 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelized Edge Attention: Addressing Semantic Attention Blurring in Temporal Graph Neural Networks
Jan 31, 2026Temporal Graph Neural Networks (TGNNs) aim to capture the evolving structure and timing of interactions in dynamic graphs. Although many models incorporate time through encodings or architectural design, they often compute attention over entangled node and edge representations, failing to reflect their distinct temporal behaviors. Node embeddings evolve slowly as they aggregate long-term structural context, while edge features reflect transient, timestamped interactions (e.g. messages, trades, or transactions). This mismatch results in semantic attention blurring, where attention weights cannot distinguish between slowly drifting node states and rapidly changing, information-rich edge interactions. As a result, models struggle to capture fine-grained temporal dependencies and provide limited transparency into how temporal relevance is computed. This paper introduces KEAT (Kernelized Edge Attention for Temporal Graphs), a novel attention formulation that modulates edge features using a family of continuous-time kernels, including Laplacian, RBF, and learnable MLP variant. KEAT preserves the distinct roles of nodes and edges, and integrates seamlessly with both Transformer-style (e.g., DyGFormer) and message-passing (e.g., TGN) architectures. It achieves up to 18% MRR improvement over the recent DyGFormer and 7% over TGN on link prediction tasks, enabling more accurate, interpretable and temporally aware message passing in TGNNs.
Revisiting the Role of Natural Language Code Comments in Code Translation
Jan 23, 2026The advent of large language models (LLMs) has ushered in a new era in automated code translation across programming languages. Since most code-specific LLMs are pretrained on well-commented code from large repositories like GitHub, it is reasonable to hypothesize that natural language code comments could aid in improving translation quality. Despite their potential relevance, comments are largely absent from existing code translation benchmarks, rendering their impact on translation quality inadequately characterised. In this paper, we present a large-scale empirical study evaluating the impact of comments on translation performance. Our analysis involves more than $80,000$ translations, with and without comments, of $1100+$ code samples from two distinct benchmarks covering pairwise translations between five different programming languages: C, C++, Go, Java, and Python. Our results provide strong evidence that code comments, particularly those that describe the overall purpose of the code rather than line-by-line functionality, significantly enhance translation accuracy. Based on these findings, we propose COMMENTRA, a code translation approach, and demonstrate that it can potentially double the performance of LLM-based code translation. To the best of our knowledge, our study is the first in terms of its comprehensiveness, scale, and language coverage on how to improve code translation accuracy using code comments.
TaxoBell: Gaussian Box Embeddings for Self-Supervised Taxonomy Expansion
Jan 14, 2026Taxonomies form the backbone of structured knowledge representation across diverse domains, enabling applications such as e-commerce catalogs, semantic search, and biomedical discovery. Yet, manual taxonomy expansion is labor-intensive and cannot keep pace with the emergence of new concepts. Existing automated methods rely on point-based vector embeddings, which model symmetric similarity and thus struggle with the asymmetric "is-a" relationships that are fundamental to taxonomies. Box embeddings offer a promising alternative by enabling containment and disjointness, but they face key issues: (i) unstable gradients at the intersection boundaries, (ii) no notion of semantic uncertainty, and (iii) limited capacity to represent polysemy or ambiguity. We address these shortcomings with TaxoBell, a Gaussian box embedding framework that translates between box geometries and multivariate Gaussian distributions, where means encode semantic location and covariances encode uncertainty. Energy-based optimization yields stable optimization, robust modeling of ambiguous concepts, and interpretable hierarchical reasoning. Extensive experimentation on five benchmark datasets demonstrates that TaxoBell significantly outperforms eight state-of-the-art taxonomy expansion baselines by 19% in MRR and around 25% in Recall@k. We further demonstrate the advantages and pitfalls of TaxoBell with error analysis and ablation studies.
