 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
Why Self-Rewarding Works: Theoretical Guarantees for Iterative Alignment of Language Models
Jan 30, 2026Self-Rewarding Language Models (SRLMs) achieve notable success in iteratively improving alignment without external feedback. Yet, despite their striking empirical progress, the core mechanisms driving their capabilities remain unelucidated, leaving a critical gap in theoretical understanding. This paper provides the first rigorous theoretical guarantees for SRLMs. We first establish a lower bound that characterizes the fundamental limits of a single update step, revealing a critical dependence on the quality of the initial model. We then derive finite-sample error bounds for the full iterative paradigm, showing that performance improves at a rate of $\widetilde{\mathcal{O}}\left(1/\sqrt{n}\right)$ with sample size $n$. Crucially, our analysis reveals that the dependence on the initial model decays exponentially with the number of iterations $T$. This provides a formal explanation for why self-rewarding succeeds: it robustly overcomes poor initialization by steering the dynamics toward internal stability and consistency. Finally, we instantiate our theoretical framework for the linear softmax model class, yielding tailored guarantees that connect our high-level insights to practical model architectures.
A Theoretical Perspective: How to Prevent Model Collapse in Self-consuming Training Loops
Feb 26, 2025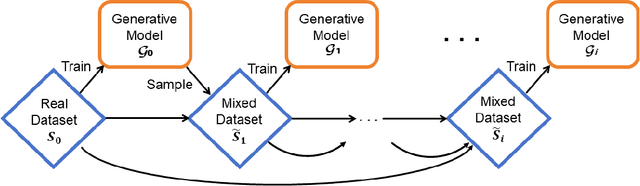
High-quality data is essential for training large generative models, yet the vast reservoir of real data available online has become nearly depleted. Consequently, models increasingly generate their own data for further training, forming Self-consuming Training Loops (STLs). However, the empirical results have been strikingly inconsistent: some models degrade or even collapse, while others successfully avoid these failures, leaving a significant gap in theoretical understanding to explain this discrepancy. This paper introduces the intriguing notion of recursive stability and presents the first theoretical generalization analysis, revealing how both model architecture and the proportion between real and synthetic data influence the success of STLs. We further extend this analysis to transformers in in-context learning, showing that even a constant-sized proportion of real data ensures convergence, while also providing insights into optimal synthetic data sizing.
HRP: High-Rank Preheating for Superior LoRA Initialization
Feb 11, 2025This paper studies the crucial impact of initialization on the convergence properties of Low-Rank Adaptation (LoRA). We theoretically demonstrate that random initialization, a widely used schema, will likely lead LoRA to random low-rank results, rather than the best low-rank result. While this issue can be mitigated by adjusting initialization towards a well-informed direction, it relies on prior knowledge of the target, which is typically unknown in real-world scenarios. To approximate this well-informed initial direction, we propose High-Rank Preheating (HRP), which fine-tunes high-rank LoRA for a few steps and uses the singular value decomposition of the preheated result as a superior initialization. HRP initialization is theory-supported to combine the convergence strengths of high-rank LoRA and the generalization strengths of low-rank LoRA. Extensive experiments demonstrate that HRP significantly enhances LoRA's effectiveness across various models and tasks, achieving performance comparable to full-parameter fine-tuning and outperforming other initialization strategies.
On Championing Foundation Models: From Explainability to Interpretability
Oct 15, 2024Understanding the inner mechanisms of black-box foundation models (FMs) is essential yet challenging in artificial intelligence and its applications. Over the last decade, the long-running focus has been on their explainability, leading to the development of post-hoc explainable methods to rationalize the specific decisions already made by black-box FMs. However, these explainable methods have certain limitations in terms of faithfulness, detail capture and resource requirement. Consequently, in response to these issues, a new class of interpretable methods should be considered to unveil the underlying mechanisms in an accurate, comprehensive, heuristic and resource-light way. This survey aims to review interpretable methods that comply with the aforementioned principles and have been successfully applied to FMs. These methods are deeply rooted in machine learning theory, covering the analysis of generalization performance, expressive capability, and dynamic behavior. They provide a thorough interpretation of the entire workflow of FMs, ranging from the inference capability and training dynamics to their ethical implications. Ultimately, drawing upon these interpretations, this review identifies the next frontier research directions for FMs.
