 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is in a name? Mitigating Name Bias in Text Embeddings via Anonymization
Feb 05, 2025Text-embedding models often exhibit biases arising from the data on which they are trained. In this paper, we examine a hitherto unexplored bias in text-embeddings: bias arising from the presence of $\textit{names}$ such as persons, locations, organizations etc. in the text. Our study shows how the presence of $\textit{name-bias}$ in text-embedding models can potentially lead to erroneous conclusions in assessment of thematic similarity.Text-embeddings can mistakenly indicate similarity between texts based on names in the text, even when their actual semantic content has no similarity or indicate dissimilarity simply because of the names in the text even when the texts match semantically. We first demonstrate the presence of name bias in different text-embedding models and then propose $\textit{text-anonymization}$ during inference which involves removing references to names, while preserving the core theme of the text. The efficacy of the anonymization approach is demonstrated on two downstream NLP tasks, achieving significant performance gains. Our simple and training-optimization-free approach offers a practical and easily implementable solution to mitigate name bias.
NeuroSteiner: A Graph Transformer for Wirelength Estimation
Jul 04, 2024A core objective of physical design is to minimize wirelength (WL) when placing chip components on a canvas. Computing the minimal WL of a placement requires finding rectilinear Steiner minimum trees (RSMTs), an NP-hard problem. We propose NeuroSteiner, a neural model that distills GeoSteiner, an optimal RSMT solver, to navigate the cost--accuracy frontier of WL estimation. NeuroSteiner is trained on synthesized nets labeled by GeoSteiner, alleviating the need to train on real chip designs. Moreover, NeuroSteiner's differentiability allows to place by minimizing WL through gradient descent. On ISPD 2005 and 2019, NeuroSteiner can obtain 0.3% WL error while being 60% faster than GeoSteiner, or 0.2% and 30%.
NeuroCUT: A Neural Approach for Robust Graph Partitioning
Oct 18, 2023
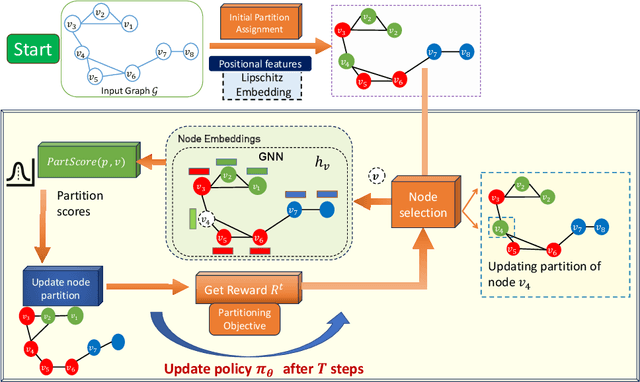
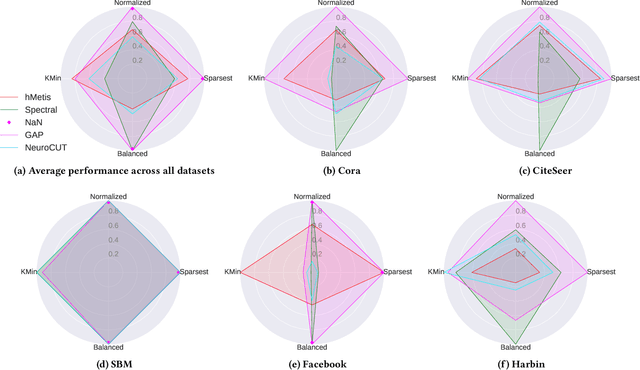
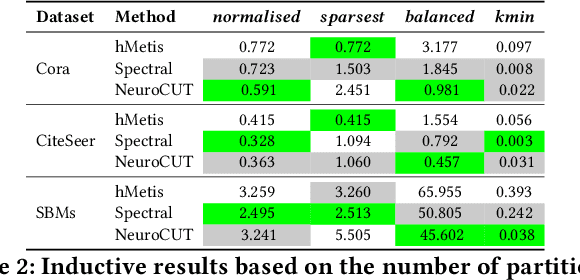
Graph partitioning aims to divide a graph into $k$ disjoint subsets while optimizing a specific partitioning objective. The majority of formulations related to graph partitioning exhibit NP-hardness due to their combinatorial nature. As a result, conventional approximation algorithms rely on heuristic methods, sometimes with approximation guarantees and sometimes without. Unfortunately, traditional approaches are tailored for specific partitioning objectives and do not generalize well across other known partitioning objectives from the literature. To overcome this limitation, and learn heuristics from the data directly, neural approaches have emerged, demonstrating promising outcomes. In this study, we extend this line of work through a novel framework, NeuroCut. NeuroCut introduces two key innovations over prevailing methodologies. First, it is inductive to both graph topology and the partition count, which is provided at query time. Second, by leveraging a reinforcement learning based framework over node representations derived from a graph neural network, NeuroCut can accommodate any optimization objective, even those encompassing non-differentiable functions. Through empirical evaluation, we demonstrate that NeuroCut excels in identifying high-quality partitions, showcases strong generalization across a wide spectrum of partitioning objectives, and exhibits resilience to topological modifications.
