 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fidelity: Semantic Similarity Assessment in Low-Level Image Processing
Apr 28, 2026Low-level image processing has long been evaluated mainly from the perspective of visual fidelity. However, with the rise of deep learning and generative models, processed images may preserve perceptual quality while altering semantic content, making conventional Image Quality Assessment (IQA) insufficient for semantic-level assessment. In this paper, we formalize \textit{Semantic Similarity} as a new evaluation task for low-level image processing, aimed at measuring whether semantic content is preserved after processing. We further present a structured formulation of image semantics based on semantic entities and their relations, and discuss the desired properties and constraints of a valid semantic similarity index. Based on this formulation, we propose Triplet-based Semantic Similarity Score (T3S), which models image semantics through foreground entities, background entities, and relations. T3S combines semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling. Experiments on COCO and SPA-Data show that T3S consistently outperforms existing fidelity-oriented metrics and representative semantic-level baselines, while better reflecting progressive semantic changes under diverse degradations. These results highlight the importance of semantic assessment in modern low-level vision.
MSDS: Deep Structural Similarity with Multiscale Representation
Apr 21, 2026Deep-feature-based perceptual similarity models have demonstrated strong alignment with human visual perception in Image Quality Assessment (IQA). However, most existing approaches operate at a single spatial scale, implicitly assuming that structural similarity at a fixed resolution is sufficient. The role of spatial scale in deep-feature similarity modeling thus remains insufficiently understood. In this letter, we isolate spatial scale as an independent factor using a minimal multiscale extension of DeepSSIM, referred to as Deep Structural Similarity with Multiscale Representation (MSDS). The proposed framework decouples deep feature representation from cross-scale integration by computing DeepSSIM independently across pyramid levels and fusing the resulting scores with a lightweight set of learnable global weights. Experiments on multiple benchmark datasets demonstrate consistent and statistically significant improvements over the single-scale baseline, while introducing negligible additional complexity. The results empirically confirm spatial scale as a non-negligible factor in deep perceptual similarity, isolated here via a minimal testbed.
When Sensing Varies with Contexts: Context-as-Transform for Tactile Few-Shot Class-Incremental Learning
Mar 26, 2026Few-Shot Class-Incremental Learning (FSCIL) can be particularly susceptible to acquisition contexts with only a few labeled samples. A typical scenario is tactile sensing, where the acquisition context ({\it e.g.}, diverse devices, contact state, and interaction settings) degrades performance due to a lack of standardization. In this paper, we propose Context-as-Transform FSCIL (CaT-FSCIL) to tackle the above problem. We decompose the acquisition context into a structured low-dimensional component and a high-dimensional residual component. The former can be easily affected by tactile interaction features, which are modeled as an approximately invertible Context-as-Transform family and handled via inverse-transform canonicalization optimized with a pseudo-context consistency loss. The latter mainly arises from platform and device differences, which can be mitigated with an Uncertainty-Conditioned Prototype Calibration (UCPC) that calibrates biased prototypes and decision boundaries based on context uncertainty. Comprehensive experiments on the standard benchmarks HapTex and LMT108 have demonstrated the superiority of the proposed CaT-FSCIL.
The Language of Touch: Translating Vibrations into Text with Dual-Branch Learning
Mar 26, 2026The standardization of vibrotactile data by IEEE P1918.1 workgroup has greatly advanced its applications in virtual reality, human-computer interaction and embodied artificial intelligence. Despite these efforts, the semantic interpretation and understanding of vibrotactile signals remain an unresolved challenge. In this paper, we make the first attempt to address vibrotactile captioning, {\it i.e.}, generating natural language descriptions from vibrotactile signals. We propose Vibrotactile Periodic-Aperiodic Captioning (ViPAC), a method designed to handle the intrinsic properties of vibrotactile data, including hybrid periodic-aperiodic structures and the lack of spatial semantics. Specifically, ViPAC employs a dual-branch strategy to disentangle periodic and aperiodic components, combined with a dynamic fusion mechanism that adaptively integrates signal features. It also introduces an orthogonality constraint and weighting regularization to ensure feature complementarity and fusion consistency. Additionally, we construct LMT108-CAP, the first vibrotactile-text paired dataset, using GPT-4o to generate five constrained captions per surface image from the popular LMT-108 dataset. Experiments show that ViPAC significantly outperforms the baseline methods adapted from audio and image captioning, achieving superior lexical fidelity and semantic alignment.