CGLE: Class-label Graph Link Estimator for Link Prediction
Nov 10, 2025



Link prediction is a pivotal task in graph mining with wide-ranging applications in social networks, recommendation systems, and knowledge graph completion. However, many leading Graph Neural Network (GNN) models often neglect the valuable semantic information aggregated at the class level. To address this limitation, this paper introduces CGLE (Class-label Graph Link Estimator), a novel framework designed to augment GNN-based link prediction models. CGLE operates by constructing a class-conditioned link probability matrix, where each entry represents the probability of a link forming between two node classes. This matrix is derived from either available ground-truth labels or from pseudo-labels obtained through clustering. The resulting class-based prior is then concatenated with the structural link embedding from a backbone GNN, and the combined representation is processed by a Multi-Layer Perceptron (MLP) for the final prediction. Crucially, CGLE's logic is encapsulated in an efficient preprocessing stage, leaving the computational complexity of the underlying GNN model unaffected. We validate our approach through extensive experiments on a broad suite of benchmark datasets, covering both homophilous and sparse heterophilous graphs. The results show that CGLE yields substantial performance gains over strong baselines such as NCN and NCNC, with improvements in HR@100 of over 10 percentage points on homophilous datasets like Pubmed and DBLP. On sparse heterophilous graphs, CGLE delivers an MRR improvement of over 4% on the Chameleon dataset. Our work underscores the efficacy of integrating global, data-driven semantic priors, presenting a compelling alternative to the pursuit of increasingly complex model architectures. Code to reproduce our findings is available at: https://github.com/data-iitd/cgle-icdm2025.
Learning Sparse Disentangled Representations for Multimodal Exclusion Retrieval
Apr 04, 2025



Multimodal representations are essential for cross-modal retrieval, but they often lack interpretability, making it difficult to understand the reasoning behind retrieved results. Sparse disentangled representations offer a promising solution; however, existing methods rely heavily on text tokens, resulting in high-dimensional embeddings. In this work, we propose a novel approach that generates compact, fixed-size embeddings that maintain disentanglement while providing greater control over retrieval tasks. We evaluate our method on challenging exclusion queries using the MSCOCO and Conceptual Captions benchmarks, demonstrating notable improvements over dense models like CLIP, BLIP, and VISTA (with gains of up to 11% in AP@10), as well as over sparse disentangled models like VDR (achieving up to 21% gains in AP@10). Furthermore, we present qualitative results that emphasize the enhanced interpretability of our disentangled representations.
Exploring the Use of LLMs for SQL Equivalence Checking
Dec 07, 2024Equivalence checking of two SQL queries is an intractable problem encountered in diverse contexts ranging from grading student submissions in a DBMS course to debugging query rewriting rules in an optimizer, and many more. While a lot of progress has been made in recent years in developing practical solutions for this problem, the existing methods can handle only a small subset of SQL, even for bounded equivalence checking. They cannot support sophisticated SQL expressions one encounters in practice. At the same time, large language models (LLMs) -- such as GPT-4 -- have emerged as power generators of SQL from natural language specifications. This paper explores whether LLMs can also demonstrate the ability to reason with SQL queries and help advance SQL equivalence checking. Towards this, we conducted a detailed evaluation of several LLMs over collections with SQL pairs of varying levels of complexity. We explored the efficacy of different prompting techniques, the utility of synthetic examples & explanations, as well as logical plans generated by query parsers. Our main finding is that with well-designed prompting using an unoptimized SQL Logical Plan, LLMs can perform equivalence checking beyond the capabilities of current techniques, achieving nearly 100% accuracy for equivalent pairs and up to 70% for non-equivalent pairs of SQL queries. While LLMs lack the ability to generate formal proofs, their synthetic examples and human-readable explanations offer valuable insights to students (& instructors) in a classroom setting and to database administrators (DBAs) managing large database installations. Additionally, we also show that with careful fine-tuning, we can close the performance gap between smaller (and efficient) models and larger models such as GPT, thus paving the way for potential LLM-integration in standalone data processing systems.
