 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Similarity in Deep Features: Image Quality Assessment Robust to Geometrically Disparate Reference
Dec 27, 2024Image Quality Assessment (IQA) with references plays an important role in optimizing and evaluating computer vision tasks. Traditional methods assume that all pixels of the reference and test images are fully aligned. Such Aligned-Reference IQA (AR-IQA) approaches fail to address many real-world problems with various geometric deformations between the two images. Although significant effort has been made to attack Geometrically-Disparate-Reference IQA (GDR-IQA) problem, it has been addressed in a task-dependent fashion, for example, by dedicated designs for image super-resolution and retargeting, or by assuming the geometric distortions to be small that can be countered by translation-robust filters or by explicit image registrations. Here we rethink this problem and propose a unified, non-training-based Deep Structural Similarity (DeepSSIM) approach to address the above problems in a single framework, which assesses structural similarity of deep features in a simple but efficient way and uses an attention calibration strategy to alleviate attention deviation. The proposed method, without application-specific design, achieves state-of-the-art performance on AR-IQA datasets and meanwhile shows strong robustness to various GDR-IQA test cases. Interestingly, our test also shows the effectiveness of DeepSSIM as an optimization tool for training image super-resolution, enhancement and restoration, implying an even wider generalizability. \footnote{Source code will be made public after the review is completed.
Research on Image Recognition Technology Based on Multimodal Deep Learning
May 06, 2024



This project investigates the human multi-modal behavior identification algorithm utilizing deep neural networks. According to the characteristics of different modal information, different deep neural networks are used to adapt to different modal video information. Through the integration of various deep neural networks, the algorithm successfully identifies behaviors across multiple modalities. In this project, multiple cameras developed by Microsoft Kinect were used to collect corresponding bone point data based on acquiring conventional images. In this way, the motion features in the image can be extracted. Ultimately, the behavioral characteristics discerned through both approaches are synthesized to facilitate the precise identification and categorization of behaviors. The performance of the suggested algorithm was evaluated using the MSR3D data set. The findings from these experiments indicate that the accuracy in recognizing behaviors remains consistently high, suggesting that the algorithm is reliable in various scenarios. Additionally, the tests demonstrate that the algorithm substantially enhances the accuracy of detecting pedestrian behaviors in video footage.
SPQE: Structure-and-Perception-Based Quality Evaluation for Image Super-Resolution
May 07, 2022
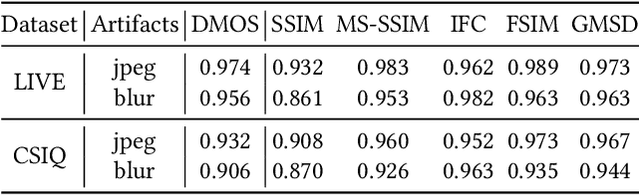

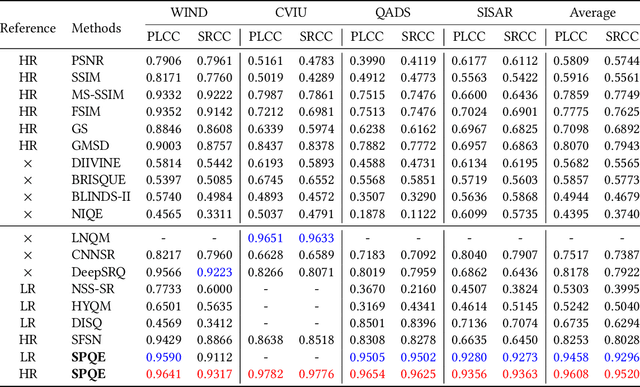
The image Super-Resolution (SR) technique has greatly improved the visual quality of images by enhancing their resolutions. It also calls for an efficient SR Image Quality Assessment (SR-IQA) to evaluate those algorithms or their generated images. In this paper, we focus on the SR-IQA under deep learning and propose a Structure-and-Perception-based Quality Evaluation (SPQE). In emerging deep-learning-based SR, a generated high-quality, visually pleasing image may have different structures from its corresponding low-quality image. In such case, how to balance the quality scores between no-reference perceptual quality and referenced structural similarity is a critical issue. To help ease this problem, we give a theoretical analysis on this tradeoff and further calculate adaptive weights for the two types of quality scores. We also propose two deep-learning-based regressors to model the no-reference and referenced scores. By combining the quality scores and their weights, we propose a unified SPQE metric for SR-IQA. Experimental results demonstrate that the proposed method outperforms the state-of-the-arts in different datasets.