Towards Theoretical Understandings of Self-Consuming Generative Models
Feb 19, 2024
This paper tackles the emerging challenge of training generative models within a self-consuming loop, wherein successive generations of models are recursively trained on mixtures of real and synthetic data from previous generations. We construct a theoretical framework to rigorously evaluate how this training regimen impacts the data distributions learned by future models. Specifically, we derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios. Our analysis demonstrates that this distance can be effectively controlled under the condition that mixed training dataset sizes or proportions of real data are large enough. Interestingly, we further unveil a phase transition induced by expanding synthetic data amounts, proving theoretically that while the TV distance exhibits an initial ascent, it declines beyond a threshold point. Finally, we specialize our general results to diffusion models, delivering nuanced insights such as the efficacy of optimal early stopping within the self-consuming loop.
Detection of (Hidden) Emotions from Videos using Muscles Movements and Face Manifold Embedding
Nov 01, 2022
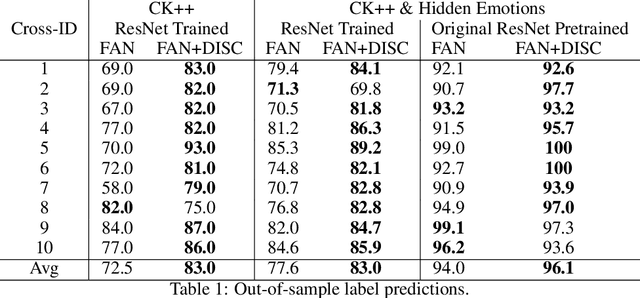
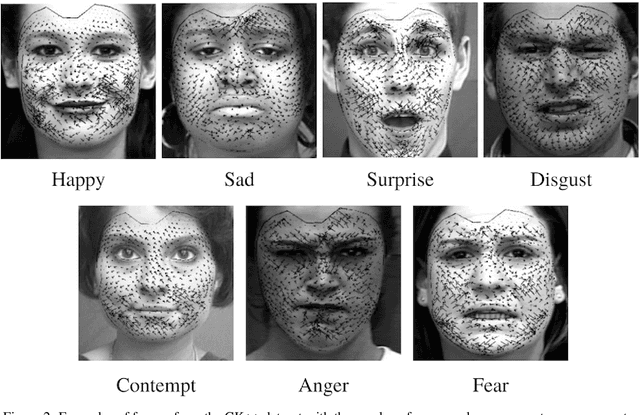
We provide a new non-invasive, easy-to-scale for large amounts of subjects and a remotely accessible method for (hidden) emotion detection from videos of human faces. Our approach combines face manifold detection for accurate location of the face in the video with local face manifold embedding to create a common domain for the measurements of muscle micro-movements that is invariant to the movement of the subject in the video. In the next step, we employ the Digital Image Speckle Correlation (DISC) and the optical flow algorithm to compute the pattern of micro-movements in the face. The corresponding vector field is mapped back to the original space and superimposed on the original frames of the videos. Hence, the resulting videos include additional information about the direction of the movement of the muscles in the face. We take the publicly available CK++ dataset of visible emotions and add to it videos of the same format but with hidden emotions. We process all the videos using our micro-movement detection and use the results to train a state-of-the-art network for emotions classification from videos -- Frame Attention Network (FAN). Although the original FAN model achieves very high out-of-sample performance on the original CK++ videos, it does not perform so well on hidden emotions videos. The performance improves significantly when the model is trained and tested on videos with the vector fields of muscle movements. Intuitively, the corresponding arrows serve as edges in the image that are easily captured by the convolutions filters in the FAN network.