Robust Training of Temporal GNNs using Nearest Neighbours based Hard Negatives
Feb 14, 2024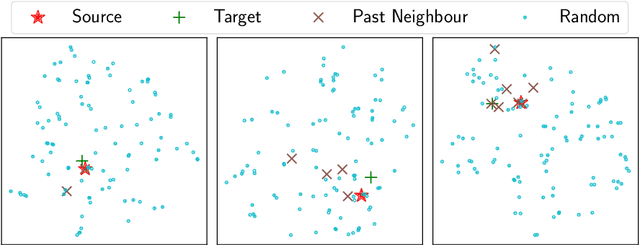

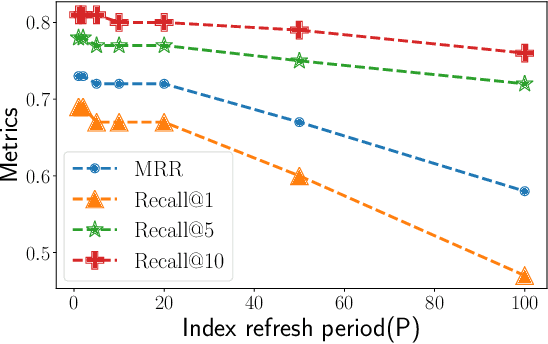
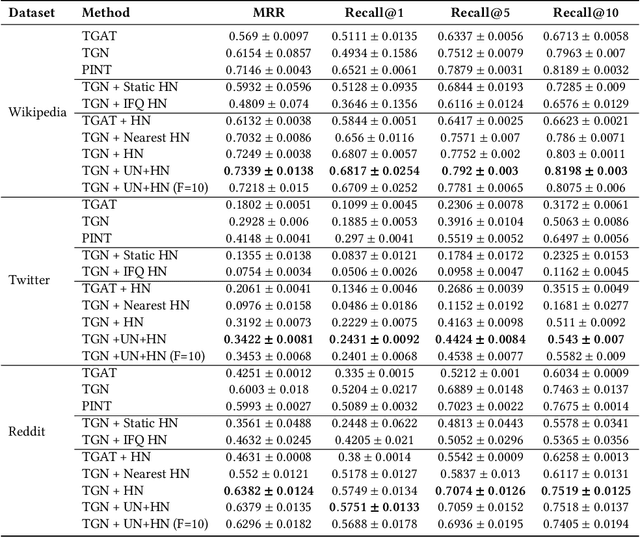
Temporal graph neural networks Tgnn have exhibited state-of-art performance in future-link prediction tasks. Training of these TGNNs is enumerated by uniform random sampling based unsupervised loss. During training, in the context of a positive example, the loss is computed over uninformative negatives, which introduces redundancy and sub-optimal performance. In this paper, we propose modified unsupervised learning of Tgnn, by replacing the uniform negative sampling with importance-based negative sampling. We theoretically motivate and define the dynamically computed distribution for a sampling of negative examples. Finally, using empirical evaluations over three real-world datasets, we show that Tgnn trained using loss based on proposed negative sampling provides consistent superior performance.
Navigating the Structured What-If Spaces: Counterfactual Generation via Structured Diffusion
Dec 21, 2023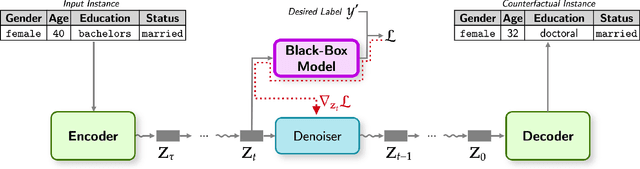
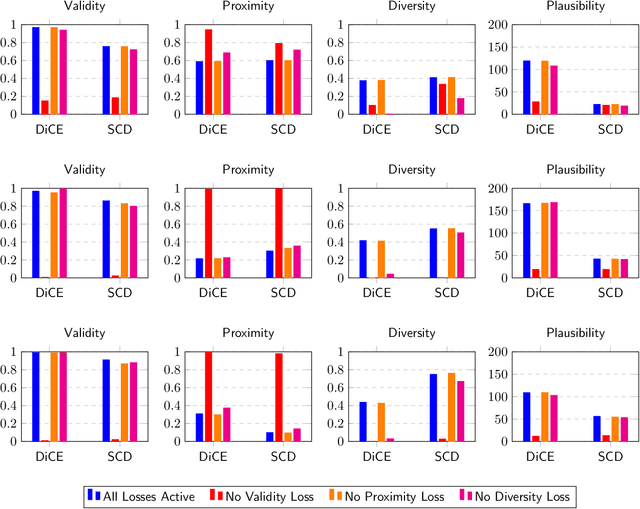
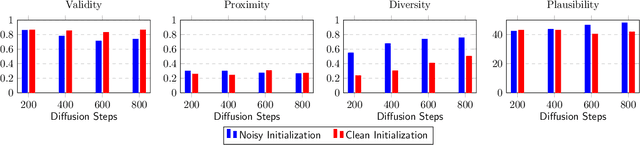
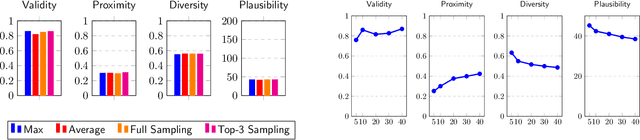
Generating counterfactual explanations is one of the most effective approaches for uncovering the inner workings of black-box neural network models and building user trust. While remarkable strides have been made in generative modeling using diffusion models in domains like vision, their utility in generating counterfactual explanations in structured modalities remains unexplored. In this paper, we introduce Structured Counterfactual Diffuser or SCD, the first plug-and-play framework leveraging diffusion for generating counterfactual explanations in structured data. SCD learns the underlying data distribution via a diffusion model which is then guided at test time to generate counterfactuals for any arbitrary black-box model, input, and desired prediction. Our experiments show that our counterfactuals not only exhibit high plausibility compared to the existing state-of-the-art but also show significantly better proximity and diversity.
Tapestry of Time and Actions: Modeling Human Activity Sequences using Temporal Point Process Flows
Jul 13, 2023Human beings always engage in a vast range of activities and tasks that demonstrate their ability to adapt to different scenarios. Any human activity can be represented as a temporal sequence of actions performed to achieve a certain goal. Unlike the time series datasets extracted from electronics or machines, these action sequences are highly disparate in their nature -- the time to finish a sequence of actions can vary between different persons. Therefore, understanding the dynamics of these sequences is essential for many downstream tasks such as activity length prediction, goal