 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Inferring Event Descriptions from Time Series with Language Models
Mar 18, 2025Time series data measure how environments change over time and drive decision-making in critical domains like finance and healthcare. When analyzing time series, we often seek to understand the underlying events occurring in the measured environment. For example, one might ask: What caused a sharp drop in the stock price? Events are often described with natural language, so we conduct the first study of whether Large Language Models (LLMs) can infer natural language events from time series. We curate a new benchmark featuring win probabilities collected from 4,200 basketball and American football games, featuring 1.7M timesteps with real value data and corresponding natural language events. Building on the recent wave of using LLMs on time series, we evaluate 16 LLMs and find that they demonstrate promising abilities to infer events from time series data. The open-weights DeepSeek-R1 32B model outperforms proprietary models like GPT-4o. Despite this impressive initial performance, we also find clear avenues to improve recent models, as we identify failures when altering the provided context, event sequence lengths, and evaluation strategy. (All resources needed to reproduce our work are available: https://github.com/BennyTMT/GAMETime)
BLADE: Benchmarking Language Model Agents for Data-Driven Science
Aug 20, 2024Data-driven scientific discovery requires the iterative integration of scientific domain knowledge, statistical expertise, and an understanding of data semantics to make nuanced analytical decisions, e.g., about which variables, transformations, and statistical models to consider. LM-based agents equipped with planning, memory, and code execution capabilities have the potential to support data-driven science. However, evaluating agents on such open-ended tasks is challenging due to multiple valid approaches, partially correct steps, and different ways to express the same decisions. To address these challenges, we present BLADE, a benchmark to automatically evaluate agents' multifaceted approaches to open-ended research questions. BLADE consists of 12 datasets and research questions drawn from existing scientific literature, with ground truth collected from independent analyses by expert data scientists and researchers. To automatically evaluate agent responses, we developed corresponding computational methods to match different representations of analyses to this ground truth. Though language models possess considerable world knowledge, our evaluation shows that they are often limited to basic analyses. However, agents capable of interacting with the underlying data demonstrate improved, but still non-optimal, diversity in their analytical decision making. Our work enables the evaluation of agents for data-driven science and provides researchers deeper insights into agents' analysis approaches.
Are Language Models Actually Useful for Time Series Forecasting?
Jun 22, 2024Large language models (LLMs) are being applied to time series tasks, particularly time series forecasting. However, are language models actually useful for time series? After a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade the forecasting results -- in most cases the results even improved. We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and reveal that patching and attention structures perform similarly to state-of-the-art LLM-based forecasters.
Transforming Wearable Data into Health Insights using Large Language Model Agents
Jun 11, 2024



Despite the proliferation of wearable health trackers and the importance of sleep and exercise to health, deriving actionable personalized insights from wearable data remains a challenge because doing so requires non-trivial open-ended analysis of these data. The recent rise of large language model (LLM) agents, which can use tools to reason about and interact with the world, presents a promising opportunity to enable such personalized analysis at scale. Yet, the application of LLM agents in analyzing personal health is still largely untapped. In this paper, we introduce the Personal Health Insights Agent (PHIA), an agent system that leverages state-of-the-art code generation and information retrieval tools to analyze and interpret behavioral health data from wearables. We curate two benchmark question-answering datasets of over 4000 health insights questions. Based on 650 hours of human and expert evaluation we find that PHIA can accurately address over 84% of factual numerical questions and more than 83% of crowd-sourced open-ended questions. This work has implications for advancing behavioral health across the population, potentially enabling individuals to interpret their own wearable data, and paving the way for a new era of accessible, personalized wellness regimens that are informed by data-driven insights.
Language Models Still Struggle to Zero-shot Reason about Time Series
Apr 17, 2024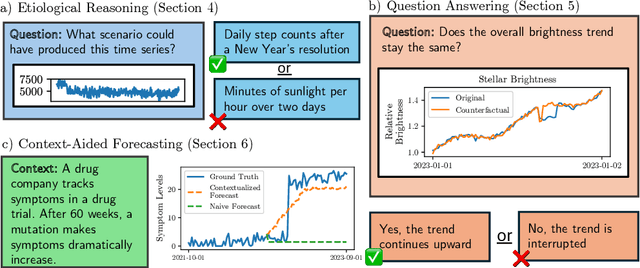
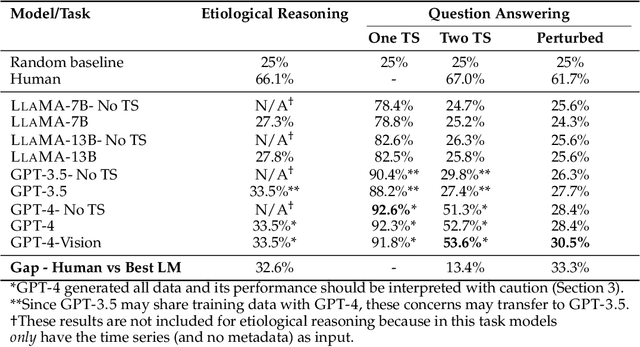