Event-based Visual Deformation Measurement
Feb 16, 2026Visual Deformation Measurement (VDM) aims to recover dense deformation fields by tracking surface motion from camera observations. Traditional image-based methods rely on minimal inter-frame motion to constrain the correspondence search space, which limits their applicability to highly dynamic scenes or necessitates high-speed cameras at the cost of prohibitive storage and computational overhead. We propose an event-frame fusion framework that exploits events for temporally dense motion cues and frames for spatially dense precise estimation. Revisiting the solid elastic modeling prior, we propose an Affine Invariant Simplicial (AIS) framework. It partitions the deformation field into linearized sub-regions with low-parametric representation, effectively mitigating motion ambiguities arising from sparse and noisy events. To speed up parameter searching and reduce error accumulation, a neighborhood-greedy optimization strategy is introduced, enabling well-converged sub-regions to guide their poorly-converged neighbors, effectively suppress local error accumulation in long-term dense tracking. To evaluate the proposed method, a benchmark dataset with temporally aligned event streams and frames is established, encompassing over 120 sequences spanning diverse deformation scenarios. Experimental results show that our method outperforms the state-of-the-art baseline by 1.6% in survival rate. Remarkably, it achieves this using only 18.9% of the data storage and processing resources of high-speed video methods.
OmniVaT: Single Domain Generalization for Multimodal Visual-Tactile Learning
Jan 01, 2026Visual-tactile learning (VTL) enables embodied agents to perceive the physical world by integrating visual (VIS) and tactile (TAC) sensors. However, VTL still suffers from modality discrepancies between VIS and TAC images, as well as domain gaps caused by non-standardized tactile sensors and inconsistent data collection procedures. We formulate these challenges as a new task, termed single domain generalization for multimodal VTL (SDG-VTL). In this paper, we propose an OmniVaT framework that, for the first time, successfully addresses this task. On the one hand, OmniVaT integrates a multimodal fractional Fourier adapter (MFFA) to map VIS and TAC embeddings into a unified embedding-frequency space, thereby effectively mitigating the modality gap without multi-domain training data or careful cross-modal fusion strategies. On the other hand, it also incorporates a discrete tree generation (DTG) module that obtains diverse and reliable multimodal fractional representations through a hierarchical tree structure, thereby enhancing its adaptivity to fluctuating domain shifts in unseen domains. Extensive experiments demonstrate the superior cross-domain generalization performance of OmniVaT on the SDG-VTL task.
Structural Similarity in Deep Features: Image Quality Assessment Robust to Geometrically Disparate Reference
Dec 27, 2024
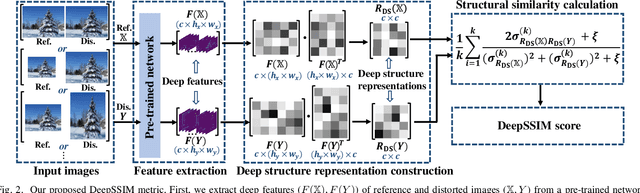


Image Quality Assessment (IQA) with references plays an important role in optimizing and evaluating computer vision tasks. Traditional methods assume that all pixels of the reference and test images are fully aligned. Such Aligned-Reference IQA (AR-IQA) approaches fail to address many real-world problems with various geometric deformations between the two images. Although significant effort has been made to attack Geometrically-Disparate-Reference IQA (GDR-IQA) problem, it has been addressed in a task-dependent fashion, for example, by dedicated designs for image super-resolution and retargeting, or by assuming the geometric distortions to be small that can be countered by translation-robust filters or by explicit image registrations. Here we rethink this problem and propose a unified, non-training-based Deep Structural Similarity (DeepSSIM) approach to address the above problems in a single framework, which assesses structural similarity of deep features in a simple but efficient way and uses an attention calibration strategy to alleviate attention deviation. The proposed method, without application-specific design, achieves state-of-the-art performance on AR-IQA datasets and meanwhile shows strong robustness to various GDR-IQA test cases. Interestingly, our test also shows the effectiveness of DeepSSIM as an optimization tool for training image super-resolution, enhancement and restoration, implying an even wider generalizability. \footnote{Source code will be made public after the review is completed.