prediction, next action recommendation, etc. Existing neural network-based approaches that learn a continuous-time activity sequence (or CTAS) are limited to the presence of only visual data or are designed specifically for a particular task, i.e., limited to next action or goal prediction. In this paper, we present ProActive, a neural marked temporal point process (MTPP) framework for modeling the continuous-time distribution of actions in an activity sequence while simultaneously addressing three high-impact problems -- next action prediction, sequence-goal prediction, and end-to-end sequence generation. Specifically, we utilize a self-attention module with temporal normalizing flows to model the influence and the inter-arrival times between actions in a sequence. In addition, we propose a novel addition over the ProActive model that can handle variations in the order of actions, i.e., different methods of achieving a given goal. We demonstrate that this variant can learn the order in which the person or actor prefers to do their actions. Extensive experiments on sequences derived from three activity recognition datasets show the significant accuracy boost of ProActive over the state-of-the-art in terms of action and goal prediction, and the first-ever application of end-to-end action sequence generation.
Retrieving Continuous Time Event Sequences using Neural Temporal Point Processes with Learnable Hashing
Jul 13, 2023Temporal sequences have become pervasive in various real-world applications. Consequently, the volume of data generated in the form of continuous time-event sequence(s) or CTES(s) has increased exponentially in the past few years. Thus, a significant fraction of the ongoing research on CTES datasets involves designing models to address downstream tasks such as next-event prediction, long-term forecasting, sequence classification etc. The recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving the CTESs. However, due to the complex nature of these CTES datasets, the task of large-scale retrieval of temporal sequences has been overlooked by the past literature. In detail, by CTES retrieval we mean that for an input query sequence, a retrieval system must return a ranked list of relevant sequences from a large corpus. To tackle this, we propose NeuroSeqRet, a first-of-its-kind framework designed specifically for end-to-end CTES retrieval. Specifically, NeuroSeqRet introduces multiple enhancements over standard retrieval frameworks and first applies a trainable unwarping function on the query sequence which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP-guided neural relevance models. We develop four variants of the relevance model for different kinds of applications based on the trade-off between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing. Our experiments show the significant accuracy boost of NeuroSeqRet as well as the efficacy of our hashing mechanism.