the available communication cost budget and effectively balancing costs and ML performance at runtime.
Distributed AI in Zero-touch Provisioning for Edge Networks: Challenges and Research Directions
Nov 29, 2023Zero-touch network is anticipated to inaugurate the generation of intelligent and highly flexible resource provisioning strategies where multiple service providers collaboratively offer computation and storage resources. This transformation presents substantial challenges to network administration and service providers regarding sustainability and scalability. This article combines Distributed Artificial Intelligence (DAI) with Zero-touch Provisioning (ZTP) for edge networks. This combination helps to manage network devices seamlessly and intelligently by minimizing human intervention. In addition, several advantages are also highlighted that come with incorporating Distributed AI into ZTP in the context of edge networks. Further, we draw potential research directions to foster novel studies in this field and overcome the current limitations.
CommunityAI: Towards Community-based Federated Learning
Nov 29, 2023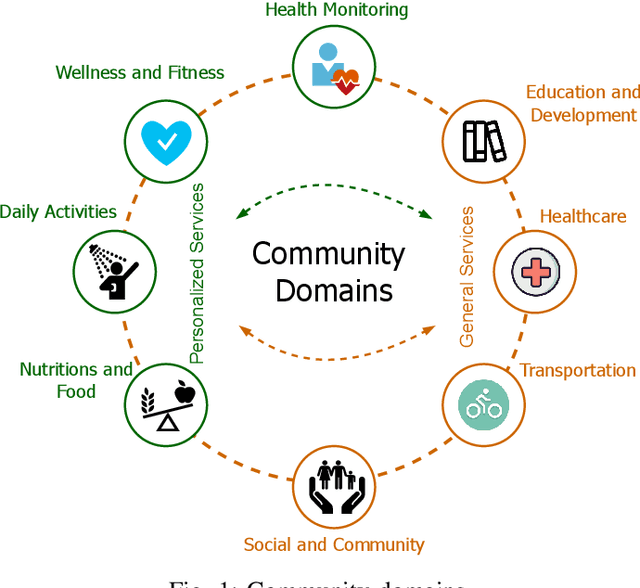

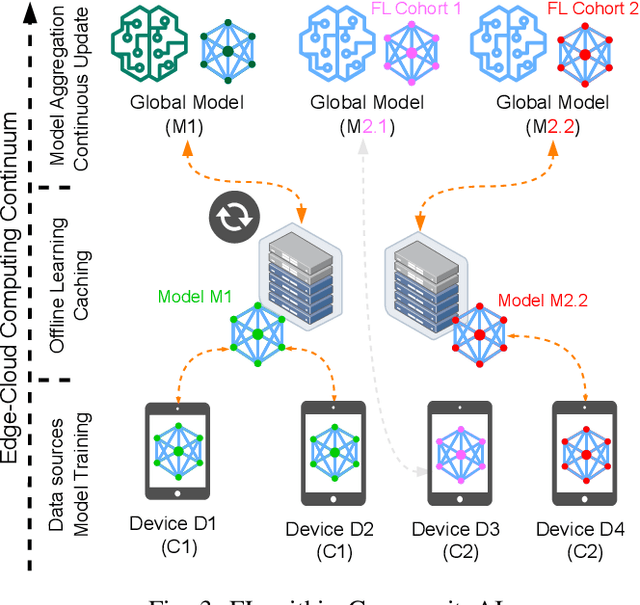
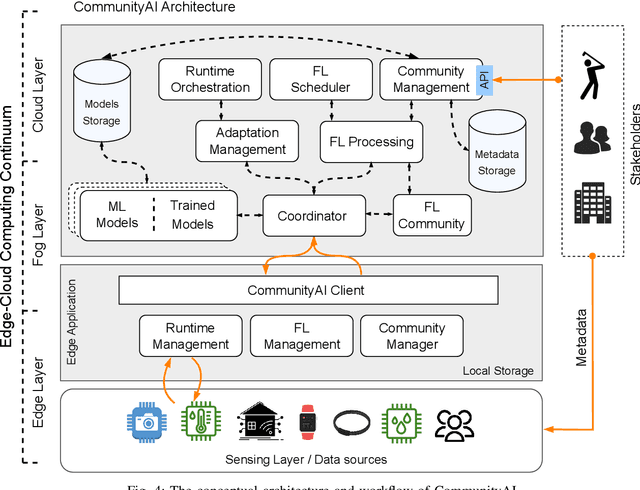
Federated Learning (FL) has emerged as a promising paradigm to train machine learning models collaboratively while preserving data privacy. However, its widespread adoption faces several challenges, including scalability, heterogeneous data and devices, resource constraints, and security concerns. Despite its promise, FL has not been specifically adapted for community domains, primarily due to the wide-ranging differences in data types and context, devices and operational conditions, environmental factors, and stakeholders. In response to these challenges, we present a novel framework for Community-based Federated Learning called CommunityAI. CommunityAI enables participants to be organized into communities based on their shared interests, expertise, or data characteristics. Community participants collectively contribute to training and refining learning models while maintaining data and participant privacy within their respective groups. Within this paper, we discuss the conceptual architecture, system requirements, processes, and future challenges that must be solved. Finally, our goal within this paper is to present our vision regarding enabling a collaborative learning process within various communities.
Learning-driven Zero Trust in Distributed Computing Continuum Systems
Nov 29, 2023



Converging Zero Trust (ZT) with learning techniques can solve various operational and security challenges in Distributed Computing Continuum Systems (DCCS). Implementing centralized ZT architecture is seen as unsuitable for the computing continuum (e.g., computing entities with limited connectivity and visibility, etc.). At the same time, implementing decentralized ZT in the computing continuum requires understanding infrastructure limitations and novel approaches to enhance resource access management decisions. To overcome such challenges, we present a novel learning-driven ZT conceptual architecture designed for DCCS. We aim to enhance ZT architecture service quality by incorporating lightweight learning strategies such as Representation Learning (ReL) and distributing ZT components across the computing continuum. The ReL helps to improve the decision-making process by predicting threats or untrusted requests. Through an illustrative example, we show how the learning process detects and blocks the requests, enhances resource access control, and reduces network and computation overheads. Lastly, we discuss the conceptual architecture, processes, and provide a research agenda.
Federated Domain Generalization: A Survey
Jun 02, 2023



Machine learning typically relies on the assumption that training and testing distributions are identical and that data is centrally stored for training and testing. However, in real-world scenarios, distributions may differ significantly and data is often distributed across different devices, organizations, or edge nodes. Consequently, it is imperative to develop models that can effectively generalize to unseen distributions where data is distributed across different domains. In response to this challenge, there has been a surge of interest in federated domain generalization (FDG) in recent years. FDG combines the strengths of federated learning (FL) and domain generalization (DG) techniques to enable multiple source domains to collaboratively learn a model capable of directly generalizing to unseen domains while preserving data privacy. However, generalizing the federated model under domain shifts is a technically challenging problem that has received scant attention in the research area so far. This paper presents the first survey of recent advances in this area. Initially, we discuss the development process from traditional machine learning to domain adaptation and domain generalization, leading to FDG as well as provide the corresponding formal definition. Then, we categorize recent methodologies into four classes: federated domain alignment, data manipulation, learning strategies, and aggregation optimization, and present suitable algorithms in detail for each category. Next, we introduce commonly used datasets, applications, evaluations, and benchmarks. Finally, we conclude this survey by providing some potential research topics for the future.