SIAVC: Semi-Supervised Framework for Industrial Accident Video Classification
May 23, 2024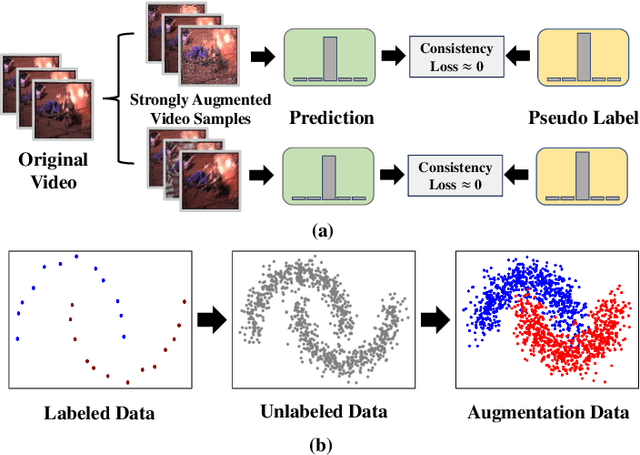
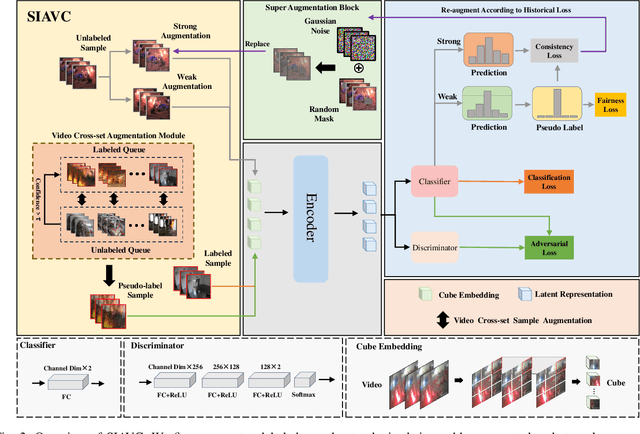
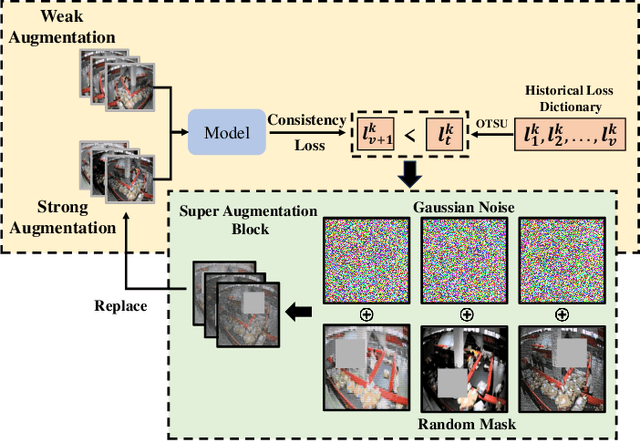
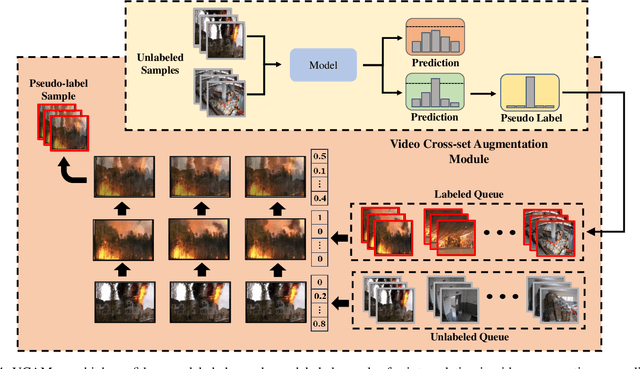
Semi-supervised learning suffers from the imbalance of labeled and unlabeled training data in the video surveillance scenario. In this paper, we propose a new semi-supervised learning method called SIAVC for industrial accident video classification. Specifically, we design a video augmentation module called the Super Augmentation Block (SAB). SAB adds Gaussian noise and randomly masks video frames according to historical loss on the unlabeled data for model optimization. Then, we propose a Video Cross-set Augmentation Module (VCAM) to generate diverse pseudo-label samples from the high-confidence unlabeled samples, which alleviates the mismatch of sampling experience and provides high-quality training data. Additionally, we construct a new industrial accident surveillance video dataset with frame-level annotation, namely ECA9, to evaluate our proposed method. Compared with the state-of-the-art semi-supervised learning based methods, SIAVC demonstrates outstanding video classification performance, achieving 88.76\% and 89.13\% accuracy on ECA9 and Fire Detection datasets, respectively. The source code and the constructed dataset ECA9 will be released in \url{https://github.com/AlchemyEmperor/SIAVC}.
