 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Global Land Surface Temperature Retrieval via a Coupled Mechanism-Machine Learning Framework
Sep 05, 2025Land surface temperature (LST) is vital for land-atmosphere interactions and climate processes. Accurate LST retrieval remains challenging under heterogeneous land cover and extreme atmospheric conditions. Traditional split window (SW) algorithms show biases in humid environments; purely machine learning (ML) methods lack interpretability and generalize poorly with limited data. We propose a coupled mechanism model-ML (MM-ML) framework integrating physical constraints with data-driven learning for robust LST retrieval. Our approach fuses radiative transfer modeling with data components, uses MODTRAN simulations with global atmospheric profiles, and employs physics-constrained optimization. Validation against 4,450 observations from 29 global sites shows MM-ML achieves MAE=1.84K, RMSE=2.55K, and R-squared=0.966, outperforming conventional methods. Under extreme conditions, MM-ML reduces errors by over 50%. Sensitivity analysis indicates LST estimates are most sensitive to sensor radiance, then water vapor, and less to emissivity, with MM-ML showing superior stability. These results demonstrate the effectiveness of our coupled modeling strategy for retrieving geophysical parameters. The MM-ML framework combines physical interpretability with nonlinear modeling capacity, enabling reliable LST retrieval in complex environments and supporting climate monitoring and ecosystem studies.
PCF-Grasp: Converting Point Completion to Geometry Feature to Enhance 6-DoF Grasp
Apr 22, 2025The 6-Degree of Freedom (DoF) grasp method based on point clouds has shown significant potential in enabling robots to grasp target objects. However, most existing methods are based on the point clouds (2.5D points) generated from single-view depth images. These point clouds only have one surface side of the object providing incomplete geometry information, which mislead the grasping algorithm to judge the shape of the target object, resulting in low grasping accuracy. Humans can accurately grasp objects from a single view by leveraging their geometry experience to estimate object shapes. Inspired by humans, we propose a novel 6-DoF grasping framework that converts the point completion results as object shape features to train the 6-DoF grasp network. Here, point completion can generate approximate complete points from the 2.5D points similar to the human geometry experience, and converting it as shape features is the way to utilize it to improve grasp efficiency. Furthermore, due to the gap between the network generation and actual execution, we integrate a score filter into our framework to select more executable grasp proposals for the real robot. This enables our method to maintain a high grasp quality in any camera viewpoint. Extensive experiments demonstrate that utilizing complete point features enables the generation of significantly more accurate grasp proposals and the inclusion of a score filter greatly enhances the credibility of real-world robot grasping. Our method achieves a 17.8\% success rate higher than the state-of-the-art method in real-world experiments.
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Dec 23, 2024
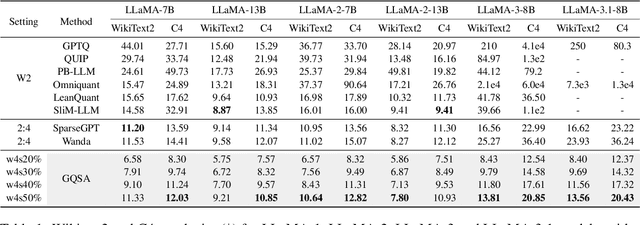
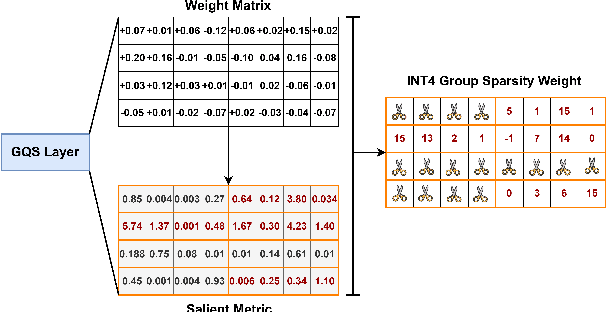
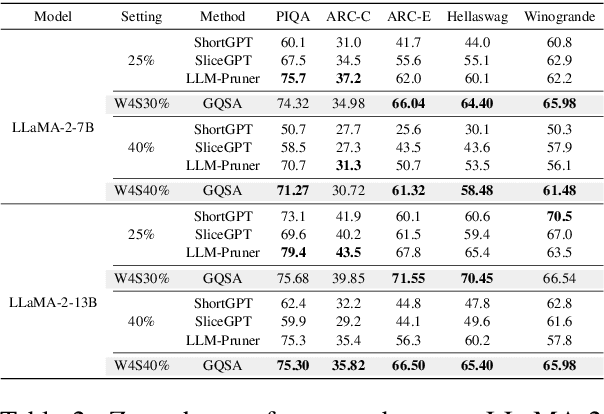
With the rapid growth in the scale and complexity of large language models (LLMs), the costs of training and inference have risen substantially. Model compression has emerged as a mainstream solution to reduce memory usage and computational overhead. This paper presents Group Quantization and Sparse Acceleration (\textbf{GQSA}), a novel compression technique tailored for LLMs. Traditional methods typically focus exclusively on either quantization or sparsification, but relying on a single strategy often results in significant performance loss at high compression rates. In contrast, GQSA integrates quantization and sparsification in a tightly coupled manner, leveraging GPU-friendly structured group sparsity and quantization for efficient acceleration. The proposed method consists of three key steps. First, GQSA applies group structured pruning to adhere to GPU-friendly sparse pattern constraints. Second, a two-stage sparsity-aware training process is employed to maximize performance retention after compression. Finally, the framework adopts the Block Sparse Row (BSR) format to enable practical deployment and efficient execution. Experimental results on the LLaMA model family show that GQSA achieves an excellent balance between model speed and accuracy. Furthermore, on the latest LLaMA-3 and LLaMA-3.1 models, GQSA outperforms existing LLM compression techniques significantly.
