 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Every Image Listens, Every Image Dances: Music-Driven Image Animation
Jan 30, 2025



Image animation has become a promising area in multimodal research, with a focus on generating videos from reference images. While prior work has largely emphasized generic video generation guided by text, music-driven dance video generation remains underexplored. In this paper, we introduce MuseDance, an innovative end-to-end model that animates reference images using both music and text inputs. This dual input enables MuseDance to generate personalized videos that follow text descriptions and synchronize character movements with the music. Unlike existing approaches, MuseDance eliminates the need for complex motion guidance inputs, such as pose or depth sequences, making flexible and creative video generation accessible to users of all expertise levels. To advance research in this field, we present a new multimodal dataset comprising 2,904 dance videos with corresponding background music and text descriptions. Our approach leverages diffusion-based methods to achieve robust generalization, precise control, and temporal consistency, setting a new baseline for the music-driven image animation task.
Mamba Fusion: Learning Actions Through Questioning
Sep 17, 2024



Video Language Models (VLMs) are crucial for generalizing across diverse tasks and using language cues to enhance learning. While transformer-based architectures have been the de facto in vision-language training, they face challenges like quadratic computational complexity, high GPU memory usage, and difficulty with long-term dependencies. To address these limitations, we introduce MambaVL, a novel model that leverages recent advancements in selective state space modality fusion to efficiently capture long-range dependencies and learn joint representations for vision and language data. MambaVL utilizes a shared state transition matrix across both modalities, allowing the model to capture information about actions from multiple perspectives within the scene. Furthermore, we propose a question-answering task that helps guide the model toward relevant cues. These questions provide critical information about actions, objects, and environmental context, leading to enhanced performance. As a result, MambaVL achieves state-of-the-art performance in action recognition on the Epic-Kitchens-100 dataset and outperforms baseline methods in action anticipation.
Hedge Fund Portfolio Construction Using PolyModel Theory and iTransformer
Aug 06, 2024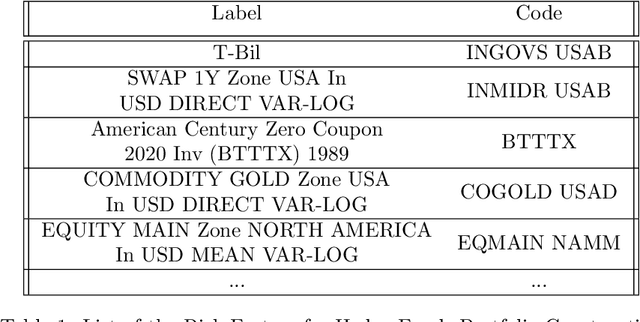
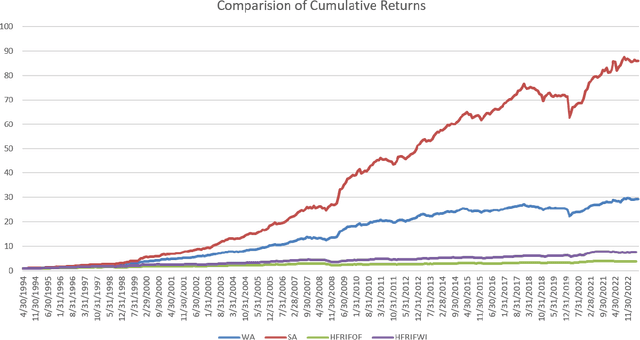
When constructing portfolios, a key problem is that a lot of financial time series data are sparse, making it challenging to apply machine learning methods. Polymodel theory can solve this issue and demonstrate superiority in portfolio construction from various aspects. To implement the PolyModel theory for constructing a hedge fund portfolio, we begin by identifying an asset pool, utilizing over 10,000 hedge funds for the past 29 years' data. PolyModel theory also involves choosing a wide-ranging set of risk factors, which includes various financial indices, currencies, and commodity prices. This comprehensive selection mirrors the complexities of the real-world environment. Leveraging on the PolyModel theory, we create quantitative measures such as Long-term Alpha, Long-term Ratio, and SVaR. We also use more classical measures like the Sharpe ratio or Morningstar's MRAR. To enhance the performance of the constructed portfolio, we also employ the latest deep learning techniques (iTransformer) to capture the upward trend, while efficiently controlling the downside, using all the features. The iTransformer model is specifically designed to address the challenges in high-dimensional time series forecasting and could largely improve our strategies. More precisely, our strategies achieve better Sharpe ratio and annualized return. The above process enables us to create multiple portfolio strategies aiming for high returns and low risks when compared to various benchmarks.