Mirage: Model-Agnostic Graph Distillation for Graph Classification
Oct 17, 2023



GNNs, like other deep learning models, are data and computation hungry. There is a pressing need to scale training of GNNs on large datasets to enable their usage on low-resource environments. Graph distillation is an effort in that direction with the aim to construct a smaller synthetic training set from the original training data without significantly compromising model performance. While initial efforts are promising, this work is motivated by two key observations: (1) Existing graph distillation algorithms themselves rely on training with the full dataset, which undermines the very premise of graph distillation. (2) The distillation process is specific to the target GNN architecture and hyper-parameters and thus not robust to changes in the modeling pipeline. We circumvent these limitations by designing a distillation algorithm called Mirage for graph classification. Mirage is built on the insight that a message-passing GNN decomposes the input graph into a multiset of computation trees. Furthermore, the frequency distribution of computation trees is often skewed in nature, enabling us to condense this data into a concise distilled summary. By compressing the computation data itself, as opposed to emulating gradient flows on the original training set-a prevalent approach to date-Mirage transforms into an unsupervised and architecture-agnostic distillation algorithm. Extensive benchmarking on real-world datasets underscores Mirage's superiority, showcasing enhanced generalization accuracy, data compression, and distillation efficiency when compared to state-of-the-art baselines.
GRAFENNE: Learning on Graphs with Heterogeneous and Dynamic Feature Sets
Jun 06, 2023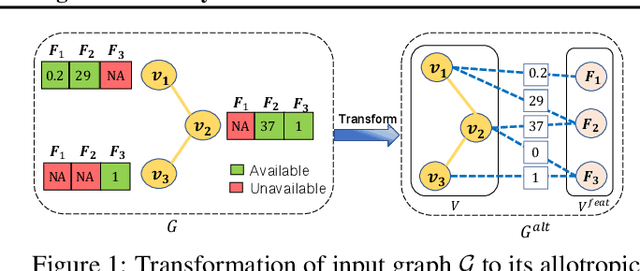
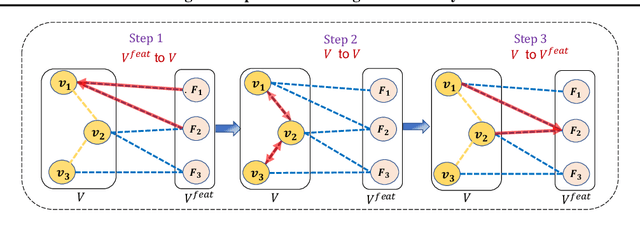
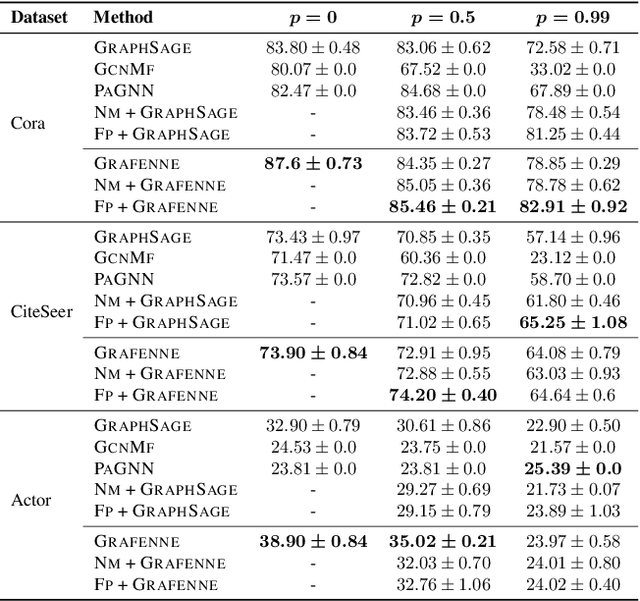
Graph neural networks (GNNs), in general, are built on the assumption of a static set of features characterizing each node in a graph. This assumption is often violated in practice. Existing methods partly address this issue through feature imputation. However, these techniques (i) assume uniformity of feature set across nodes, (ii) are transductive by nature, and (iii) fail to work when features are added or removed over time. In this work, we address these limitations through a novel GNN framework called GRAFENNE. GRAFENNE performs a novel allotropic transformation on the original graph, wherein the nodes and features are decoupled through a bipartite encoding. Through a carefully chosen message passing framework on the allotropic transformation, we make the model parameter size independent of the number of features and thereby inductive to both unseen nodes and features. We prove that GRAFENNE is at least as expressive as any of the existing message-passing GNNs in terms of Weisfeiler-Leman tests, and therefore, the additional inductivity to unseen features does not come at the cost of expressivity. In addition, as demonstrated over four real-world graphs, GRAFENNE empowers the underlying GNN with high empirical efficacy and the ability to learn in continual fashion over streaming feature sets.