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Aug 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$\downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$\times$ acceleration improvement and 2.7$\times$ memory compression gain.
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Jul 01, 2024The demand for deploying large language models(LLMs) on mobile devices continues to increase, driven by escalating data security concerns and cloud costs. However, network bandwidth and memory limitations pose challenges for deploying billion-level models on mobile devices. In this study, we investigate the outputs of different layers across various scales of LLMs and found that the outputs of most layers exhibit significant similarity. Moreover, this similarity becomes more pronounced as the model size increases, indicating substantial redundancy in the depth direction of the LLMs. Based on this observation, we propose an efficient model volume compression strategy, termed FoldGPT, which combines block removal and block parameter sharing.This strategy consists of three parts: (1) Based on the learnable gating parameters, we determine the block importance ranking while modeling the coupling effect between blocks. Then we delete some redundant layers based on the given removal rate. (2) For the retained blocks, we apply a specially designed group parameter sharing strategy, where blocks within the same group share identical weights, significantly compressing the number of parameters and slightly reducing latency overhead. (3) After sharing these Blocks, we "cure" the mismatch caused by sparsity with a minor amount of fine-tuning and introduce a tail-layer distillation strategy to improve the performance. Experiments demonstrate that FoldGPT outperforms previous state-of-the-art(SOTA) methods in efficient model compression, demonstrating the feasibility of achieving model lightweighting through straightforward block removal and parameter sharing.
A physics-constrained machine learning method for mapping gapless land surface temperature
Jul 03, 2023More accurate, spatio-temporally, and physically consistent LST estimation has been a main interest in Earth system research. Developing physics-driven mechanism models and data-driven machine learning (ML) models are two major paradigms for gapless LST estimation, which have their respective advantages and disadvantages. In this paper, a physics-constrained ML model, which combines the strengths in the mechanism model and ML model, is proposed to generate gapless LST with physical meanings and high accuracy. The hybrid model employs ML as the primary architecture, under which the input variable physical constraints are incorporated to enhance the interpretability and extrapolation ability of the model. Specifically, the light gradient-boosting machine (LGBM) model, which uses only remote sensing data as input, serves as the pure ML model. Physical constraints (PCs) are coupled by further incorporating key Community Land Model (CLM) forcing data (cause) and CLM simulation data (effect) as inputs into the LGBM model. This integration forms the PC-LGBM model, which incorporates surface energy balance (SEB) constraints underlying the data in CLM-LST modeling within a biophysical framework. Compared with a pure physical method and pure ML methods, the PC-LGBM model improves the prediction accuracy and physical interpretability of LST. It also demonstrates a good extrapolation ability for the responses to extreme weather cases, suggesting that the PC-LGBM model enables not only empirical learning from data but also rationally derived from theory. The proposed method represents an innovative way to map accurate and physically interpretable gapless LST, and could provide insights to accelerate knowledge discovery in land surface processes and data mining in geographical parameter estimation.