Face-GPS: A Comprehensive Technique for Quantifying Facial Muscle Dynamics in Videos
Jan 11, 2024We introduce a novel method that combines differential geometry, kernels smoothing, and spectral analysis to quantify facial muscle activity from widely accessible video recordings, such as those captured on personal smartphones. Our approach emphasizes practicality and accessibility. It has significant potential for applications in national security and plastic surgery. Additionally, it offers remote diagnosis and monitoring for medical conditions such as stroke, Bell's palsy, and acoustic neuroma. Moreover, it is adept at detecting and classifying emotions, from the overt to the subtle. The proposed face muscle analysis technique is an explainable alternative to deep learning methods and a non-invasive substitute to facial electromyography (fEMG).
MuseChat: A Conversational Music Recommendation System for Videos
Oct 11, 2023



We introduce MuseChat, an innovative dialog-based music recommendation system. This unique platform not only offers interactive user engagement but also suggests music tailored for input videos, so that users can refine and personalize their music selections. In contrast, previous systems predominantly emphasized content compatibility, often overlooking the nuances of users' individual preferences. For example, all the datasets only provide basic music-video pairings or such pairings with textual music descriptions. To address this gap, our research offers three contributions. First, we devise a conversation-synthesis method that simulates a two-turn interaction between a user and a recommendation system, which leverages pre-trained music tags and artist information. In this interaction, users submit a video to the system, which then suggests a suitable music piece with a rationale. Afterwards, users communicate their musical preferences, and the system presents a refined music recommendation with reasoning. Second, we introduce a multi-modal recommendation engine that matches music either by aligning it with visual cues from the video or by harmonizing visual information, feedback from previously recommended music, and the user's textual input. Third, we bridge music representations and textual data with a Large Language Model(Vicuna-7B). This alignment equips MuseChat to deliver music recommendations and their underlying reasoning in a manner resembling human communication. Our evaluations show that MuseChat surpasses existing state-of-the-art models in music retrieval tasks and pioneers the integration of the recommendation process within a natural language framework.
Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering
Oct 10, 2023In recent years, there has been a growing emphasis on the intersection of audio, vision, and text modalities, driving forward the advancements in multimodal research. However, strong bias that exists in any modality can lead to the model neglecting the others. Consequently, the model's ability to effectively reason across these diverse modalities is compromised, impeding further advancement. In this paper, we meticulously review each question type from the original dataset, selecting those with pronounced answer biases. To counter these biases, we gather complementary videos and questions, ensuring that no answers have outstanding skewed distribution. In particular, for binary questions, we strive to ensure that both answers are almost uniformly spread within each question category. As a result, we construct a new dataset, named MUSIC-AVQA v2.0, which is more challenging and we believe could better foster the progress of AVQA task. Furthermore, we present a novel baseline model that delves deeper into the audio-visual-text interrelation. On MUSIC-AVQA v2.0, this model surpasses all the existing benchmarks, improving accuracy by 2% on MUSIC-AVQA v2.0, setting a new state-of-the-art performance.
Detection of (Hidden) Emotions from Videos using Muscles Movements and Face Manifold Embedding
Nov 01, 2022
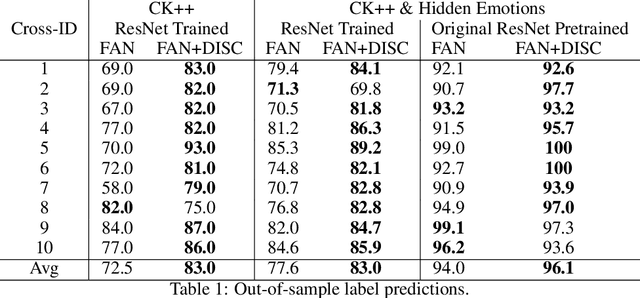
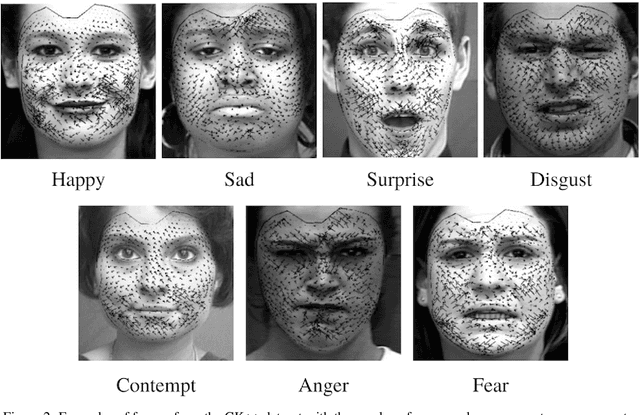
We provide a new non-invasive, easy-to-scale for large amounts of subjects and a remotely accessible method for (hidden) emotion detection from videos of human faces. Our approach combines face manifold detection for accurate location of the face in the video with local face manifold embedding to create a common domain for the measurements of muscle micro-movements that is invariant to the movement of the subject in the video. In the next step, we employ the Digital Image Speckle Correlation (DISC) and the optical flow algorithm to compute the pattern of micro-movements in the face. The corresponding vector field is mapped back to the original space and superimposed on the original frames of the videos. Hence, the resulting videos include additional information about the direction of the movement of the muscles in the face. We take the publicly available CK++ dataset of visible emotions and add to it videos of the same format but with hidden emotions. We process all the videos using our micro-movement detection and use the results to train a state-of-the-art network for emotions classification from videos -- Frame Attention Network (FAN). Although the original FAN model achieves very high out-of-sample performance on the original CK++ videos, it does not perform so well on hidden emotions videos. The performance improves significantly when the model is trained and tested on videos with the vector fields of muscle movements. Intuitively, the corresponding arrows serve as edges in the image that are easily captured by the convolutions filters in the FAN network.
