 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawback of Enforcing Equivariance and its Compensation via the Lens of Expressive Power
Dec 10, 2025Equivariant neural networks encode symmetry as an inductive bias and have achieved strong empirical performance in wide domains. However, their expressive power remains not well understood. Focusing on 2-layer ReLU networks, this paper investigates the impact of equivariance constraints on the expressivity of equivariant and layer-wise equivariant networks. By examining the boundary hyperplanes and the channel vectors of ReLU networks, we construct an example showing that equivariance constraints could strictly limit expressive power. However, we demonstrate that this drawback can be compensated via enlarging the model size. Furthermore, we show that despite a larger model size, the resulting architecture could still correspond to a hypothesis space with lower complexity, implying superior generalizability for equivariant networks.
CoVeR: Conformal Calibration for Versatile and Reliable Autoregressive Next-Token Prediction
Sep 05, 2025
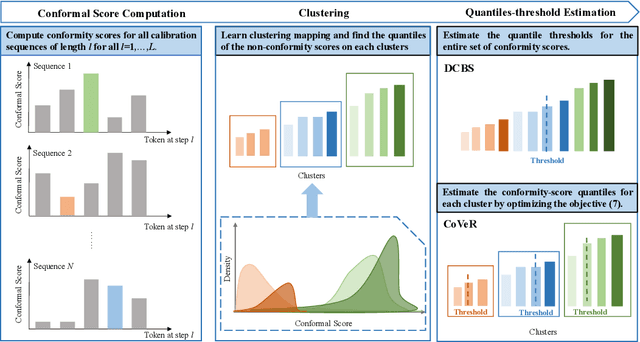
Autoregressive pre-trained models combined with decoding methods have achieved impressive performance on complex reasoning tasks. While mainstream decoding strategies such as beam search can generate plausible candidate sets, they often lack provable coverage guarantees, and struggle to effectively balance search efficiency with the need for versatile trajectories, particularly those involving long-tail sequences that are essential in certain real-world applications. To address these limitations, we propose \textsc{CoVeR}, a novel model-free decoding strategy wihtin the conformal prediction framework that simultaneously maintains a compact search space and ensures high coverage probability over desirable trajectories. Theoretically, we establish a PAC-style generalization bound, guaranteeing that \textsc{CoVeR} asymptotically achieves a coverage rate of at least $1 - \alpha$ for any target level $\alpha \in (0,1)$.
A Theoretical Perspective: How to Prevent Model Collapse in Self-consuming Training Loops
Feb 26, 2025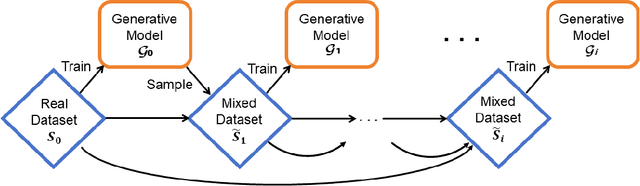
High-quality data is essential for training large generative models, yet the vast reservoir of real data available online has become nearly depleted. Consequently, models increasingly generate their own data for further training, forming Self-consuming Training Loops (STLs). However, the empirical results have been strikingly inconsistent: some models degrade or even collapse, while others successfully avoid these failures, leaving a significant gap in theoretical understanding to explain this discrepancy. This paper introduces the intriguing notion of recursive stability and presents the first theoretical generalization analysis, revealing how both model architecture and the proportion between real and synthetic data influence the success of STLs. We further extend this analysis to transformers in in-context learning, showing that even a constant-sized proportion of real data ensures convergence, while also providing insights into optimal synthetic data sizing.
HRP: High-Rank Preheating for Superior LoRA Initialization
Feb 11, 2025This paper studies the crucial impact of initialization on the convergence properties of Low-Rank Adaptation (LoRA). We theoretically demonstrate that random initialization, a widely used schema, will likely lead LoRA to random low-rank results, rather than the best low-rank result. While this issue can be mitigated by adjusting initialization towards a well-informed direction, it relies on prior knowledge of the target, which is typically unknown in real-world scenarios. To approximate this well-informed initial direction, we propose High-Rank Preheating (HRP), which fine-tunes high-rank LoRA for a few steps and uses the singular value decomposition of the preheated result as a superior initialization. HRP initialization is theory-supported to combine the convergence strengths of high-rank LoRA and the generalization strengths of low-rank LoRA. Extensive experiments demonstrate that HRP significantly enhances LoRA's effectiveness across various models and tasks, achieving performance comparable to full-parameter fine-tuning and outperforming other initialization strategies.
On Championing Foundation Models: From Explainability to Interpretability
Oct 15, 2024Understanding the inner mechanisms of black-box foundation models (FMs) is essential yet challenging in artificial intelligence and its applications. Over the last decade, the long-running focus has been on their explainability, leading to the development of post-hoc explainable methods to rationalize the specific decisions already made by black-box FMs. However, these explainable methods have certain limitations in terms of faithfulness, detail capture and resource requirement. Consequently, in response to these issues, a new class of interpretable methods should be considered to unveil the underlying mechanisms in an accurate, comprehensive, heuristic and resource-light way. This survey aims to review interpretable methods that comply with the aforementioned principles and have been successfully applied to FMs. These methods are deeply rooted in machine learning theory, covering the analysis of generalization performance, expressive capability, and dynamic behavior. They provide a thorough interpretation of the entire workflow of FMs, ranging from the inference capability and training dynamics to their ethical implications. Ultimately, drawing upon these interpretations, this review identifies the next frontier research directions for FMs.