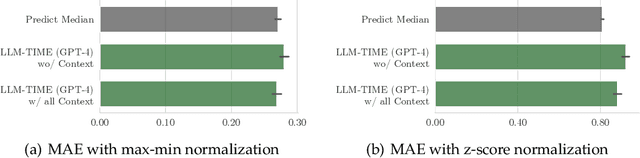
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
Self-supervised Pretraining and Transfer Learning Enable Flu and COVID-19 Predictions in Small Mobile Sensing Datasets
Jun 02, 2022

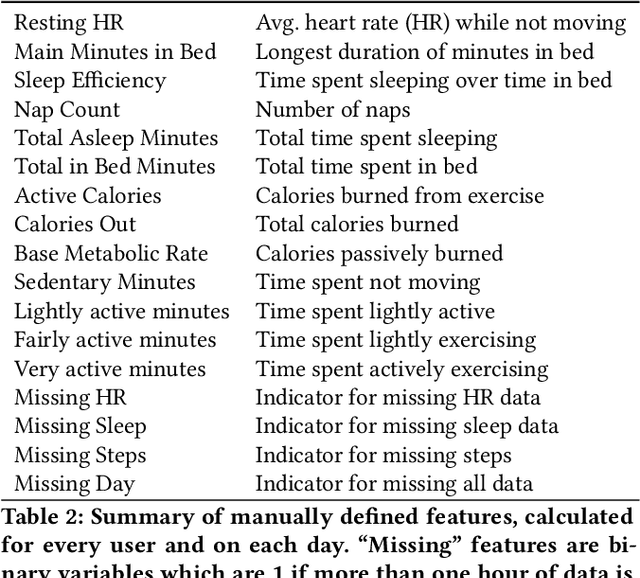
Detailed mobile sensing data from phones, watches, and fitness trackers offer an unparalleled opportunity to quantify and act upon previously unmeasurable behavioral changes in order to improve individual health and accelerate responses to emerging diseases. Unlike in natural language processing and computer vision, deep representation learning has yet to broadly impact this domain, in which the vast majority of research and clinical applications still rely on manually defined features and boosted tree models or even forgo predictive modeling altogether due to insufficient accuracy. This is due to unique challenges in the behavioral health domain, including very small datasets (~10^1 participants), which frequently contain missing data, consist of long time series with critical long-range dependencies (length>10^4), and extreme class imbalances (>10^3:1). Here, we introduce a neural architecture for multivariate time series classification designed to address these unique domain challenges. Our proposed behavioral representation learning approach combines novel tasks for self-supervised pretraining and transfer learning to address data scarcity, and captures long-range dependencies across long-history time series through transformer self-attention following convolutional neural network-based dimensionality reduction. We propose an evaluation framework aimed at reflecting expected real-world performance in plausible deployment scenarios. Concretely, we demonstrate (1) performance improvements over baselines of up to 0.15 ROC AUC across five prediction tasks, (2) transfer learning-induced performance improvements of 16% PR AUC in small data scenarios, and (3) the potential of transfer learning in novel disease scenarios through an exploratory case study of zero-shot COVID-19 prediction in an independent data set. Finally, we discuss potential implications for medical surveillance testing.
Transformer-Based Behavioral Representation Learning Enables Transfer Learning for Mobile Sensing in Small Datasets
Jul 09, 2021