Dual Swin-Transformer based Mutual Interactive Network for RGB-D Salient Object Detection
Jun 07, 2022
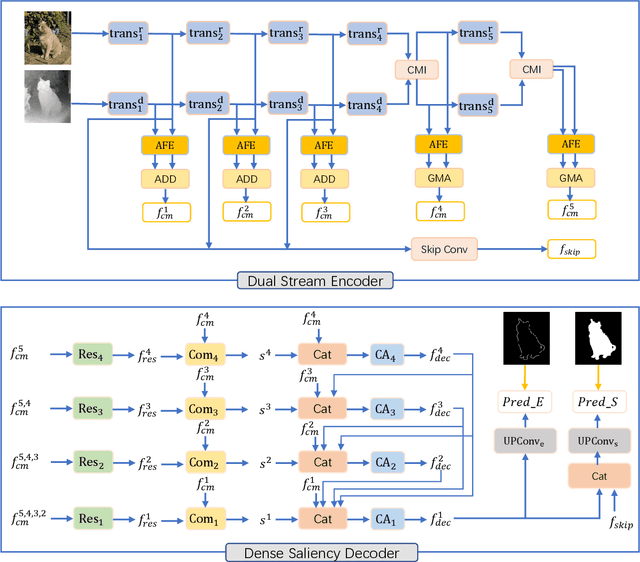


Salient Object Detection is the task of predicting the human attended region in a given scene. Fusing depth information has been proven effective in this task. The main challenge of this problem is how to aggregate the complementary information from RGB modality and depth modality. However, conventional deep models heavily rely on CNN feature extractors, and the long-range contextual dependencies are usually ignored. In this work, we propose Dual Swin-Transformer based Mutual Interactive Network. We adopt Swin-Transformer as the feature extractor for both RGB and depth modality to model the long-range dependencies in visual inputs. Before fusing the two branches of features into one, attention-based modules are applied to enhance features from each modality. We design a self-attention-based cross-modality interaction module and a gated modality attention module to leverage the complementary information between the two modalities. For the saliency decoding, we create different stages enhanced with dense connections and keep a decoding memory while the multi-level encoding features are considered simultaneously. Considering the inaccurate depth map issue, we collect the RGB features of early stages into a skip convolution module to give more guidance from RGB modality to the final saliency prediction. In addition, we add edge supervision to regularize the feature learning process. Comprehensive experiments on five standard RGB-D SOD benchmark datasets over four evaluation metrics demonstrate the superiority of the proposed DTMINet method.
Learning Transformer Features for Image Quality Assessment
Dec 01, 2021
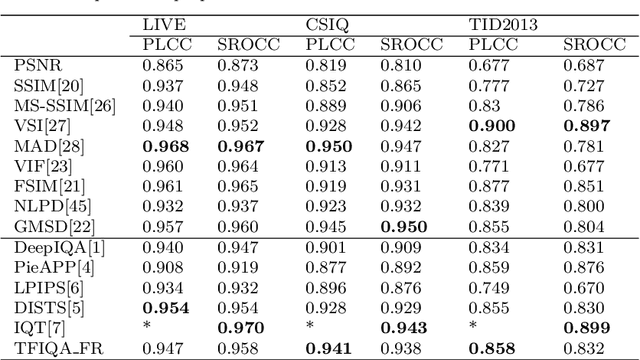

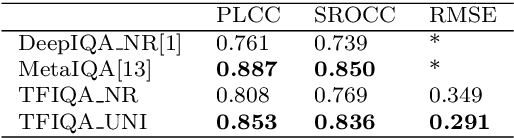
Objective image quality evaluation is a challenging task, which aims to measure the quality of a given image automatically. According to the availability of the reference images, there are Full-Reference and No-Reference IQA tasks, respectively. Most deep learning approaches use regression from deep features extracted by Convolutional Neural Networks. For the FR task, another option is conducting a statistical comparison on deep features. For all these methods, non-local information is usually neglected. In addition, the relationship between FR and NR tasks is less explored. Motivated by the recent success of transformers in modeling contextual information, we propose a unified IQA framework that utilizes CNN backbone and transformer encoder to extract features. The proposed framework is compatible with both FR and NR modes and allows for a joint training scheme. Evaluation experiments on three standard IQA datasets, i.e., LIVE, CSIQ and TID2013, and KONIQ-10K, show that our proposed model can achieve state-of-the-art FR performance. In addition, comparable NR performance is achieved in extensive experiments, and the results show that the NR performance can be leveraged by the joint training scheme.