Beyond Night Visibility: Adaptive Multi-Scale Fusion of Infrared and Visible Images
Mar 02, 2024
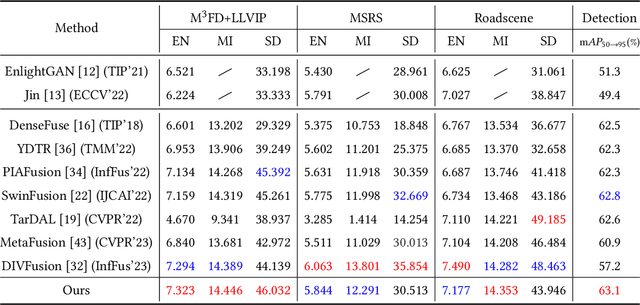
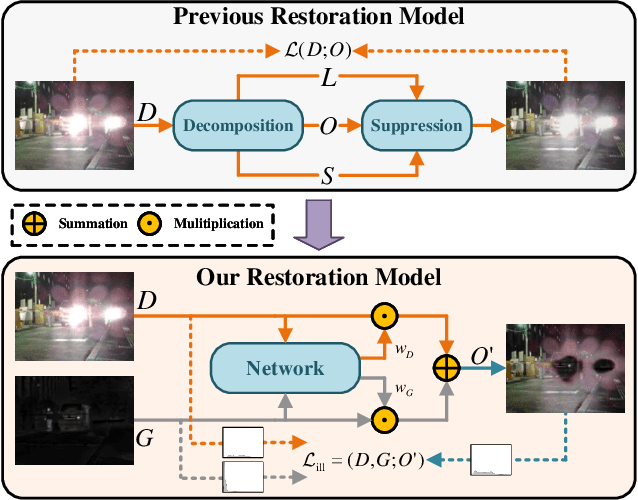
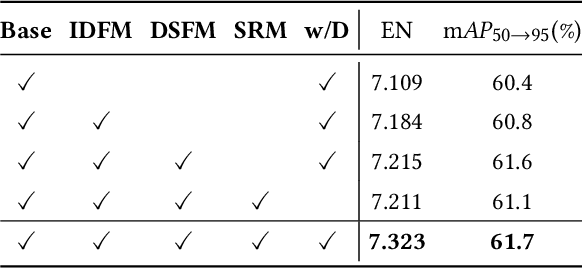
In addition to low light, night images suffer degradation from light effects (e.g., glare, floodlight, etc). However, existing nighttime visibility enhancement methods generally focus on low-light regions, which neglects, or even amplifies the light effects. To address this issue, we propose an Adaptive Multi-scale Fusion network (AMFusion) with infrared and visible images, which designs fusion rules according to different illumination regions. First, we separately fuse spatial and semantic features from infrared and visible images, where the former are used for the adjustment of light distribution and the latter are used for the improvement of detection accuracy. Thereby, we obtain an image free of low light and light effects, which improves the performance of nighttime object detection. Second, we utilize detection features extracted by a pre-trained backbone that guide the fusion of semantic features. Hereby, we design a Detection-guided Semantic Fusion Module (DSFM) to bridge the domain gap between detection and semantic features. Third, we propose a new illumination loss to constrain fusion image with normal light intensity. Experimental results demonstrate the superiority of AMFusion with better visual quality and detection accuracy. The source code will be released after the peer review process.