CP-PINNs: Changepoints Detection in PDEs using Physics Informed Neural Networks with Total-Variation Penalty
Aug 18, 2022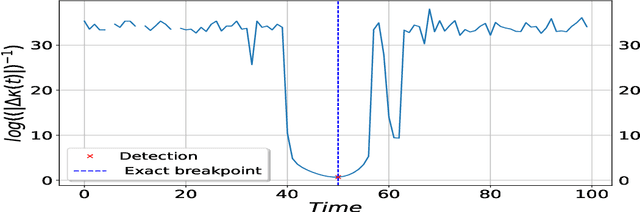
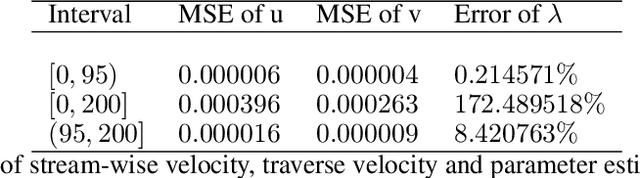
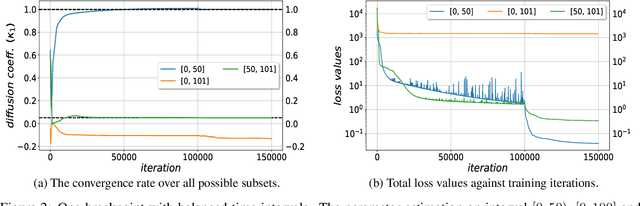
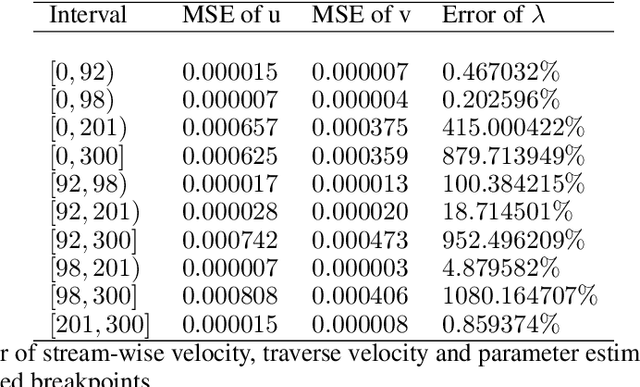
We consider the inverse problem for the Partial Differential Equations (PDEs) such that the parameters of the dependency structure can exhibit random changepoints over time. This can arise, for example, when the physical system is either under malicious attack (e.g., hacker attacks on power grids and internet networks) or subject to extreme external conditions (e.g., weather conditions impacting electricity grids or large market movements impacting valuations of derivative contracts). For that purpose, we employ Physics Informed Neural Networks (PINNs) -- universal approximators that can incorporate prior information from any physical law described by a system of PDEs. This prior knowledge acts in the training of the neural network as a regularization that limits the space of admissible solutions and increases the correctness of the function approximation. We show that when the true data generating process exhibits changepoints in the PDE dynamics, this regularization can lead to a complete miss-calibration and a failure of the model. Therefore, we propose an extension of PINNs using a Total-Variation penalty which accommodates (multiple) changepoints in the PDE dynamics. These changepoints can occur at random locations over time, and they are estimated together with the solutions. We propose an additional refinement algorithm that combines changepoints detection with a reduced dynamic programming method that is feasible for the computationally intensive PINNs methods, and we demonstrate the benefits of the proposed model empirically using examples of different equations with changes in the parameters. In case of no changepoints in the data, the proposed model reduces to the original PINNs model. In the presence of changepoints, it leads to improvements in parameter estimation, better model fitting, and a lower training error compared to the original PINNs model.