Learning compliant grasping and manipulation by teleoperation with adaptive force control
Jul 21, 2021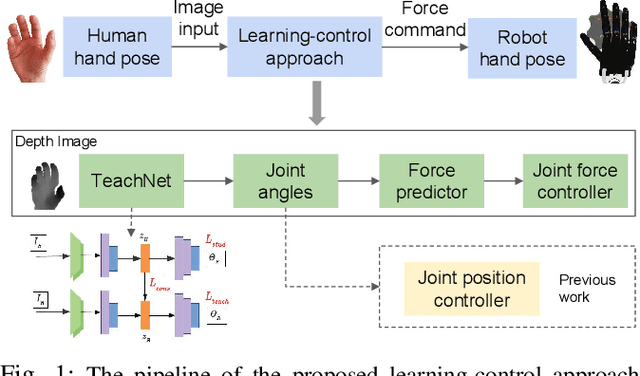
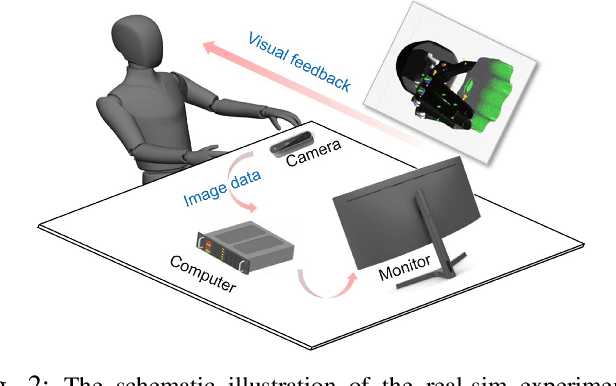
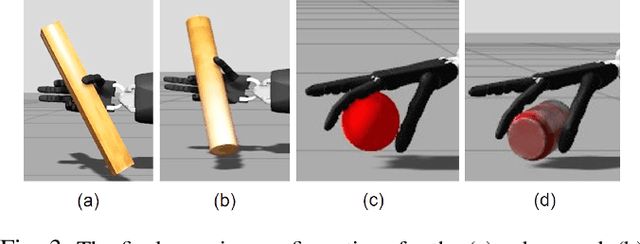
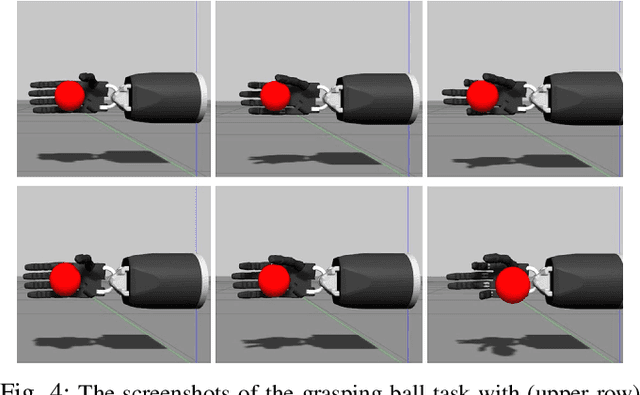
In this work, we focus on improving the robot's dexterous capability by exploiting visual sensing and adaptive force control. TeachNet, a vision-based teleoperation learning framework, is exploited to map human hand postures to a multi-fingered robot hand. We augment TeachNet, which is originally based on an imprecise kinematic mapping and position-only servoing, with a biomimetic learning-based compliance control algorithm for dexterous manipulation tasks. This compliance controller takes the mapped robotic joint angles from TeachNet as the desired goal, computes the desired joint torques. It is derived from a computational model of the biomimetic control strategy in human motor learning, which allows adapting the control variables (impedance and feedforward force) online during the execution of the reference joint angle trajectories. The simultaneous adaptation of the impedance and feedforward profiles enables the robot to interact with the environment in a compliant manner. Our approach has been verified in multiple tasks in physics simulation, i.e., grasping, opening-a-door, turning-a-cap, and touching-a-mouse, and has shown more reliable performances than the existing position control and the fixed-gain-based force control approaches.
Contrastive Semantic Similarity Learning for Image Captioning Evaluation with Intrinsic Auto-encoder
Jun 29, 2021



Automatically evaluating the quality of image captions can be very challenging since human language is quite flexible that there can be various expressions for the same meaning. Most of the current captioning metrics rely on token level matching between candidate caption and the ground truth label sentences. It usually neglects the sentence-level information. Motivated by the auto-encoder mechanism and contrastive representation learning advances, we propose a learning-based metric for image captioning, which we call Intrinsic Image Captioning Evaluation($I^2CE$). We develop three progressive model structures to learn the sentence level representations--single branch model, dual branches model, and triple branches model. Our empirical tests show that $I^2CE$ trained with dual branches structure achieves better consistency with human judgments to contemporary image captioning evaluation metrics. Furthermore, We select several state-of-the-art image captioning models and test their performances on the MS COCO dataset concerning both contemporary metrics and the proposed $I^2CE$. Experiment results show that our proposed method can align well with the scores generated from other contemporary metrics. On this concern, the proposed metric could serve as a novel indicator of the intrinsic information between captions, which may be complementary to the existing ones.