 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PROPER Approach to Proactivity: Benchmarking and Advancing Knowledge Gap Navigation
Jan 16, 2026Most language-based assistants follow a reactive ask-and-respond paradigm, requiring users to explicitly state their needs. As a result, relevant but unexpressed needs often go unmet. Existing proactive agents attempt to address this gap either by eliciting further clarification, preserving this burden, or by extrapolating future needs from context, often leading to unnecessary or mistimed interventions. We introduce ProPer, Proactivity-driven Personalized agents, a novel two-agent architecture consisting of a Dimension Generating Agent (DGA) and a Response Generating Agent (RGA). DGA, a fine-tuned LLM agent, leverages explicit user data to generate multiple implicit dimensions (latent aspects relevant to the user's task but not considered by the user) or knowledge gaps. These dimensions are selectively filtered using a reranker based on quality, diversity, and task relevance. RGA then balances explicit and implicit dimensions to tailor personalized responses with timely and proactive interventions. We evaluate ProPer across multiple domains using a structured, gap-aware rubric that measures coverage, initiative appropriateness, and intent alignment. Our results show that ProPer improves quality scores and win rates across all domains, achieving up to 84% gains in single-turn evaluation and consistent dominance in multi-turn interactions.
Differentiable Adversarial Attacks for Marked Temporal Point Processes
Jan 17, 2025Marked temporal point processes (MTPPs) have been shown to be extremely effective in modeling continuous time event sequences (CTESs). In this work, we present adversarial attacks designed specifically for MTPP models. A key criterion for a good adversarial attack is its imperceptibility. For objects such as images or text, this is often achieved by bounding perturbation in some fixed $L_p$ norm-ball. However, similarly minimizing distance norms between two CTESs in the context of MTPPs is challenging due to their sequential nature and varying time-scales and lengths. We address this challenge by first permuting the events and then incorporating the additive noise to the arrival timestamps. However, the worst case optimization of such adversarial attacks is a hard combinatorial problem, requiring exploration across a permutation space that is factorially large in the length of the input sequence. As a result, we propose a novel differentiable scheme PERMTPP using which we can perform adversarial attacks by learning to minimize the likelihood, while minimizing the distance between two CTESs. Our experiments on four real-world datasets demonstrate the offensive and defensive capabilities, and lower inference times of PERMTPP.
PaintScene4D: Consistent 4D Scene Generation from Text Prompts
Dec 05, 2024Recent advances in diffusion models have revolutionized 2D and 3D content creation, yet generating photorealistic dynamic 4D scenes remains a significant challenge. Existing dynamic 4D generation methods typically rely on distilling knowledge from pre-trained 3D generative models, often fine-tuned on synthetic object datasets. Consequently, the resulting scenes tend to be object-centric and lack photorealism. While text-to-video models can generate more realistic scenes with motion, they often struggle with spatial understanding and provide limited control over camera viewpoints during rendering. To address these limitations, we present PaintScene4D, a novel text-to-4D scene generation framework that departs from conventional multi-view generative models in favor of a streamlined architecture that harnesses video generative models trained on diverse real-world datasets. Our method first generates a reference video using a video generation model, and then employs a strategic camera array selection for rendering. We apply a progressive warping and inpainting technique to ensure both spatial and temporal consistency across multiple viewpoints. Finally, we optimize multi-view images using a dynamic renderer, enabling flexible camera control based on user preferences. Adopting a training-free architecture, our PaintScene4D efficiently produces realistic 4D scenes that can be viewed from arbitrary trajectories. The code will be made publicly available. Our project page is at https://paintscene4d.github.io/
U2NeRF: Unsupervised Underwater Image Restoration and Neural Radiance Fields
Nov 25, 2024Underwater images suffer from colour shifts, low contrast, and haziness due to light absorption, refraction, scattering and restoring these images has warranted much attention. In this work, we present Unsupervised Underwater Neural Radiance Field U2NeRF, a transformer-based architecture that learns to render and restore novel views conditioned on multi-view geometry simultaneously. Due to the absence of supervision, we attempt to implicitly bake restoring capabilities onto the NeRF pipeline and disentangle the predicted color into several components - scene radiance, direct transmission map, backscatter transmission map, and global background light, and when combined reconstruct the underwater image in a self-supervised manner. In addition, we release an Underwater View Synthesis UVS dataset consisting of 12 underwater scenes, containing both synthetically-generated and real-world data. Our experiments demonstrate that when optimized on a single scene, U2NeRF outperforms several baselines by as much LPIPS 11%, UIQM 5%, UCIQE 4% (on average) and showcases improved rendering and restoration capabilities. Code will be made available upon acceptance.
