 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Swin-Transformer based Mutual Interactive Network for RGB-D Salient Object Detection
Paper and Code
Jun 07, 2022
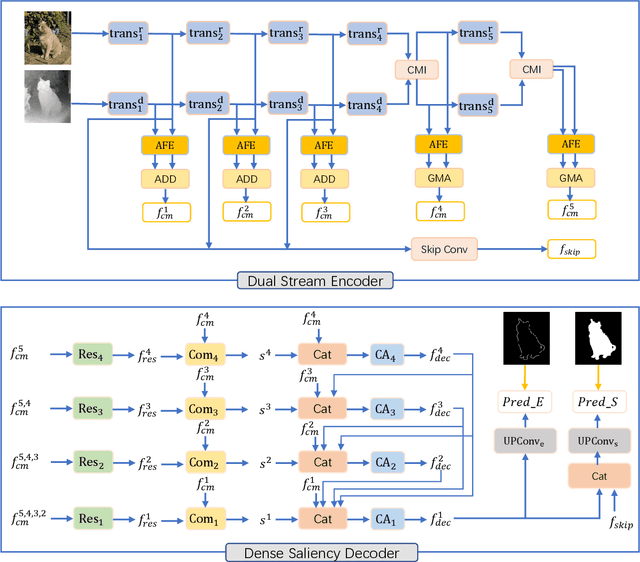


Salient Object Detection is the task of predicting the human attended region in a given scene. Fusing depth information has been proven effective in this task. The main challenge of this problem is how to aggregate the complementary information from RGB modality and depth modality. However, conventional deep models heavily rely on CNN feature extractors, and the long-range contextual dependencies are usually ignored. In this work, we propose Dual Swin-Transformer based Mutual Interactive Network. We adopt Swin-Transformer as the feature extractor for both RGB and depth modality to model the long-range dependencies in visual inputs. Before fusing the two branches of features into one, attention-based modules are applied to enhance features from each modality. We design a self-attention-based cross-modality interaction module and a gated modality attention module to leverage the complementary information between the two modalities. For the saliency decoding, we create different stages enhanced with dense connections and keep a decoding memory while the multi-level encoding features are considered simultaneously. Considering the inaccurate depth map issue, we collect the RGB features of early stages into a skip convolution module to give more guidance from RGB modality to the final saliency prediction. In addition, we add edge supervision to regularize the feature learning process. Comprehensive experiments on five standard RGB-D SOD benchmark datasets over four evaluation metrics demonstrate the superiority of the proposed DTMINet method.