While deep learning has revolutionized research and applications in NLP and computer vision, this has not yet been the case for behavioral modeling and behavioral health applications. This is because the domain's datasets are smaller, have heterogeneous datatypes, and typically exhibit a large degree of missingness. Therefore, off-the-shelf deep learning models require significant, often prohibitive, adaptation. Accordingly, many research applications still rely on manually coded features with boosted tree models, sometimes with task-specific features handcrafted by experts. Here, we address these challenges by providing a neural architecture framework for mobile sensing data that can learn generalizable feature representations from time series and demonstrates the feasibility of transfer learning on small data domains through finetuning. This architecture combines benefits from CNN and Trans-former architectures to (1) enable better prediction performance by learning directly from raw minute-level sensor data without the need for handcrafted features by up to 0.33 ROC AUC, and (2) use pretraining to outperform simpler neural models and boosted decision trees with data from as few a dozen participants.
CORAL: COde RepresentAtion Learning with Weakly-Supervised Transformers for Analyzing Data Analysis
Aug 28, 2020
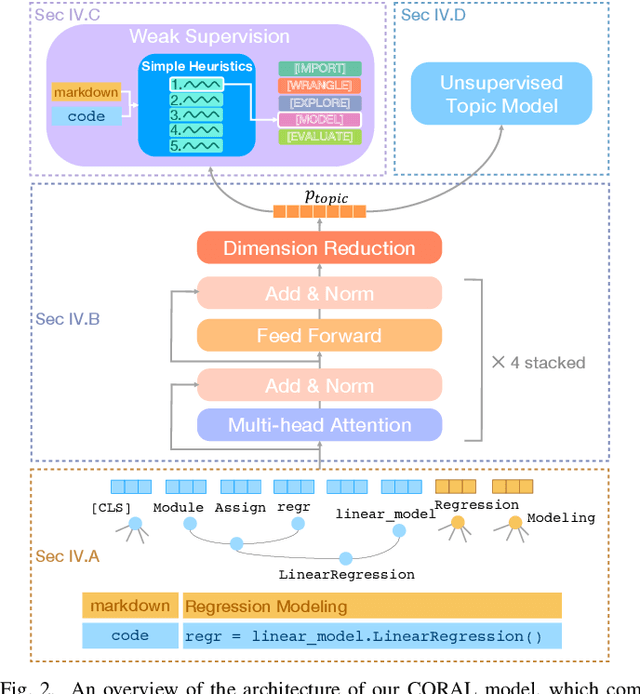
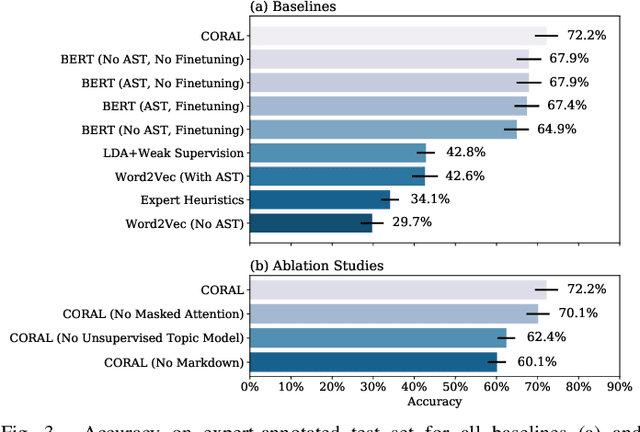

Large scale analysis of source code, and in particular scientific source code, holds the promise of better understanding the data science process, identifying analytical best practices, and providing insights to the builders of scientific toolkits. However, large corpora have remained unanalyzed in depth, as descriptive labels are absent and require expert domain knowledge to generate. We propose a novel weakly supervised transformer-based architecture for computing joint representations of code from both abstract syntax trees and surrounding natural language comments. We then evaluate the model on a new classification task for labeling computational notebook cells as stages in the data analysis process from data import to wrangling, exploration, modeling, and evaluation. We show that our model, leveraging only easily-available weak supervision, achieves a 38% increase in accuracy over expert-supplied heuristics and outperforms a suite of baselines. Our model enables us to examine a set of 118,000 Jupyter Notebooks to uncover common data analysis patterns. Focusing on notebooks with relationships to academic articles, we conduct the largest ever study of scientific code and find that notebook composition correlates with the citation count of corresponding papers.