Non-Intrusive Electric Load Monitoring Approach Based on Current Feature Visualization for Smart Energy Management
Aug 08, 2023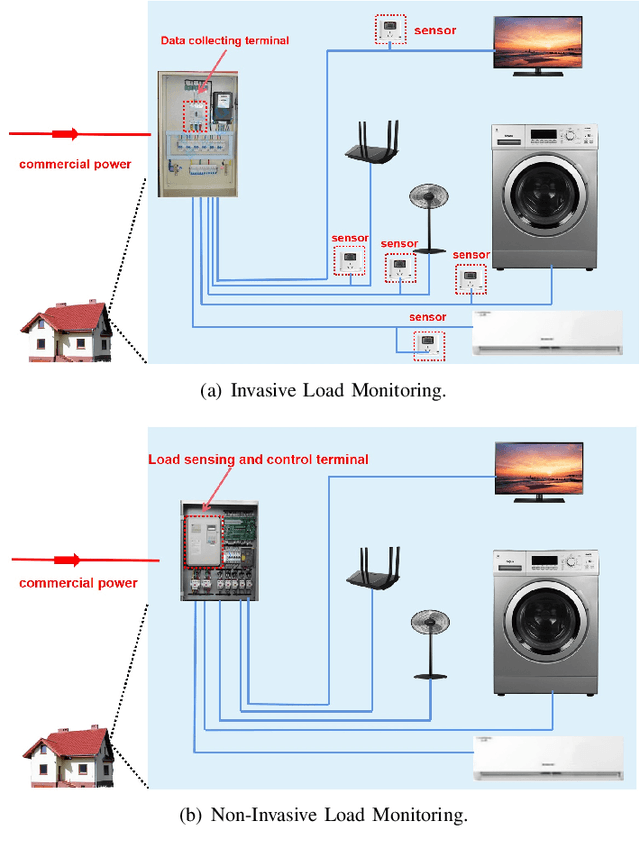
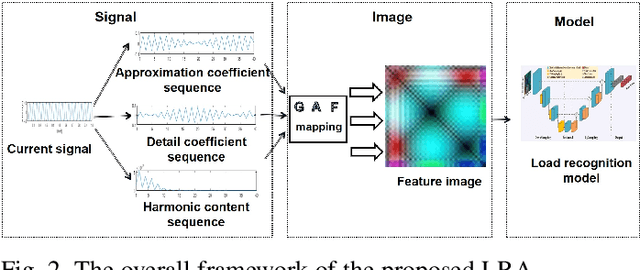
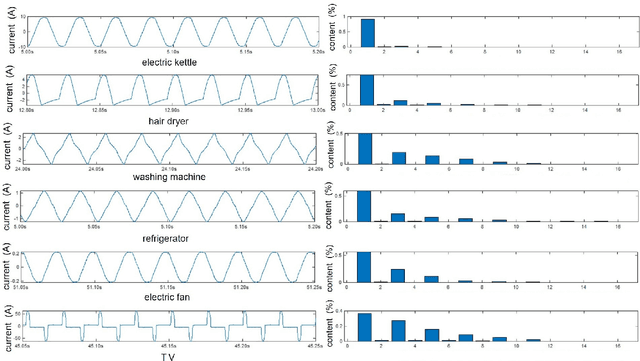
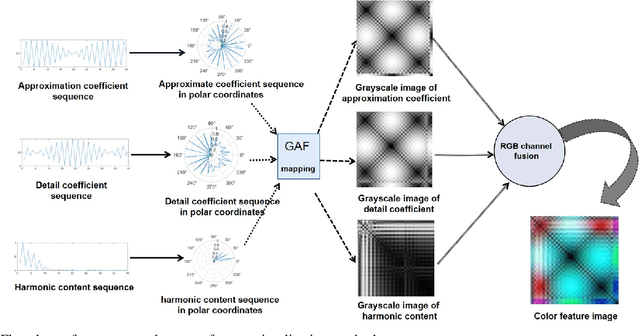
The state-of-the-art smart city has been calling for an economic but efficient energy management over large-scale network, especially for the electric power system. It is a critical issue to monitor, analyze and control electric loads of all users in system. In this paper, we employ the popular computer vision techniques of AI to design a non-invasive load monitoring method for smart electric energy management. First of all, we utilize both signal transforms (including wavelet transform and discrete Fourier transform) and Gramian Angular Field (GAF) methods to map one-dimensional current signals onto two-dimensional color feature images. Second, we propose to recognize all electric loads from color feature images using a U-shape deep neural network with multi-scale feature extraction and attention mechanism. Third, we design our method as a cloud-based, non-invasive monitoring of all users, thereby saving energy cost during electric power system control. Experimental results on both public and our private datasets have demonstrated our method achieves superior performances than its peers, and thus supports efficient energy management over large-scale Internet of Things (IoT).