GANESH: Generalizable NeRF for Lensless Imaging
Nov 07, 2024



Lensless imaging offers a significant opportunity to develop ultra-compact cameras by removing the conventional bulky lens system. However, without a focusing element, the sensor's output is no longer a direct image but a complex multiplexed scene representation. Traditional methods have attempted to address this challenge by employing learnable inversions and refinement models, but these methods are primarily designed for 2D reconstruction and do not generalize well to 3D reconstruction. We introduce GANESH, a novel framework designed to enable simultaneous refinement and novel view synthesis from multi-view lensless images. Unlike existing methods that require scene-specific training, our approach supports on-the-fly inference without retraining on each scene. Moreover, our framework allows us to tune our model to specific scenes, enhancing the rendering and refinement quality. To facilitate research in this area, we also present the first multi-view lensless dataset, LenslessScenes. Extensive experiments demonstrate that our method outperforms current approaches in reconstruction accuracy and refinement quality. Code and video results are available at https://rakesh-123-cryp.github.io/Rakesh.github.io/
GAURA: Generalizable Approach for Unified Restoration and Rendering of Arbitrary Views
Jul 11, 2024Neural rendering methods can achieve near-photorealistic image synthesis of scenes from posed input images. However, when the images are imperfect, e.g., captured in very low-light conditions, state-of-the-art methods fail to reconstruct high-quality 3D scenes. Recent approaches have tried to address this limitation by modeling various degradation processes in the image formation model; however, this limits them to specific image degradations. In this paper, we propose a generalizable neural rendering method that can perform high-fidelity novel view synthesis under several degradations. Our method, GAURA, is learning-based and does not require any test-time scene-specific optimization. It is trained on a synthetic dataset that includes several degradation types. GAURA outperforms state-of-the-art methods on several benchmarks for low-light enhancement, dehazing, deraining, and on-par for motion deblurring. Further, our model can be efficiently fine-tuned to any new incoming degradation using minimal data. We thus demonstrate adaptation results on two unseen degradations, desnowing and removing defocus blur. Code and video results are available at vinayak-vg.github.io/GAURA.
Are Language Models Actually Useful for Time Series Forecasting?
Jun 22, 2024Large language models (LLMs) are being applied to time series tasks, particularly time series forecasting. However, are language models actually useful for time series? After a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade the forecasting results -- in most cases the results even improved. We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and reveal that patching and attention structures perform similarly to state-of-the-art LLM-based forecasters.