GSHOT: Few-shot Generative Modeling of Labeled Graphs
Jun 06, 2023Deep graph generative modeling has gained enormous attraction in recent years due to its impressive ability to directly learn the underlying hidden graph distribution. Despite their initial success, these techniques, like much of the existing deep generative methods, require a large number of training samples to learn a good model. Unfortunately, large number of training samples may not always be available in scenarios such as drug discovery for rare diseases. At the same time, recent advances in few-shot learning have opened door to applications where available training data is limited. In this work, we introduce the hitherto unexplored paradigm of few-shot graph generative modeling. Towards this, we develop GSHOT, a meta-learning based framework for few-shot labeled graph generative modeling. GSHOT learns to transfer meta-knowledge from similar auxiliary graph datasets. Utilizing these prior experiences, GSHOT quickly adapts to an unseen graph dataset through self-paced fine-tuning. Through extensive experiments on datasets from diverse domains having limited training samples, we establish that GSHOT generates graphs of superior fidelity compared to existing baselines.
StriderNET: A Graph Reinforcement Learning Approach to Optimize Atomic Structures on Rough Energy Landscapes
Jan 29, 2023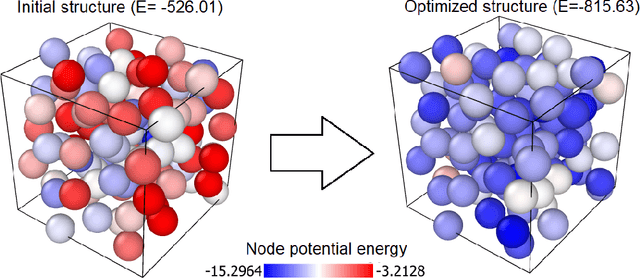
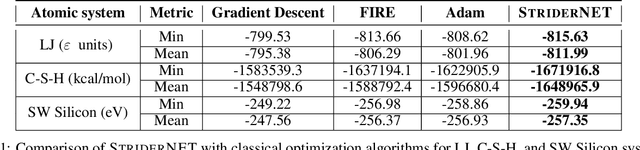
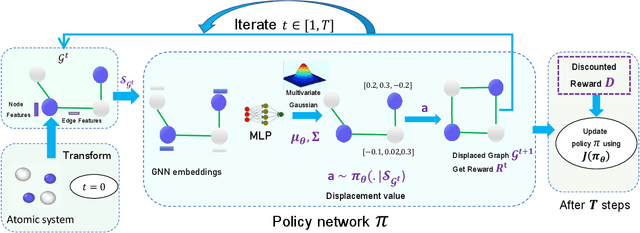

Optimization of atomic structures presents a challenging problem, due to their highly rough and non-convex energy landscape, with wide applications in the fields of drug design, materials discovery, and mechanics. Here, we present a graph reinforcement learning approach, StriderNET, that learns a policy to displace the atoms towards low energy configurations. We evaluate the performance of StriderNET on three complex atomic systems, namely, binary Lennard-Jones particles, calcium silicate hydrates gel, and disordered silicon. We show that StriderNET outperforms all classical optimization algorithms and enables the discovery of a lower energy minimum. In addition, StriderNET exhibits a higher rate of reaching minima with energies, as confirmed by the average over multiple realizations. Finally, we show that StriderNET exhibits inductivity to unseen system sizes that are an order of magnitude different from the training system.