Language Models Still Struggle to Zero-shot Reason about Time Series
Apr 17, 2024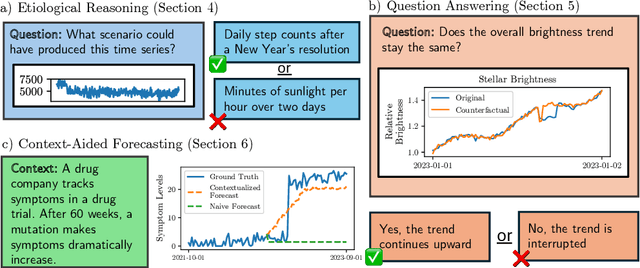
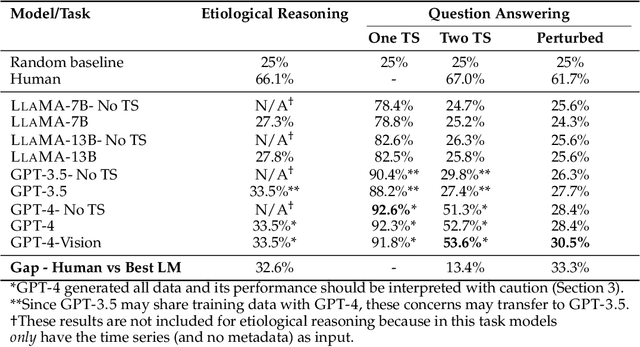

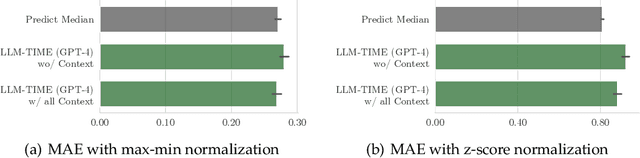
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
SPML: A DSL for Defending Language Models Against Prompt Attacks
Feb 19, 2024



Large language models (LLMs) have profoundly transformed natural language applications, with a growing reliance on instruction-based definitions for designing chatbots. However, post-deployment the chatbot definitions are fixed and are vulnerable to attacks by malicious users, emphasizing the need to prevent unethical applications and financial losses. Existing studies explore user prompts' impact on LLM-based chatbots, yet practical methods to contain attacks on application-specific chatbots remain unexplored. This paper presents System Prompt Meta Language (SPML), a domain-specific language for refining prompts and monitoring the inputs to the LLM-based chatbots. SPML actively checks attack prompts, ensuring user inputs align with chatbot definitions to prevent malicious execution on the LLM backbone, optimizing costs. It also streamlines chatbot definition crafting with programming language capabilities, overcoming natural language design challenges. Additionally, we introduce a groundbreaking benchmark with 1.8k system prompts and 20k user inputs, offering the inaugural language and benchmark for chatbot definition evaluation. Experiments across datasets demonstrate SPML's proficiency in understanding attacker prompts, surpassing models like GPT-4, GPT-3.5, and LLAMA. Our data and codes are publicly available at: https://prompt-compiler.github.io/SPML/.
GSN: Generalisable Segmentation in Neural Radiance Field
Feb 07, 2024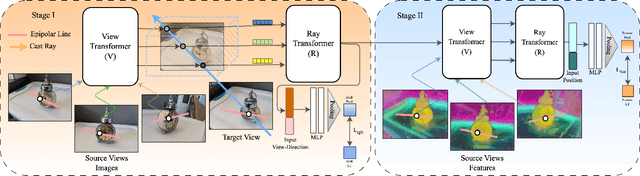
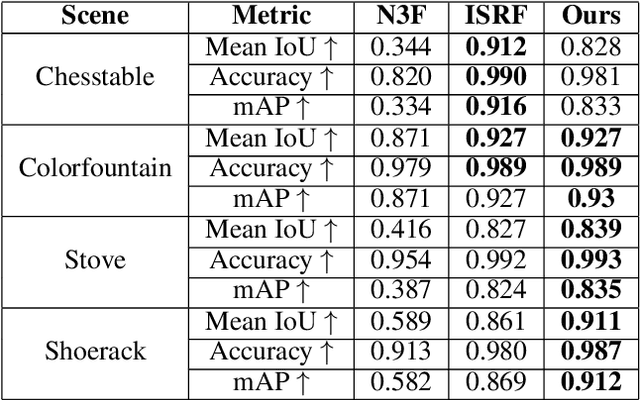


Traditional Radiance Field (RF) representations capture details of a specific scene and must be trained afresh on each scene. Semantic feature fields have been added to RFs to facilitate several segmentation tasks. Generalised RF representations learn the principles of view interpolation. A generalised RF can render new views of an unknown and untrained scene, given a few views. We present a way to distil feature fields into the generalised GNT representation. Our GSN representation generates new views of unseen scenes on the fly along with consistent, per-pixel semantic features. This enables multi-view segmentation of arbitrary new scenes. We show different semantic features being distilled into generalised RFs. Our multi-view segmentation results are on par with methods that use traditional RFs. GSN closes the gap between standard and generalisable RF methods significantly. Project Page: https://vinayak-vg.github.io/GSN/