Lifelong Learning for Neural powered Mixed Integer Programming
Aug 26, 2022



Mixed Integer programs (MIPs) are typically solved by the Branch-and-Bound algorithm. Recently, Learning to imitate fast approximations of the expert strong branching heuristic has gained attention due to its success in reducing the running time for solving MIPs. However, existing learning-to-branch methods assume that the entire training data is available in a single session of training. This assumption is often not true, and if the training data is supplied in continual fashion over time, existing techniques suffer from catastrophic forgetting. In this work, we study the hitherto unexplored paradigm of Lifelong Learning to Branch on Mixed Integer Programs. To mitigate catastrophic forgetting, we propose LIMIP, which is powered by the idea of modeling an MIP instance in the form of a bipartite graph, which we map to an embedding space using a bipartite Graph Attention Network. This rich embedding space avoids catastrophic forgetting through the application of knowledge distillation and elastic weight consolidation, wherein we learn the parameters key towards retaining efficacy and are therefore protected from significant drift. We evaluate LIMIP on a series of NP-hard problems and establish that in comparison to existing baselines, LIMIP is up to 50% better when confronted with lifelong learning.
On the Generalization of Neural Combinatorial Optimization Heuristics
Jun 01, 2022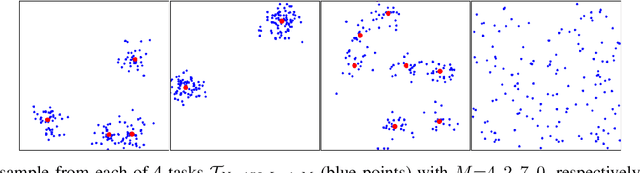


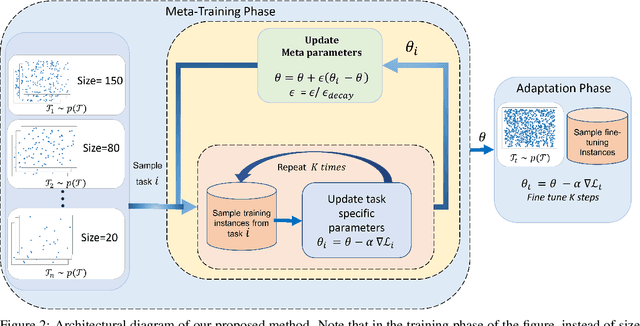
Neural Combinatorial Optimization approaches have recently leveraged the expressiveness and flexibility of deep neural networks to learn efficient heuristics for hard Combinatorial Optimization (CO) problems. However, most of the current methods lack generalization: for a given CO problem, heuristics which are trained on instances with certain characteristics underperform when tested on instances with different characteristics. While some previous works have focused on varying the training instances properties, we postulate that a one-size-fit-all model is out of reach. Instead, we formalize solving a CO problem over a given instance distribution as a separate learning task and investigate meta-learning techniques to learn a model on a variety of tasks, in order to optimize its capacity to adapt to new tasks. Through extensive experiments, on two CO problems, using both synthetic and realistic instances, we show that our proposed meta-learning approach significantly improves the generalization of two state-of-the-art models.
TIGGER: Scalable Generative Modelling for Temporal Interaction Graphs
Mar 08, 2022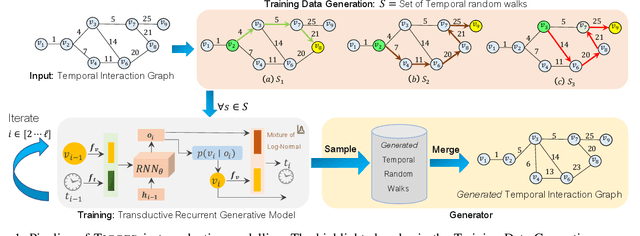



There has been a recent surge in learning generative models for graphs. While impressive progress has been made on static graphs, work on generative modeling of temporal graphs is at a nascent stage with significant scope for improvement. First, existing generative models do not scale with either the time horizon or the number of nodes. Second, existing techniques are transductive in nature and thus do not facilitate knowledge transfer. Finally, due to relying on one-to-one node mapping from source to the generated graph, existing models leak node identity information and do not allow up-scaling/down-scaling the source graph size. In this paper, we bridge these gaps with a novel generative model called TIGGER. TIGGER derives its power through a combination of temporal point processes with auto-regressive modeling enabling both transductive and inductive variants. Through extensive experiments on real datasets, we establish TIGGER generates graphs of superior fidelity, while also being up to 3 orders of magnitude faster than the state-of-the-art.